mysql基础以及innodb引擎


mysql架构以及innodb架构
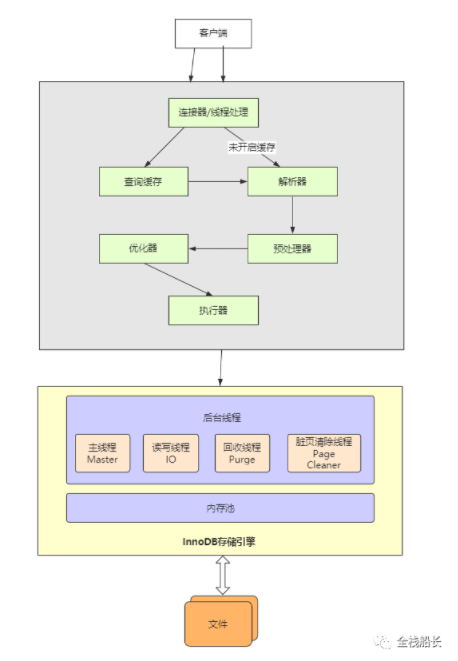
Mysql架构分为Server层和引擎层
Server层
包括 连接器 查询缓存 分析器 优化器 执行器 以及一个binlog日志模块(用于主从同步)
- 查询语句: 分析=>优化=>执行(权限校验)=>引擎
- 更新语句: 分析=>优化=>执行=>引擎=>记录redo log(prepare 状态)=>binlog=>redo log(commit 状态)
引擎层(Innodb)
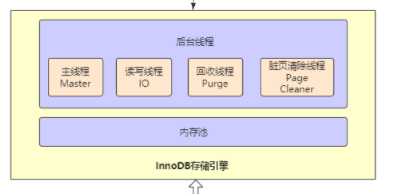
引擎层=用于缓存的内存池 + 后台线程(主要用于刷数据)
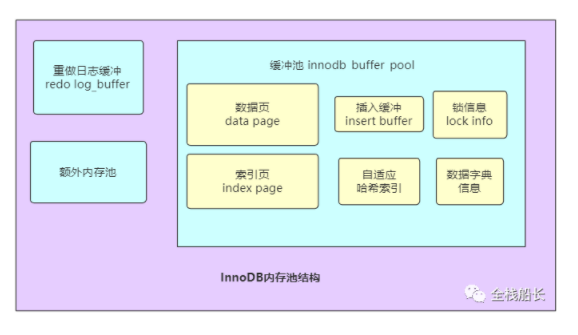
内存池 有用于数据缓冲的缓冲池( 数据页 索引页 插入缓冲 ,…), 还有 redo log 缓冲
后台线程包括(主线程 负责定时刷数据; 读写线程, 回收线程 purge thread=>事务提交后回收undo页), 脏页清除线程Page Cleaner Thread)
不同log文件的区别
redo log:为了持久化数据,当内存中的数据还没写入到磁盘而宕机时,会读取该日志持久化数据到磁盘 (为了恢复已缓存但是未持久化的数据=>引擎自带)
在事务执行过程中一边更新缓冲池中的页面 一遍写入redo log buffer.
持久化的时间=> 1. 引擎的后台线程的主线程会每一秒持久化 2.innodb_flush_log_at_trx_commit参数 0:事务提交不写入 1: 事务提交写入 2:事务提交写入 page cache(文件系统提供)
undo log:事务执行过程中出现错误就会根据该文件恢复事务之前的数据 or MVCC中查找旧版本的数据=>事务提交了就可以回收
binlog:为了复制和恢复数据(两阶段提交)
格式: statement row(保存数据) mixed
事件执行过程中会写入 binlog cache 提交的时候在持久化到硬盘上., 可以通过sync_binlog控制何时持久化.
两阶段提交:
在提交事务前, 每次的redo log的持久化都处于prepare阶段)
提交事务的时候 会持久化binlog 并设置commit阶段回滚事务的时候会判断commit & binlog
索引
聚集索引: 一般使用自增主键 叶子节点存放数据
非聚集索引: 叶子节点存放主键 需要回表查询
非聚集索引一定回表查询吗(覆盖索引)?
联合索引覆盖了要查询的字段
索引sql
CREATE TABLE `class_teacher` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`class_name` varchar(100) COLLATE utf8mb4_unicode_ci NOT NULL,
`teacher_id` int(11) NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_teacher_id` (`teacher_id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci
# 建表的时候添加索引
show index from class_teacher G; #查询索引
drop index "idx_teacher_id" on class_teacher; #删除索引
alter class_teacher add index index2 (teacher_id); #增加索引
数据库建表的范式
1NF: 字段不可再分
2NF: 消除部分依赖( 联合主键)
3NF: 消除传递依赖 (联合表)
数据库并发以及加锁原理
事务的ACID
隔离性和一致性 在并发中 尤为重要
事务的隔离级别
读未提交 读已提交 可重复读 可序列化
(对应的问题: 脏读 不可重复读 幻读)
加锁处理隔离级别(悲观锁)
可以 通过 加行锁 来处理脏读以及 不可重复读的问题 的问题
可以通过 加表锁 来处理幻读
(读写互斥, 读加共享锁 S,写加排他锁 X)
Innodb的对于隔离级别的实现
Innodb使用了MVCC来实现非阻塞的读, 可以认为是行级锁的一个变种, 写操作也只需要锁定必要的行 目的是加快并发. (实际上MVCC是一种乐观锁 数据访问不会排他 加快数据的并发访问)
当前读(锁定读)需要 加锁 一致性非锁定读(快照读) 不需要加锁
MVCC 的实现依赖于:隐藏字段、Read View、undo log。
当前读 锁定读: select .. lock in share mode(S锁) select … for update 和 update(X锁)=> 读完都会锁定
非锁定读 快照读 : select ..
在RC级别下的MVCC:
当前读=>需要加 行锁. 并且 可能操作完成后 需要更新 DB_TRX_ID
快照读=>则 在每一次的读取前生成ReadView( 包含当前活跃事务m_ids (除自身以外) 与 m_low_limit_id,m_up_limit_id等参数), 通过与DB_TRX_ID判断记录可不可见,
通过每一次生成新的readview 保证每次读取到的数据都是已经提交的数据.
在RR级别下的MVCC
快照读=> 在第一次的读取(select) 前生成一个readview 以后一直使用 从而保证了可重复读取
MVCC plus 防止幻读
一句话: MVCC+NEXT-KEY lock 可以处理幻读 但是处理的并不完美 需要手动加锁
Next-Key lock= record 锁+ GAP锁 (锁住当前索引到 两边索引的区间 如果没有索引 变成表锁)
在RR 隔离下, 可以通过执行 select…for update/lock in share mode、insert、update、delete 等当前读 , 从而对读取到的记录以及两边的区间加next-key lock来阻塞其他的事务插入数据. (阻塞很影响效率)
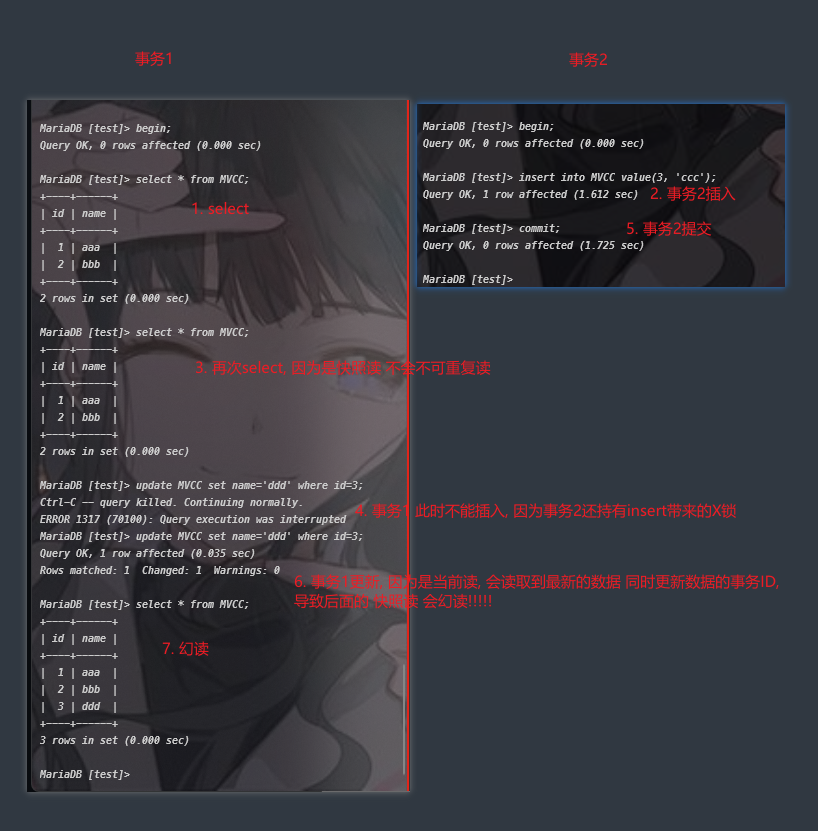
或者 不手动加锁 保证事务只使用快照读, 但是 如果 本事务 使用了update等(当前读) 修改了其他事务插入的行的DB_TRX_ID为 自身 会导致 幻行 出现.
实验
- 加锁 防止换行
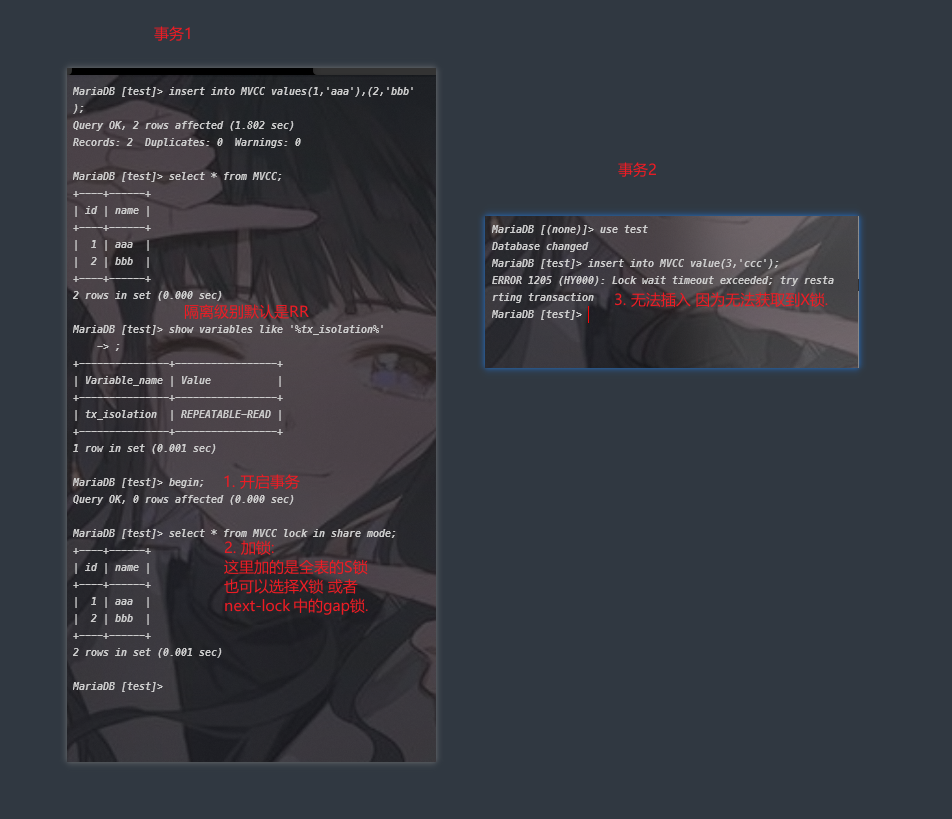
- 不加锁 使用快照读 不会阻塞, 但是其他线程使用update等当前读之后 会修改DB_TRX_ID 导致幻读
参考
https://javaguide.cn/database/mysql/innodb-implementation-of-mvcc/#undo-log
https://www.modb.pro/db/62503
https://tech.meituan.com/2014/08/20/innodb-lock.html
