pyinstaller和wordcloud和jieba的使用案列


一、pyinstaller库
1、简介
pyinstaller库:将脚本程序转变为可执行(.exe)格式的第三方库
注意:需要在.py文件所在目录进行以下命令,图标扩展名是.ico
2、格式:
pyinstaller -F 文件.py
pyinstaller -i 图标名.ico 文件名.py
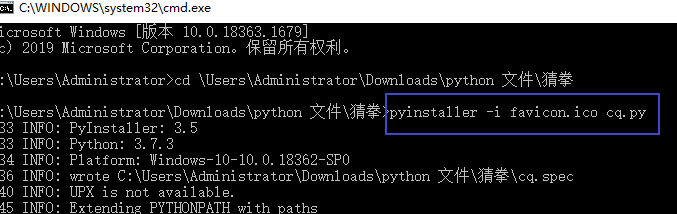
生成后的.exe文件放在dict文件夹里

二、wordcloud库
1、词云介绍
词云以词语为基本单元,根据其在文本中出现的频率设计不同大小一形成视觉上不同的效果,形成关键词云层或关键词渲染,从而使读者一眼就可以读到文本重点。wordcloud的核心是WordCloud类,所有功能都封装在这个类中,使用时需要先实例化一个WordCloud类的对象,并调用。
2、需要安装的模块
pip install wordcloud
pip install imageio
注意:字体文件需要指定路径,或者和文件放在同一目录
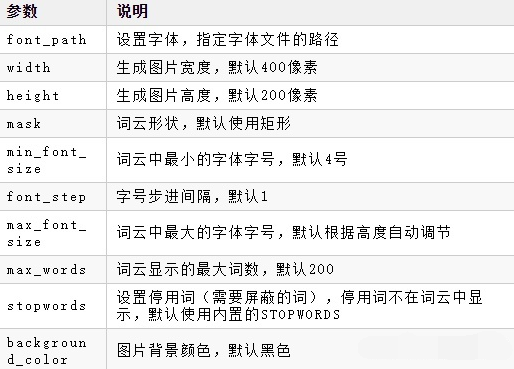
3、wordcloud常用的函数
WordCloud().generate(文本) 将字符串转化成词云
WordCloud().to_file(文件路径) 将词云生成文件
4、案列
点击查看代码
from wordcloud import WordCloud #使用WordCloud类
import imageio
# from scipy.misc import imread 其中imread模块在scipy中已经被弃用,建议使用imageio
mask = imageio.imread("C:/Users/wordcloud/hzw.png")
#图片转换成数组形式,一般使用png图片,windows中路径要么用/要么要\因为一条代表转义字符
with open("C:/Users/wordcloud/hzw.txt","r",encoding="utf-8") as f:
txt = f.read()
wordcloud = WordCloud(width=1017,
height=1097,
max_words=400,
max_font_size=80,
mask=mask,
font_path="msyh.ttc",
).generate(txt) #字符串转化成词云
wordcloud.to_file("C:/Users/wordcloud/xhzw.png") #词云生成文件
效果展示:

在生成词云时,wordcloud默认会以空格或标点为分割符对目标文本进行分词处理,对于中文文本,分词处理需要由用户来完成,可以结合jieba库一起使用,一般步骤是先将文本分词处理,然后以空格拼接,再调用。
用法:
words = jieba.lcut(txt)#进准分词
newtxt = ” “.join(words) #空格拼接
结合jieba库的效果

三、jieba库
1、简介
通过中文词库的方式来识别分词的
— 利用一个中文词库,确定汉字之间的关联概率
— 通过计算汉字之间的概率,汉字间概率大的组成词组,形成分词结果
— 除了分词,用户还可以添加自定义的词组
2、案列
点击查看代码
from posixpath import commonpath
import jieba
with open("C:/Users/hzw.txt","r",encoding="utf-8") as f:
txt = f.read()
words = jieba.lcut(txt)
counts = {}
bd = [",","。","、"," "]
for word in words:
if word in bd:
continue #如果文本中有标点符号,就跳过
elif len(word)==1: #表示一个字的次遇到就跳过
continue
else:
counts[word]=counts.get(word,0)+1 #将出现过的次记录次数并写进字典
items = list(counts.items()) #将字典转成列表
items.sort(key=lambda x:x[1],reverse=True)
#x可以是任意,[]里面的数表示对第几个元素排序,reverse=True表示升序,默认是降序
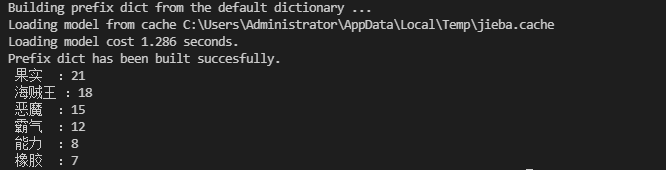
for i in range(3): #循环三次,只展示排名前三的结果
word,count=items[i] #从元组里取值
print(f"{word:^5}:{count:<5}") #^居中对齐,保留5个宽度
效果展示