InnoDB学习(八)之 聚簇索引


InnoDB中,表数据文件本身就是以主键为索引的B+树,树的叶子节点存放一条条表数据,此索引树被称为表的聚簇索引。聚簇索引也称为聚集索引,聚类索引,簇集索引,聚簇索引确定表中数据的物理顺序。
InnoDB聚簇索引
InnoDB表主键
InnoDB中每张表都会有一个主键,表中的每一行数据都是按照主键的顺序在聚簇索引中存储的,InnoDB中有两种方式确定一行数据的主键:
- 显式声明:用户可以在建表的时候通过
primary key关键字来声明主键列; - 唯一索引:如果用户没有声明主键列,那么InnoDB会使用第一个非空唯一列作为主键;
- 自动生成:如果满足以上两种条件的列都不存在,那么InnoDB会将RowId作为主键;
聚簇索引示例
首先我们在数据库中建立一张用户表,包含用户ID、姓名、性别、年龄四个字段:
create table user_info
(
id int primary key,
age int not null,
name varchar(16),
sex bool
)engine=InnoDB;
向数据库中插入如下数据:
| 用户ID | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 姓名 | 陈尔 | 张散 | 李思 | 王舞 | 赵流 | 孙期 | 周跋 | 吴酒 | 郑史 |
| 性别 | 男 | 男 | 女 | 女 | 男 | 男 | 男 | 女 | 男 |
| 年龄 | 5 | 10 | 20 | 28 | 35 | 56 | 25 | 80 | 90 |
上述表中插入指定数据后,得到的聚簇索引结构如下所示:
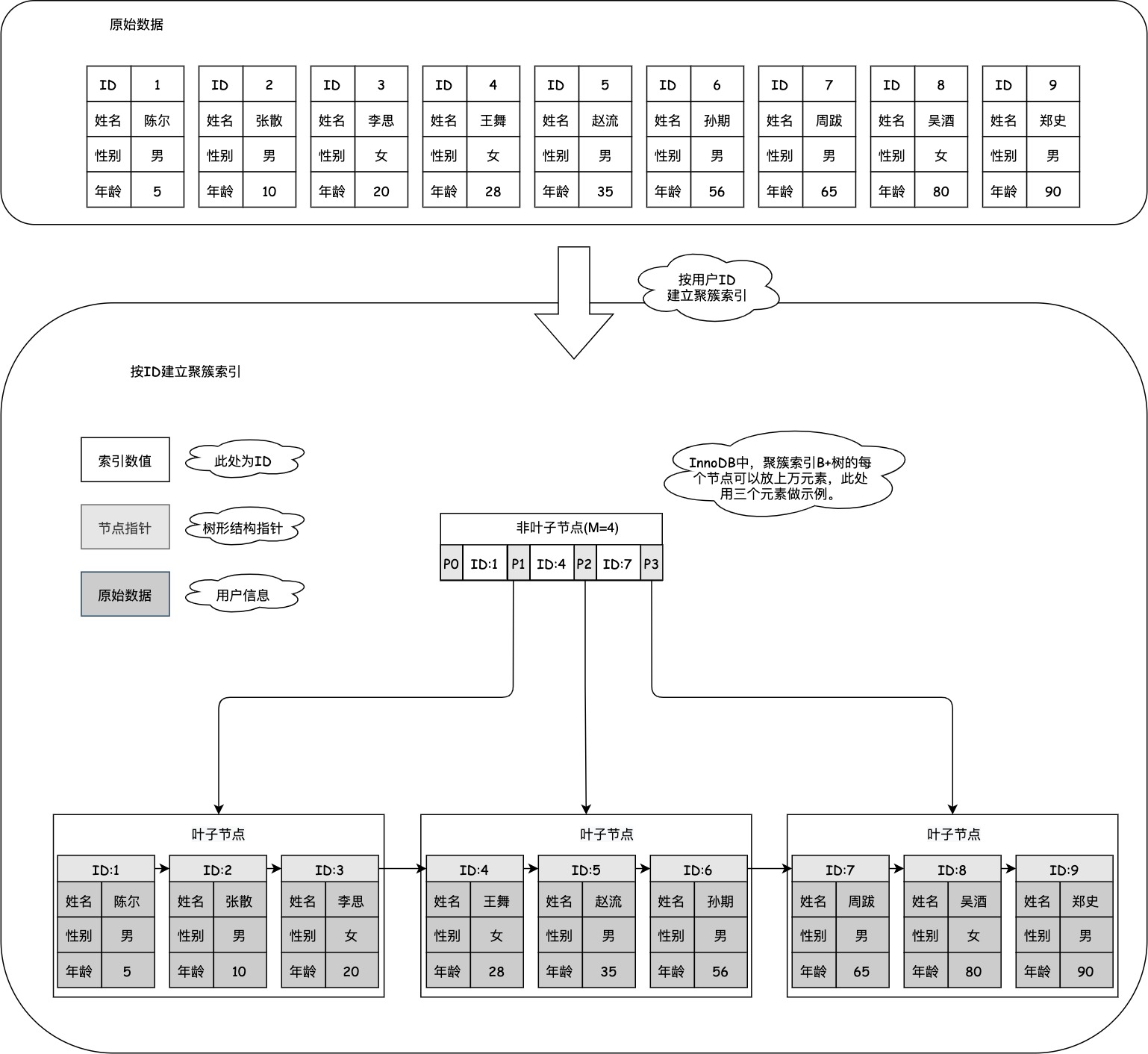
可以看到,聚簇索引的叶子节点包含了所有数据,所以在需要查询某一行数据的所有列时,通过聚簇索引查询的效率最高。
非聚簇索引
InnoDB中,除了聚簇索引以外,其余的索引都可以称为非聚簇索引,非聚簇索引的叶子节点存放主键索引,而不是所有数据。通过非聚簇索引查找数据,其流程是先通过非聚簇索引查找到数据的主键,再通过主键查找对应的数据。
对于上文中的用户表,我们稍微修改一下建表语句,对用户的年龄添加索引:
create table user_info
(
id int primary key,
age int not null,
name varchar(16),
sex bool,
key(age)
)engine=InnoDB;
向表中插入和上文中相同的数据,InnoDB会为这张表生成两个索引树:用户ID对应的聚簇索引树和用户年龄对应的非聚簇索引树,其结构如下图所示。
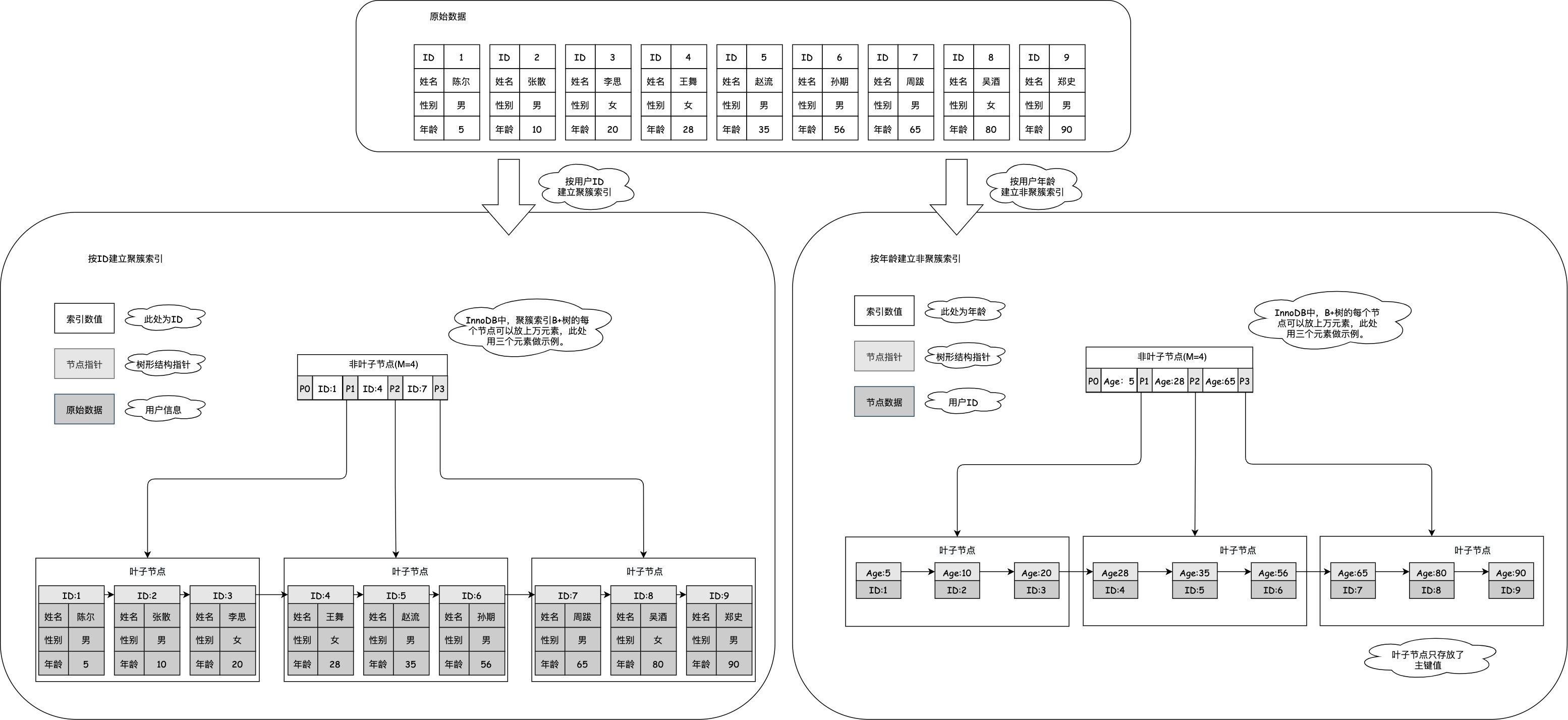
从图中可以发现,聚簇索引和非聚簇索引最大的区别就是叶子节点存放的内容,聚簇索引的叶子节点存放了数据库一行中的所有数据,而非聚簇索引的叶子节点存放了数据的主键。
大多数情况下,通过非聚簇索引查找到主键值后,还需要通过主键值去聚簇索引查找整行数据,从而获取到满足条件行的所有数据。所以非聚簇索引的查询速度总是会比聚簇索引的查询速度慢一些,日常开发中能使用聚簇索引应该尽量使用聚簇索引。
回表查询
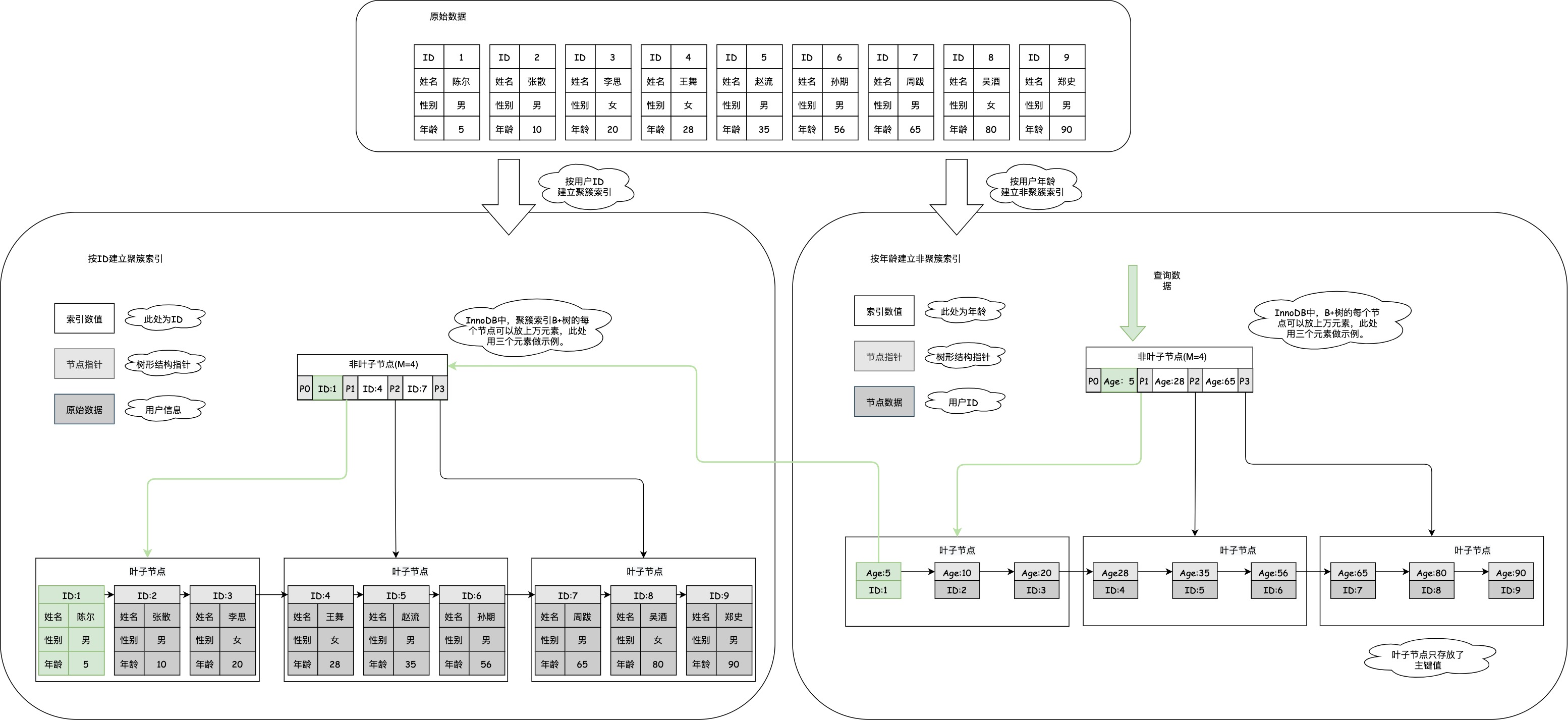
所谓的回表查询,就是指通过非聚簇索引查询数据时,可能需要回到聚簇索引多查询一次数据的情况,对于上文中的数据,执行以下SQL语句,其查询过程如下图中的绿色路径所示。
从图中可以看到,在用户年龄的索引树的叶子节点中,包含了用户的主键ID,由于我们需要获取用户的所有信息,所以还需要按照用户的ID去聚簇索引查找用户的所有信息。
select * from user_info where age = 5;
覆盖索引
如果某次查询的过程中,查询需要的数据在非聚簇索引中就可以得到,那么就没有必要回到聚簇索引查询行所有的数据,这种情况称为覆盖索引。我们可以把上面回表查询的SQL修改为:
select id from user_info where age = 5;
由于年龄索引树的叶子节点就包含了ID信息,所以InnoDB不需要回聚簇索引再次查询用户ID,而是直接将年龄索引树中的ID返回。

本文最先发布至微信公众号,版权所有,禁止转载!
