线性数据结构


线性数据结构
线性结构是一个有序数据元素的集合。
常用的线性结构
线性表,栈,队列,双队列,串(一维数组)。
非线性数据结构
关于广义表、数组(高维),是一种非线性的数据结构。
常见的非线性结构有:二维数组,多维数组,广义表,树(二叉树等),图
线性表(线性存储结构)
1、将具有“一对一”关系的数据“线性”地存储到物理空间中,这种存储结构就称为线性存储结构(简称线性表)。
2、使用线性表存储的数据,如同向数组中存储数据那样,要求数据类型必须一致,也就是说,线性表存储的数据,要么全部都是整形,要么全部都是字符串。一半是整形,另一半是字符串的一组数据无法使用线性表存储。
3、将数据依次存储在连续的整块物理空间中,这种存储结构称为顺序存储结构(简称顺序表);数据分散的存储在物理空间中,通过一根线保存着它们之间的逻辑关系,这种存储结构称为链式存储结构(简称链表)
4、某一元素的左侧相邻元素称为“直接前驱”,位于此元素左侧的所有元素都统称为“前驱元素”;某一元素的右侧相邻元素称为“直接后继”,位于此元素右侧的所有元素都统称为“后继元素”
栈
栈又名堆栈,它是一种运算受限的线性表。限定仅在表尾进行插入和删除操作的线性表。这一端被称为栈顶,相对地,把另一端称为栈底。向一个栈插入新元素又称作进栈、入栈或压栈,它是把新元素放到栈顶元素的上面,使之成为新的栈顶元素;从一个栈删除元素又称作出栈或退栈,它是把栈顶元素删除掉,使其相邻的元素成为新的栈顶元素。

单调栈
单调栈中存放的数据应该是有序的,所以单调栈也分为单调递增栈和单调递减栈。
单调递增栈:单调递增栈就是从栈底到栈顶数据是从大到小。
单调递减栈:单调递减栈就是从栈底到栈顶数据是从小到大。
括号序列
括号序列是指由 ‘(’和‘)’ 组成的序列,假如一个括号序列中,包含相同数量的左括号和右括号,并且对于每一个右括号,在它的左侧都有左括号和他匹配,则这个括号序列就是一个合法括号序列,如(())( )就是一个合法括号序列,但(())(( )不是合法括号序列.
空串是合法的括号序列。
若S是合法的括号序列,则(S)是合法的括号序列。
若S和T分别是合法的括号序列,则ST也是合法的括号序列。
队列
队列是一种特殊的线性表,特殊之处在于它只允许在表的前端进行删除操作,而在表的后端进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头。

单调队列
单调队列顾名思义就是一个有规律的队列,这个队列的规律是:所有在队列里的数都必须按递增(或递减)的顺序列队。
单调队列只能解决一个叫滑动窗口的问题。
双端队列
双端队列是一种具有队列和栈性质的数据结构,即可(也只能)在线性表的两端进行插入和删除。

折半搜索(二分)
前缀和
前缀和是一个数组的某项下标之前(包括此项元素)的所有数组元素的和。
差分
差分,一般在大数据里用在以时间为统计维度的分析中,其实就是下一个数值 ,减去上一个数值 。
二维前缀和:b[x,y]=b[x-1,y]+b[x,y-1]-b[x-1,y-1]+a[x,y]
矩阵求和:S(x1,y1,x2,y2)=b[x2,y2]-b[x1-1,y2]-b[x2,y1-1]+b[x1-1,x2-1]
二维差分:b[x,y]=a[x,y]+a[x-1,y-1]-a[x-1,y]-a[x,y-1]
修改矩形[x1,y1,x2,y2]等价于b[x1,y1]+=v,b[x2+1,y2+1]+=v,b[x1,y2+1]-=v,b[x2+1,y1]-=v。
基数排序(松氏基排)
基本解法
第一步
以LSD为例,假设原来有一串数值如下所示:
73, 22, 93, 43, 55, 14, 28, 65, 39, 81
首先根据个位数的数值,在走访数值时将它们分配至编号0到9的桶子中:
0
1 81
2 22
3 73 93 43
4 14
5 55 65
6
7
8 28
9 39
第二步
接下来将这些桶子中的数值重新串接起来,成为以下的数列:
81, 22, 73, 93, 43, 14, 55, 65, 28, 39
接着再进行一次分配,这次是根据十位数来分配:
0
1 14
2 22 28
3 39
4 43
5 55
6 65
7 73
8 81
9 93
第三步
接下来将这些桶子中的数值重新串接起来,成为以下的数列:
14, 22, 28, 39, 43, 55, 65, 73, 81, 93
这时候整个数列已经排序完毕;如果排序的对象有三位数以上,则持续进行以上的动作直至最高位数为止。
LSD的基数排序适用于位数小的数列,如果位数多的话,使用MSD的效率会比较好。MSD的方式与LSD相反,是由高位数为基底开始进行分配,但在分配之后并不马上合并回一个数组中,而是在每个“桶子”中建立“子桶”,将每个桶子中的数值按照下一数位的值分配到“子桶”中。在进行完最低位数的分配后再合并回单一的数组中。
区间算法
区间计算与传统的以数为对象的运算(即点计算)不同,它的运算对象是区间。
由于数字计算机只能使用有限位数表示实数,不能精确表达数学意义上的数值,所以数值的每一步计算都会产生误差。亿万次计算之后,计算机的“舍入规则”效应可能累积相当大的计算误差,导致数值计算结果精度严重损失。而区间计算的整个过程以“区间”为运算对象,提供区间形式的计算结果。这些运算区间在构造上保证包含数据的真实值,使得结果区间也能够保证包含数据运算的真实结果。
O(n)-O(1)
四毛子算法
一种(非常规)分块后暴力预处理以此来优化复杂度的思想。
RMQ
RMQ,即区间最值查询,这是一种在线算法,所谓在线算法,是指用户每次输入一个查询,便马上处理一个查询。RMQ算法一般用较长时间做预处理,时间复杂度为O(nlogn),然后可以在O(1)的时间内处理每次查询。
RMQ标准算法:先规约成LCA(最近公共祖先),再规约成约束RMQ,O(n)-O(q) online。
首先根据原数列,建立笛卡尔树,从而将问题在线性时间内规约为LCA问题。LCA问题可以在线性时间内规约为约束RMQ,也就是数列中任意两个相邻的数的差都是+1或-1的RMQ问题。约束RMQ有O(n)-O(1)的在线解法,故整个算法的时间复杂度为O(n)-O(1)。
哈希表
unordered-map(基于哈希实现的映射)
除留余数法
取关键字被某个不大于散列表表长m的数p除后所得的余数为散列地址。即 H(key) = key MOD p,p<=m。不仅可以对关键字直接取模,也可在折叠、平方取中等运算之后取模。对p的选择很重要,一般取素数或m,若p选的不好,容易产生同义词。
双向平方试判(双平方探测法 )
为了解决二次聚集现象发明了双平方探测法 当冲突产生时 向该冲突点的双向以步长i^2(1 4 9 16 25…) 探测 若保证散列表的长度是素数且满足4K+3则可以遍历整个散列表从而不存在二次聚集现象。
STL
STL 是“Standard
Template Library”的缩写,中文译为“标准模板库”。
#include<algorithm>
#include<bits/stdc++.h>(推荐)
stack栈
queue队列
deque双端队列
priority_queue优先队列(堆)
默认是大根堆,如果想让他是小根堆的话有两种办法,其中一种是重载小于号。

pq.swap(pq2)
vector
向量(Vector)是一个封装了动态大小数组的顺序容器。跟任意其它类型容器一样,它能够存放各种类型的对象。可以简单的认为,向量是一个能够存放任意类型的动态数组。
容器特性:
1.顺序序列
顺序容器中的元素按照严格的线性顺序排序。可以通过元素在序列中的位置访问对应的元素。
2.动态数组
支持对序列中的任意元素进行快速直接访问,甚至可以通过指针算述进行该操作。提供了在序列末尾相对快速地添加/删除元素的操作。
3.能够感知内存分配器的(Allocator-aware)
容器使用一个内存分配器对象来动态地处理它的存储需求。
相当于是个动态数组,每次可以往末端插入一个元素,下标从0开始。
实现方式是每次不够大的时候暴力倍长,可以发现均摊是线性的。

v.size()
这个一个unsigned int类型。也就是说对空的vector的size()-1会得到2^32-1。因此写代码的时候应带尽量避免这种写法。(或者强制类型转化成int)
v.resize()
其复杂度是O(max(1, resize()中的参数-原来的size()))的。
如果是大小变大的resize(),且可以指定新扩展的位置的值。若未指定则调用其默认构造函数,例如int之类的会默认是0。
v.clear()和vector<int>().swap(v)的区别。
前者是假装清空了,实际内存没有被回收。
后者是真的回收了,不过需要和v.size()的大小成正比的时间。
后者的意思是使用vector<>()这句话调用无参的构造函数生成一个vector<>类型的对象,然后和v交换,之后其生存期结束被销毁会自动调用其~vector<>()析构函数。注意<>里面要写v一样的类型(例如int)
set/map
分别是集合/映射
内部使用红黑树(一种平衡树)实现。
同样的当set<>和map<,>中的第一个参数是自定义类型的时候
需要重新定义小于号。
复杂度基本上是O(log(当前大小))
map相当于是一个下标可以是任何数值的数组,如果访问时没有赋值就会返回零。

m[x]
哪怕你什么也不干只写一个m[x];也会新建一个点。
因此当你想知道map中是否存在这个映射的时候最好使用m.count(x)。
很多时候可以有效卡常。
multiset和multimap
是可重集合和可重映射。
有两个注意的:第一个是count函数复杂度变成了O(lg(集合大小)+答案)的,也就是如果有很多相同元素,那么count函数代价很大。
第二个是删除x的话,使用s.erase(x)会把所有权值为x的删除。
如果只想删掉一个需要s.erase(s.find(x))。
unordered_set和unordered_map
基于哈希实现的集合和映射。
基本上里面的类型只能是int,long
long,double这种非自定义类型。 因为其基于哈希)
在c++11及以后存在,之前没有,乱用可能会CE。
空间常数比较大,时间常数不小,比数组访问慢很多,慎用。
不能顺序遍历,不支持lower_bound。
迭代器
只介绍set/map的迭代器。

bitset
高精度压位二进制。
所有时间复杂度是线性的操作,常数都是1/32大概。
下标从0开始。
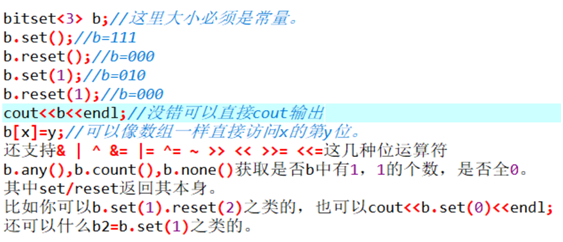
补充
namespace
命名空间,之后写代码长的时候用来避免变量名或者函数名重名的。主要是同一个namespace里面默认使用自己名字空间的东西。
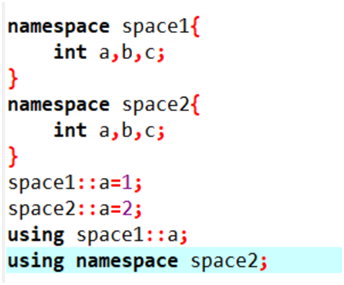
std一般是教师专用账号。
对于107~108的数据,一般运行1s左右。
