python 爬虫 中的正则表达式


正则表达式虽然不是python语言,但在python爬虫中却有着普遍的应用,可以说没有正则表达式的爬虫是一个没有灵魂的爬虫,话不多说,直接上干货!
首先介绍一个验证正则表达式的在线平台:https://regex101.com/
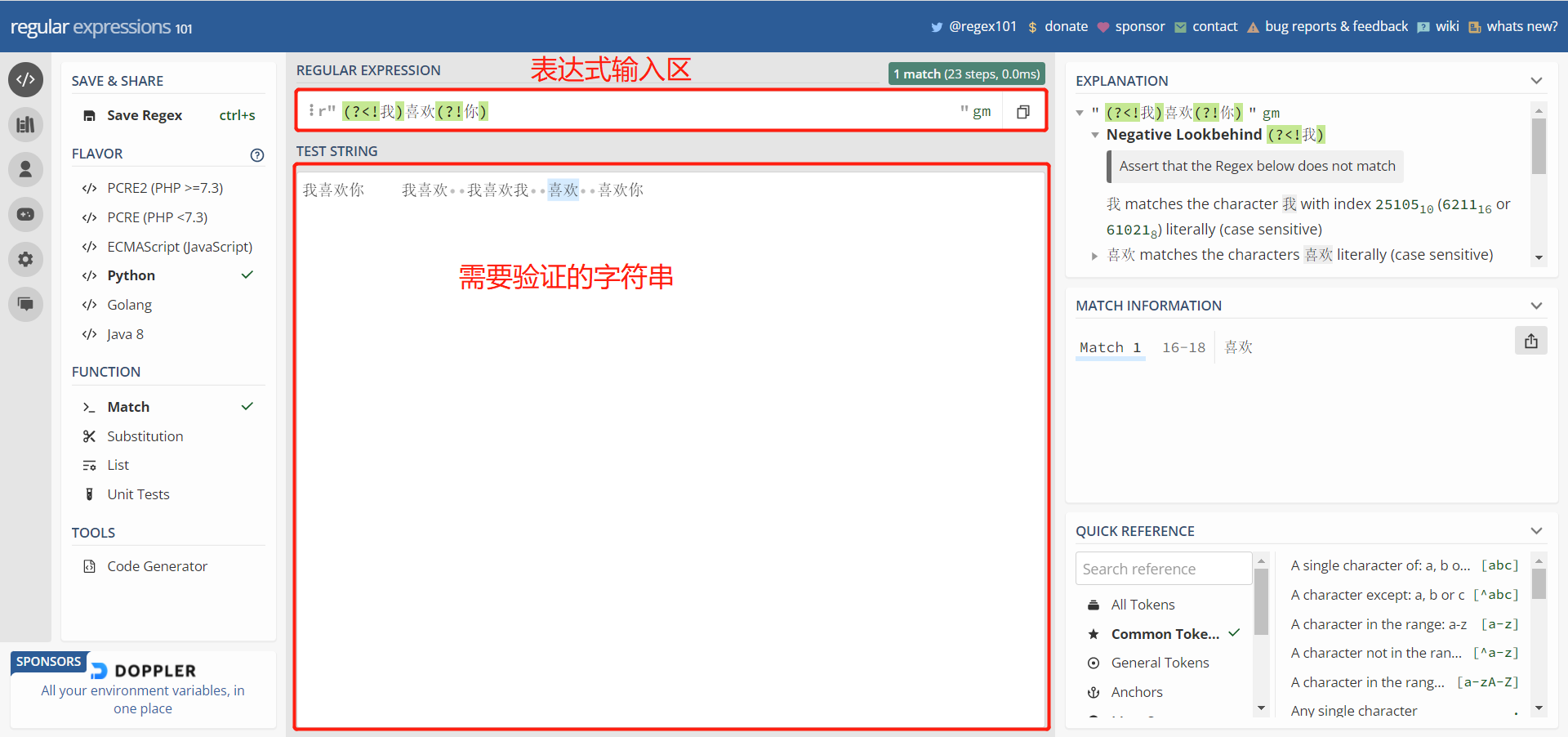
高亮部分即为提取到的内容。
-
元字符
- d 匹配所有数字
- w 匹配所有数字、字母、下划线
- D 除了数字以外的内容
- W 除了数字、字母、下划线以外的内容
- S 匹配所有非空白
- [a,b,c] 匹配a,b,c的内容
- [^a,b,c] 匹配除了a,b,c的内容
- s 匹配空白
- 匹配单个单词边界
-
量词
- 元字符+ 元字符出现1次或多次(等同于{1, })
- 元字符* 前面的元字符出现0次或多次,尽可能多的拿到数据(等同于{0, })
- 元字符? 前面的元字符出现0次或一次
-
匹配字符
- 数字 [0-9]
- 小写字母 [a-z]
- 大写字母 [A-Z]
- 特殊字符 [特殊字符]
-
^
- 放在区间里表示取反
- [^0-9] 表示匹配非数字
- [^a-z] 表示匹配非小写字母
- 放在区间外面表示匹配字符串开头(^python 表示以python开头的内容)
- 放在区间里表示取反
- $ 匹配字符串结尾(python$ 表示以python结尾的单词)
- ?
- 可以出现也可以不出现(colou?r 可以同时匹配color、colour)
- 转换为非贪婪模式(d{8,9}? 默认会匹配8和9位的数字,加上?后,只匹配8位的数字)
- . 除了换行符以外的任意内容
- {数字} 指定匹配次数(d{9}指匹配9位数的数字)
- {数字,数字} 指定匹配区间(d{4, }指匹配4位以上的数字)
-
惰性匹配
- .* 匹配最远的字符
- .*? 匹配最近的字符(惰性匹配)
- 字符串:今天晚上一起吃鸡呀(匹配:晚上.*?吃鸡) 结果:晚上一起吃鸡
-
分组
- 加括号就可分组(提取号码:0731-8283333的区号和正真的电话号码 结果:d{4}-d{7})
- eg:<div>holle</div> <div>(.*?)</div> 不加括号是提取不出来的
- | 或则条件 (.jpg|.gif|.jpeg|.png)表示匹配这几种后缀的图片格式
- 非捕获分组 (?:表达式)
-
分组的回溯引用
- 提取标签中的文字 <font>提示</font>ge1:破坏标签,将</font>改为</br>结果:<(w+)>(.*?)</1> 1 就为了保证和第一个分组一致
- eg2:编写代码匹配符合ab ba 结果:(w)(w)21
- 环视/欲搜索
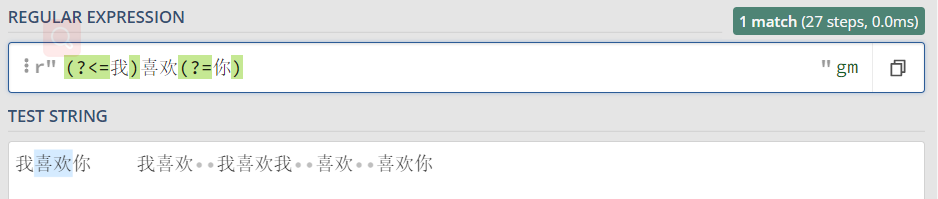
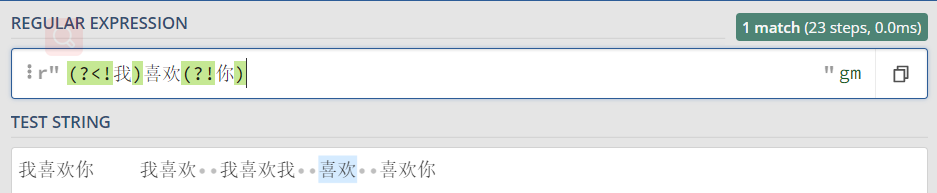
eg:在 我喜欢你 我喜欢 我喜欢我 喜欢 喜欢你
正向先行断言(?=表达式) 取出喜欢,喜欢的后面必须有”你“
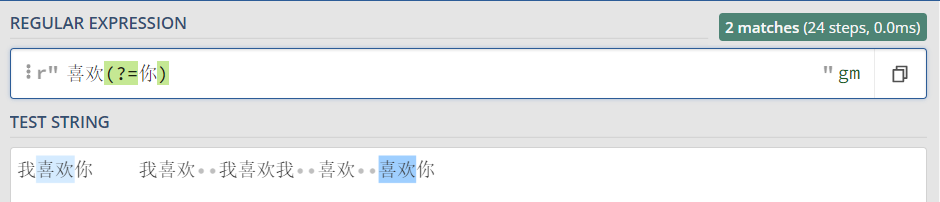
反向先行断言 喜欢(?!你) 即喜欢后面没有”你“
正向后行断言(?<=我)喜欢(?=你) 喜欢的前面右”我“,后面有”你“
反向后行断言(?<!我)喜欢(?!你) 喜欢的前面没有我,后面没有你
本文均自己整理,时间也比较赶,可能有的地方会存在问题,可以评论留言,看到了就会改。
