InnoDB学习(二)之ChangeBuffer


ChangeBuffer是InnoDB缓存区的一种特殊的数据结构,当用户执行SQL对非唯一索引进行更改时,如果索引对应的数据页不在缓存中时,InnoDB不会直接加载磁盘数据到缓存数据页中,而是缓存对这些更改操作。这些更改操作可能由插入、更新或删除操作(DML)触发。缓存区的更改操作会在磁盘数据被其它读操作加载到缓存中时合并到对应的缓存数据页中。
ChangeBuffer
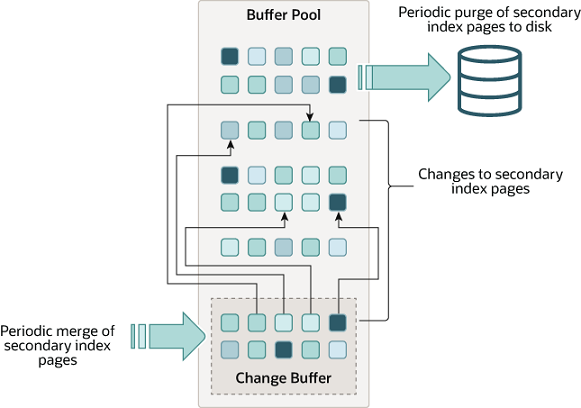
InnoDB ChangeBuffer的官方示意图如下所示,从图中可以看出以下信息:
- ChangeBuffer用于存储SQL变更操作,比如Insert/Update/Delete等SQL语句;
- ChangeBuffer中的每个变更操作都有其对应的数据页,并且该数据页未加载到缓存中;
- 当ChangeBufferd中变更操作对应的数据页加载到缓存中后,InnoDB会把变更操作Merge到数据页上;
- InnoDB会定期加载ChangeBuffer中操作对应的数据页到缓存中,并Merge变更操作;
基于个人理解并参考官方的ChangeBuffer示例图,我绘制了以下更为直观的的ChangeBuffer示例图:
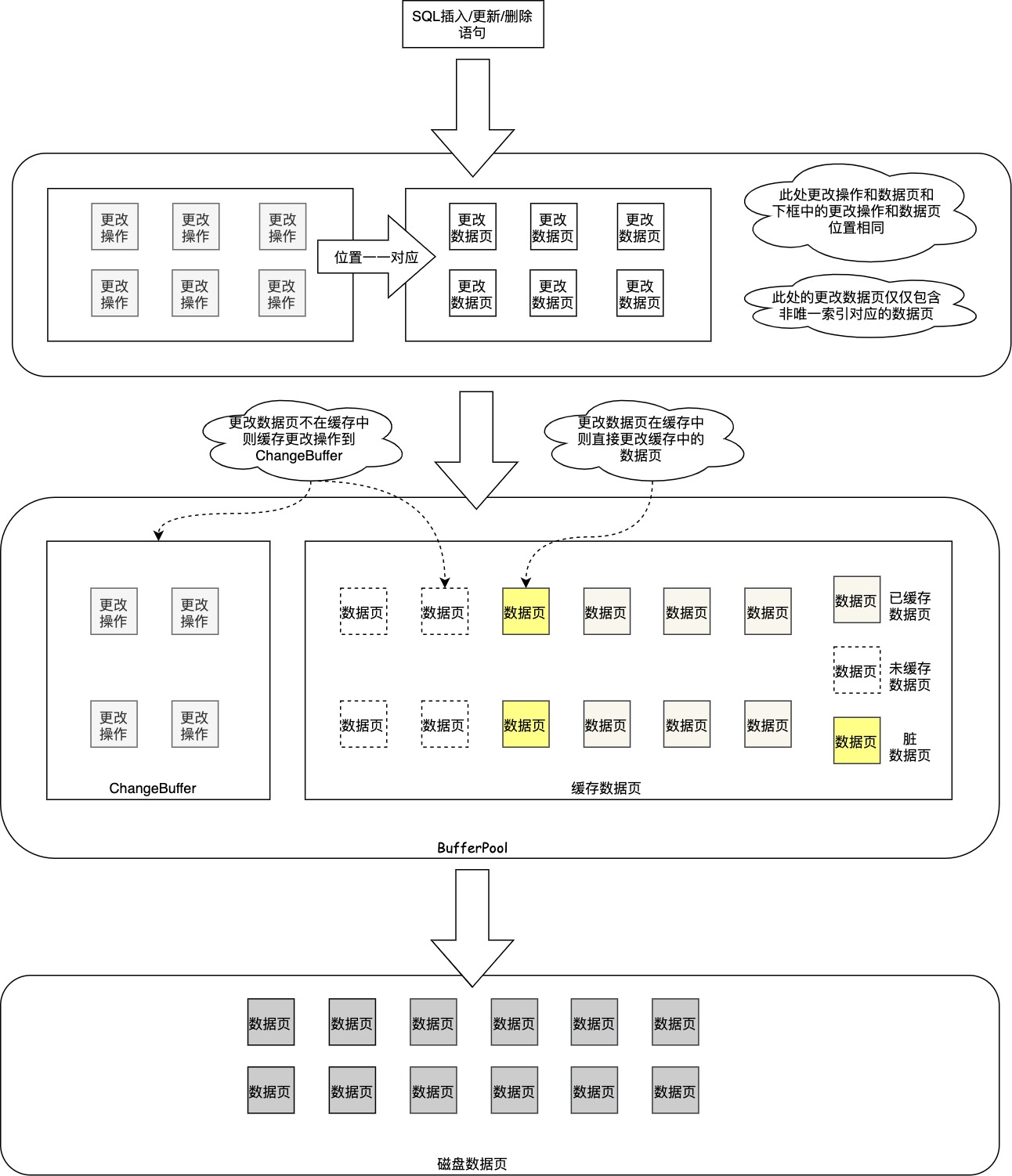
ChangeBuffer的作用
我们知道InnoDB推荐使用自增主键,插入时主键值时递增的,可以顺序访问。与聚簇索引不同,二级索引通常是不是唯一的,并且以相对随机的顺序插入。类似的,二级索引的更新和删除经常也会影响索引树中不相邻的二级索引数据页。
对于二级索引数据变更引起的随机访问,如果每次都进行磁盘IO显然会影响数据库的性能。因此InnoDB不会立即执行数据页不在缓存中的二级索引的变更操作,而是先将变更操作缓存起来,在某个时刻再将某一个数据页上面的所有变更操作合并到该数据页上,通过变更操作缓存(ChangeBuffer)可合并同一个数据页上的大量随机访问I/O。
ChangeBuffer工作流程
变更操作什么时候放入ChangeBuffer
并不是数据库中的所有操作都会进入ChangeBuffer,满足以下条件的数据库语句,在执行阶段不会修改数据页,而是会进入ChangeBuffer,
- SQL会修改数据库中的数据;
- SQL语句不涉及唯一键的校验;
- SQL语句不需要返回变更后的数据;
- 涉及的数据页不在缓存中;
ChangeBuffer合并到原数据页
我们知道,ChangeBuffer中缓存了变更操作,这些操作最终需要合并到数据库的数据页,合并过程称为Merge,那么在什么场景下会触发ChangeBuffer的Merge操作呢?
- 访问变更操作对应的数据页;
- InnoDB后台定期Merge;
- 数据库BufferPool空间不足;
- 数据库正常关闭时;
- RedoLog写满时;
为什么ChangeBuffer只缓存非唯一索引数据
ChangeBuffer仅仅适用于变更的数据未为非唯一索引的情况,如果变更操作修改的数据为唯一索引或者主键数据,那么InnoDB无法把变更操作缓存到ChangeBuffer,这是为什么呢?
以一张用户表为例,用户表包含主键ID、年龄、姓名和性别四个字段,其中年龄添加了非唯一索引,初始数据及建表语句如下所示:
| 用户ID | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 姓名 | 陈尔 | 张散 | 李思 | 王舞 | 赵流 | 孙期 | 周跋 | 吴酒 | 郑史 |
| 性别 | 男 | 男 | 女 | 女 | 男 | 男 | 男 | 女 | 男 |
| 年龄 | 5 | 10 | 20 | 28 | 35 | 56 | 25 | 80 | 90 |
create table user_info
(
id int primary key,
age int not null,
name varchar(16),
sex bool,
key(age)
)engine=InnoDB;
非唯一索引更新
假设我们使用SQL语句update user_info set age=6 where id=1修改ID=1的用户的年龄为6,该操作会同时修改年龄索引以及行数据中的年龄,更新步骤如下:
- 如果需要更改的年龄索引页和行数据页在缓存中,直接更新缓存中的数据,并把数据页标记为脏页;
- 如果需要更改的年龄索引页和行数据页不在缓存中,直接把SQL语句
update user_info set age=6 where id=1存储到ChangeBuffer;
唯一索引更新
假设我们使用SQL语句update user_info set id=2 where id=1修改ID=1的用户的ID为2,该操作会同时修改聚簇索引和行数据,更新步骤如下:
- 如果需要更改的聚簇索引和行数据页在缓存中,直接更新缓存中的数据,并把数据页标记为脏页;
- 如果需要更改的聚簇索引页和行数据页不在缓存中,需要把对应的数据页加载到缓存中,判断修改之后ID是不是符合唯一键约束,然后修改缓存中的数据;
可以看到,由于唯一索引需要进行唯一性校验,所以对唯一索引进行更新时必须将对应的数据页加载到缓存中进行校验,从而导致ChangeBuffer失效。
普通索引还是唯一索引
通过以上分析,我们知道唯一索引无法使用ChangeBuffer,那么我们实际使用过程中应该使用普通索引还是唯一索引呢?
从等值查询性能角度来看:
- 普通索引在查找到第一个满足条件的数据之后,需要继续向后查找满足条件的数据;
- 唯一索引在查找到第一个满足条件的数据之后,不需要再次向后查找,因为索引具有唯一性;
二者之间只相差一条记录,这个一条记录会带来多大的性能差距呢?答案是,微乎其微。因为InnoDB引擎是以页为单位读取数据的,读取一条数据时,往往会将临近的数据也读到内存,所以多向后查询几条数据带来的性能差别微乎其微。
从索引修改角度来看:
由于非唯一索引无法使用ChangeBuffer,对索引的修改会引起大量的磁盘IO,影响数据库性能。
综上可知,如果不是业务中要求数据库对某个字段做唯一性检查,我们最好使用普通索引而不是唯一索引。
ChangeBuffer适用场景
什么情况下ChangeBuffer会有较大的性能提升呢?
- 数据库大部分索引是非唯一索引;
- 业务是写多读少,或者不是写后立刻读取;
不适合使用ChangeBuffer的场景与之对应:
先说什么时候不适合,如上文分析,当:
- 数据库都是唯一索引;
- 写入数据后,会立刻读取;
ChangeBuffer相关参数
-
innodb_change_buffer_max_size: 配置写缓冲的大小,占整个缓冲池的比例,默认值是25%,最大值是50%。
写多读少的业务,才需要调大这个值。 -
innodb_change_buffering: 配置哪些写操作启用写缓冲,可以设置成all/none/inserts/deletes等。
我是御狐神,欢迎大家关注我的微信公众号:wzm2zsd

本文最先发布至微信公众号,版权所有,禁止转载!
