C-05goto模拟循环及函数的底层原理

一、goto模拟三种循环
do…while循环:
int n = 1;
int nSum = 0;
do
{
nSum = nSum + n;
n++;
}while(n <= 100);
DO_BEGIN:
nSum = nSum + n;
n++;
if(n <= 100)
{
goto DO_BEGIN;
}
while循环:
int n = 1;
int nSum = 0;
while(n <= 100)
{
nSum = nSum + n;
n++;
}
WHILE_BEGIN:
if(n > 100)
{
goto WHILE_END;
}
nSum = nSum + n;
n++;
goto WHILE_BEGIN;
WHILE_END:
for循环:
for循环三个部分都有的情况
// for循环三个部分都有的情况
for(int n = 1, int nSum = 0; n <= 100; n++)
{
nSum = nSum + n;
}
FOR_INIT:
int n = 1;
int nSum = 0;
goto FOR_CMP;
FOR_STEP:
n++;
FOR_CMP:
if(n > 100)
{
goto FOR_END;
}
nSum = nSum + n;
goto FOR_STEP;
FOR_END:
for循环没有初始化部分的情况
// for循环没有初始化部分的情况
int n = 1;
int nSum = 0;
for(; n <= 100; n++)
{
nSum = nSum + n;
}
FOR_INIT:
goto FOR_CMP;
FOR_STEP:
n++;
FOR_CMP:
if(n > 100)
{
goto FOR_END;
}
nSum = nSum + n;
goto FOR_STEP;
FOR_END:
for循环没有初始化与步长部分的情况
// for循环没有初始化与步长部分的情况,下面这种情况就和while循环一样
int n = 1;
int nSum = 0;
for(; n <= 100;)
{
nSum = nSum + n;
n++;
}
FOR_CMP:
if(n > 100)
{
goto FOR_END;
}
nSum = nSum + n;
n++;
goto FOR_CMP;
FOR_END:
for循环没有判断部分的情况
// for循环没有判断部分的情况
for(int n = 1, int nSum = 0;; n++)
{
if( n > 100)
{
break;
}
nSum = nSum + n;
}
FOR_INIT:
int n = 1;
int nSum = 0;
goto FOR_STRIUCT;
FOR_STEP:
n++;
FOR_STRIUCT: //此处是循环体内的判断
if(n > 100)
{
goto FOR_END;
}
nSum = nSum + n;
goto FOR_STEP;
FOR_END:
总结
- 由此可知
do...while效率最高,正常情况下for循环效率最低。开优化后编译器会将for,while循环转换为do...while循环,提高效率。 - 编译选项
/ZI或/Zi与/O2不能同时有,两个是冲突选项(经过实验,手动编译同时有这两个编译选项,也能编译通过,但是还不知道采用的是那个编译选项) - 汇编语言是流水线模式,也就是循环体的内容是紧接着循环体上面的内容的,而汇编只有满足条件跳转的语义,所以
while,for的判断条件与汇编层面是相反的。例:while(a>b){xx},则在汇编中判断就为if(a <= b) goto WHILE_END {xx}
二、程序运行时内存四大区
wres(内存属性):
- w:
write(可写) - r:
read(可读) - e:
execute(可执行) - s:
share(可共享)
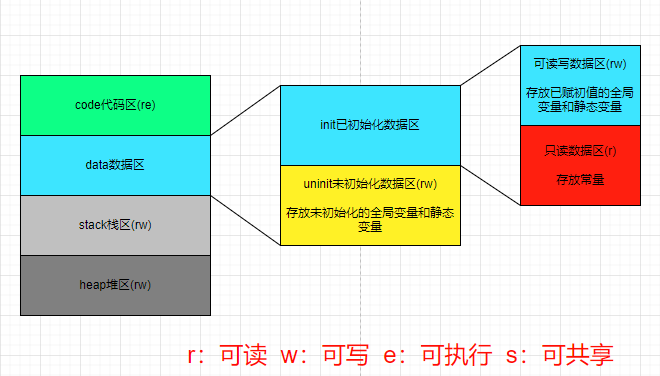
任何操作系统(windows、liunx、安卓、ios等)上的程序在运行时,都有内存四大区,分别为:代码区(code),数据区(data),栈区(stack),堆区(heap)
代码区(code):存放二进制可执行代码,内存属性为re
数据区(data):存放全局变量,静态变量和常量(C语言)
-
init:已初始化数据区:存放已初始化的全局变量和静态变量,还有常量rw:可读写数据区(存放已赋初值的全局变量和静态变量)r:只读数据区(存放常量)
-
uninit:未初始化数据区:存放未初始化的全局变量和静态变量,内存属性为rw
栈区(stack):先进后出,后进先出(类似弹夹),内存属性为rw。经常被翻译为堆栈,其实就是栈区,这是老一辈翻译国外技术书籍时候的一个习惯,喜欢成对成对的用词,而中国传统习惯是后者定性,例:礼无可恕,情有可原。那么你就被放了,没事。如果说 情有可原,礼无可恕,那么你就摊上大事了。再例:牛奶,是奶;奶牛,是牛。所以指针数组是数组,数组指针是指针
堆区(heap):内存属性为rw
三、函数的底层原理
每个函数都有一个属于自己的栈空间,用来记录函数的必要信息
- 按调用约定传参
- 参数的传递方向(是从右向左还是从左向右传参)
- 参数的存储媒介(参数放寄存器还是栈区或者其他)
- 谁负责释放(平衡)参数空间
- 返回值的处理
__cdecl |
__stdcall |
__fastcall |
|
|---|---|---|---|
| 解释 | C调用约定,美国国标标准,默认调用约定 | 标准约定,微软的规定,微软操作系统使用的调用规定,Windows API的标准调用约定 |
快速约定,只有微软某一系列编译器独有的,未标准化,不同编译器可能没有或者实现不一致 |
| 参数传递方式 | 从右往左,通过栈传递 | 从右往左,通过栈传递 | 左数前两个参数放在ecx、edx寄存器中,其余从右往左通过栈传递 |
| 谁清理栈上参数 | 调用者(caller) | 被调者(callee) | 被调者(callee) |
| 编译器参数 | /Gd |
/Gz |
/Gr |
| 可变参 | 支持 | 不支持 | 不支持 |
-
在栈顶保存返回地址
-
保存调用方的栈信息(调用方的栈底位置)
-
更新栈位置(在处理器里)到被调用方的栈底处
-
在栈内开辟局部变量的空间
编译器此时会统计局部变量的大小(占多大空间),然后以此开辟足够空间
调试版开辟的空间大于等于实际局部变量的大小,发行版(优化版)开辟的空间小于等于实际局部变量的大小
使用`/O1`和`/O2`编译选项会根据变量使用情况,会分配小于等于变量大小的空间,例:// 第一种优化情况 // 如果开了优化,编译器不会给局部变量nNum开辟空间 // 而是直接使用 printf("%d",3); int nNum = 3; printf("%d",nNum) // 第二种优化情况 // 根据情况使用寄存器存储变量 编译选项有
/Zi+/Od(调试版且不优化),则填充局部变量空间为0xcc -
保存寄存器环境
-
执行函数体
-
恢复寄存器环境
-
释放局部变量空间
-
恢复栈信息到调用方
-
如果是
__cdecl,先取出返回地址,并按此返回地址作流程更新,抵达新地址后,由调用方清理参数;如果是
__fastcall,__stdcall,先取出返回地址,并清理参数,然后按返回地址作流程更新
四、附加知识
Alt+F8(VC++6.0代码对齐快捷键)- 函数可以通过提供.obj文件或动态链接库给别人使用
- 裸函数不属于调用约定,是一个关键字,让编译器不为此函数生成任何代码的关键字
