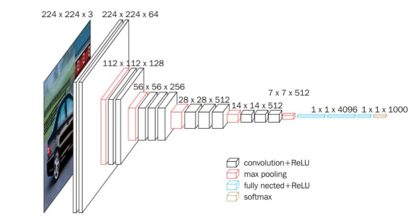
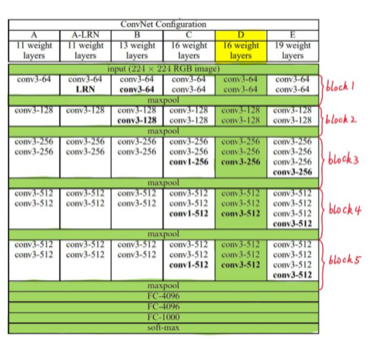
图像数据识别的模型

![图像数据识别的模型[Python常见问题]](https://www.zixueka.com/wp-content/uploads/2023/10/1696830839-53af45146037051.jpg)
模型参数设置与模型构建及训练
from keras.models import Sequential
from keras.layers import Dense, Activation
from keras.callbacks import ModelCheckpoint
model = Sequential()
model.add(Dense(units=64, input_dim=100))
model.add(Activation("relu"))
model.add(Dense(units=64, input_dim=100))
model.add(Activation("softmax"))
#完成模型的搭建后,我们需要使用.compile()方法来编译模型:
model.compile(loss="categorical_croosentropy",metrics=["accuracy"])
model.fit(x_train, y_train, epochs=5, batch_size=32)
loss_and_metrics = model.evaluate(x_test, y_test, batch_size=128)
classes = model.predict(x_test, batch_size=128)
model.save("my_model.h5")
#更改loss函数和优化器
model.compile(loss="binary_crossentropy", optimizer="adam", metrics=["accuracy])
checkpointer = ModelCheckpoint(filepath="checkpoint-{epoch:02d}e-val_acc_{val_acc:2f}.hdf5"
,save_best_only=true, verbose=1, period=50)
model.fit(data,labels, epoch=10,batch_size=32, callbacks=[checkpointer])
#调用Checkpoint保存的model
model = load_model("checkpoint-05e-val_acc_0.58.hdf5")
#模型选取
from keras.application.vgg16 import VGG16
from keras.application.vgg19 import VGG19
from keras.application.inception_v3 import InceptionV3
from keras.application.resnet50 import ResNet50
model_vgg16_conv = VGG16(weights=None, include_top=False, pooling="avg")
output_vgg16_conv = model_vgg16_conv(input)
x = output_vgg16_conv
input = Input(shape=(width,height,channel),name="image_input")
x = Dense(clazz, activation="softmax", name="predictions")(x)
#Create your own model
model = Model(inputs=input, outputs=x)
model.complie(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adam(lr=lr,decay=0),metrics=["acc])
#load all Images
def LoadImageGen(files_data, labels_data,batch=32, label="label"):
start = 0
while start < len(file_data):
stop = start + batch
if stop > len(files_data):
stop = len(file_data)
imgs = []
labels = []
for i in range(start, stop):
imgs.append(LoadImage(file_data[i]))
labels.append(label_data[i])
yield(np.array(imgs),np.array(labels))
if start + batch < len(files_data):
start +=batch
else:
zip_data = list(zip(files_data,labels_data))
random.shuffle(zip_data)
files_data, labels_data = zip(*zip_data)
start=0
# load Images to training model
model.fit_generator(
LoadImageGen(train_x,train_y, batch=batch,label = "train"),
steps_per_epoch=int(len(train_x)/batch),
epochs = epoch,
verbose = 1,
validation_data = LoadImageGen(test_x,test_y, batch=batch,label = "test"),
validation_steps = int(len(test_x)/batch),
callbacks=[
EarlyStopping(monitor="val_acc",patience=patienceEpoch)),
modelCheckpoint
]
)
VGG16:VGG(visual geometry group,超分辨率测试序列)
参考:https://zhuanlan.zhihu.com/p/41423739
共包含13卷积层(Convolutional Layer,表示为conv3-XXXX)+3个连接层(Fully connected Layer,表示为FC-XXXX)+5个池化层(Pool layer,表示maxpool),VGG16的16代表权重系数,maxpool没有权重系数,故16=13+3.