分布式事务(二)之两阶段提交


前面的文章中,我们介绍了分布式系统中的CAP理论和BASE理论,本文会就分布式事务的实现方案之一:两阶段提交(2PC)进行介绍。2PC是一个非常经典的强一致、中心化的原子提交协议。中心化是指协议中有两类节点:一个是中心化协调者节点(coordinator)和N个参与者节点(partcipant)。
2PC
一致性概念
一致性,是指对每个节点一个数据的更新,整个集群都知道更新,并且是一致的,假设一个具有N个节点的分布式系统,当其满足以下条件时,我们说这个系统满足一致性:
- 全认同: 所有N个节点都认同一个结果;
- 值合法: 该结果必须由N个节点中的过半节点提出;
- 可结束: 决议过程在一定时间内结束,不会无休止地进行下去;
一致性的挑战
消息传递异步无序: 现实网络不是一个可靠的信道,存在消息延时、丢失,节点间消息传递做不到同步有序:
- 节点宕机: 节点持续宕机,不会恢复;
- 节点宕机恢复: 节点宕机一段时间后恢复,在分布式系统中最常见;
- 网络分化: 网络链路出现问题,将N个节点隔离成多个部分;
- 拜占庭将军问题: 节点或宕机或逻辑失败,甚至不按套路出牌抛出干扰决议的信息。
2PC原理
2PC(tow phase commit)两阶段提交。所谓的两个阶段是指:
- 第一阶段:准备阶段(投票阶段)
- 第二阶段:提交阶段(执行阶段)。
我们将提议的节点称为协调者(coordinator),其他参与决议节点称为参与者(participants, 或cohorts)。
2PC第一阶段
2PC的第一阶段是投票环节,投票由协调者节点发起,可以进一步细分为以下步骤:
- 事务询问:协调者向所有的参与者发送事务预处理请求,称之为Prepare,并开始等待各参与者的响应。
- 执行本地事务:各个参与者节点执行本地事务操作,但在执行完成后并不会真正提交数据库本地事务,而是先向协调者报告说:“我这边可以处理了/我这边不能处理”。
- 各参与者向协调者反馈事务询问的响应:如果参与者成功执行了事务操作,那么就反馈给协调者Yes响应,表示事务可以执行,如果没有参与者成功执行事务,那么就反馈给协调者No响应,表示事务不可以执行。
第一阶段执行完后,会有两种可能。1、所有都返回Yes. 2、有一个或者多个返回No。

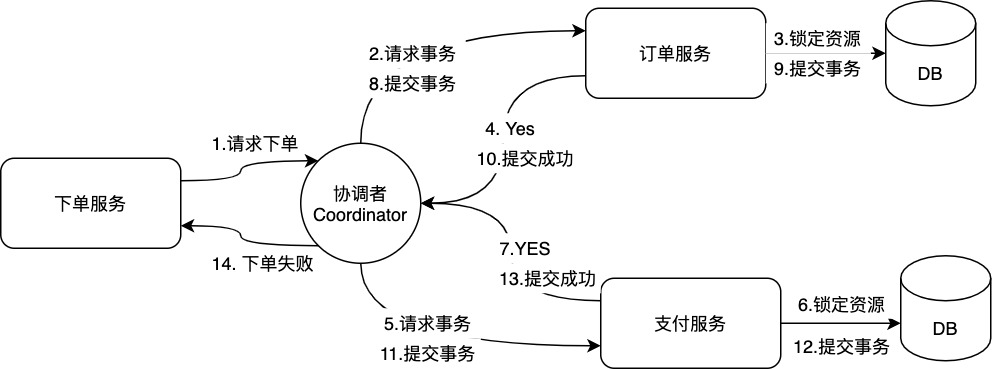
2PC第二阶段:正常提交
如果第一阶段所有的参与者都返回Yes,那么我们就可以继续执行2PC第二阶段的正常提交步骤:
- 协调者节点通知所有的参与者Commit事务请求;
- 参与者收到Commit请求之后,就会正式执行本地事务Commit操作,并在完成提交之后释放整个事务执行期间占用的事务资源。
2PC第二阶段:异常回滚
如果任何一个参与者向协调者反馈了No响应,或者等待超时之后,协调者尚未收到所有参与者的反馈响应,那么我们就需要执行2PC第二阶段的回滚操作:
- 协调者节点通知所有的参与者Rollback请求;
- 参与者收到Rollback请求之后,就会正式执行本地事务Rollback操作,并在完成提交之后释放整个事务执行期间占用的事务资源。

2PC存在的问题
通过上面的演示,很容易想到2pc所带来的缺陷:
- 性能问题:无论是在第一阶段的过程中,还是在第二阶段,所有的参与者资源和协调者资源都是被锁住的,只有当所有节点准备完毕,事务 协调者 才会通知进行全局提交,参与者进行本地事务提交后才会释放资源。这样的过程会比较漫长,对性能影响比较大。
- 单节点故障:由于协调者的重要性,一旦协调者发生故障。参与者会一直阻塞下去。尤其在第二阶段,协调者发生故障,那么所有的参与者还都处于锁定事务资源的状态中,而无法继续完成事务操作。(虽然协调者挂掉,可以重新选举一个协调者,但是无法解决因为协调者宕机导致的参与者处于阻塞状态的问题)。
2PC节点故障的情况
协调者正常,参与者宕机
由于协调者无法收集到所有参与者的反馈,会陷入阻塞情况。解决方案:引入超时机制,如果协调者在超过指定的时间还没有收到参与者的反馈,事务就失败,向所有节点发送终止事务请求。
协调者宕机,参与者正常
无论处于哪个阶段,由于协调者宕机,无法发送提交请求,所有处于执行了操作但是未提交状态的参与者都会陷入阻塞情况。解决方案:引入协调者备份,同时协调者需记录操作日志.当检测到协调者宕机一段时间后,协调者备份取代协调者,并读取操作日志,向所有参与者询问状态。
协调者和参与者都宕机
如果发生在第一阶段: 因为第一阶段,所有参与者都没有真正执行commit,所以只需重新在剩余的参与者中重新选出一个协调者,新的协调者在重新执行第一阶段和第二阶段就可以了。
发生在第二阶段并且挂了的参与者在挂掉之前没有收到协调者的指令:也就是上面的第2步挂了,这是可能协调者还没有发送第2步就挂了。这种情形下,新的协调者重新执行第一阶段和第二阶段操作。
发生在第二阶段并且有部分参与者已经执行完commit操作:就好比这里订单服务A和支付服务B都收到协调者发送的commit信息,开始真正执行本地事务commit,但突发情况,A commit成功,B挂了。这个时候目前来讲数据是不一致的。虽然这个时候可以再通过手段让他和协调者通信,再想办法把数据搞成一致的,但是,这段时间内他的数据状态已经是不一致的了! 2PC无法解决这个问题。
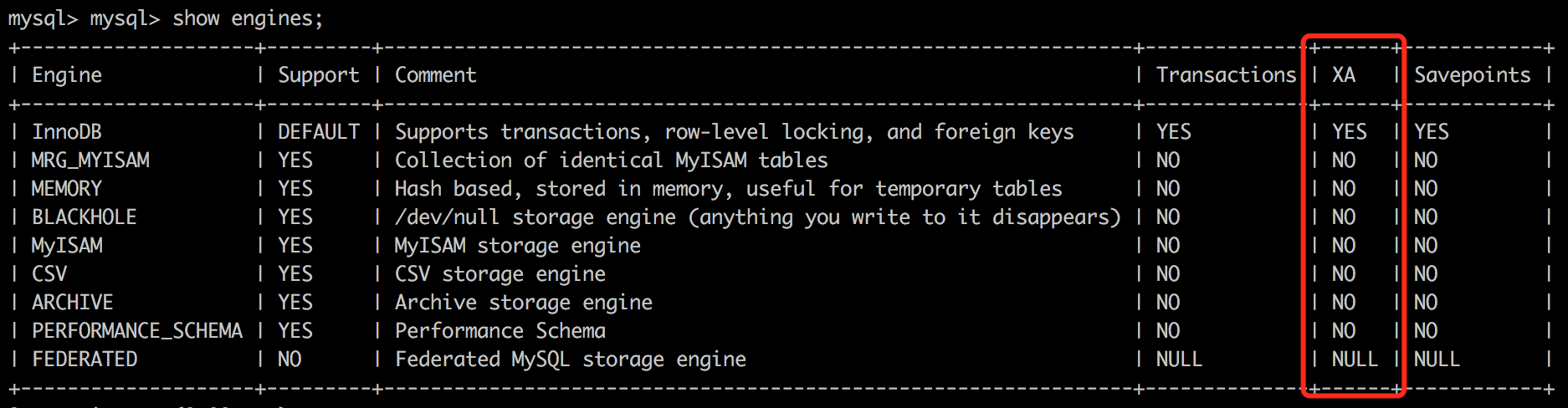
mysql对XA事务的支持
MySQL 从5.0.3开始支持XA分布式事务,且只有InnoDB存储引擎支持。MySQL Connector/J 从5.0.0版本之后开始直接提供对XA的支持。
需要注意的是, 在DTP模型中,mysql属于资源管理器(RM)。而一个完整的分布式事务中,一般会存在多个RM,由事务管理器TM来统一进行协调。因此,这里所说的mysql对XA分布式事务的支持,一般指的是单台mysql实例如何执行自己的事务分支。
XA {START|BEGIN} xid [JOIN|RESUME] //开启XA事务,如果使用的是XA START而不是XA BEGIN,那么不支持[JOIN|RESUME],xid是一个唯一值,表示事务分支标识符
XA END xid [SUSPEND [FOR MIGRATE]] //结束一个XA事务,不支持[SUSPEND [FOR MIGRATE]]
XA PREPARE xid 准备提交
XA COMMIT xid [ONE PHASE] //提交,如果使用了ONE PHASE,则表示使用一阶段提交。两阶段提交协议中,如果只有一个RM参与,那么可以优化为一阶段提交
XA ROLLBACK xid //回滚
XA RECOVER [CONVERT XID] //列出所有处于PREPARE阶段的XA事务
JTA的实现
Java事务API(JTA:Java Transaction API)和它的同胞Java事务服务(JTS:Java Transaction Service),为J2EE平台提供了分布式事务服务(distributed transaction)的能力。 某种程度上,可以认为JTA规范是XA规范的Java版,其把XA规范中规定的DTP模型交互接口抽象成Java接口中的方法,并规定每个方法要实现什么样的功能。在DTP模型中,规定了模型的五个组成元素:应用程序(Application)、资源管理器(Resource Manager)、事务管理器(Transaction Manager)、通信资源管理器(Communication Resource Manager)、 通信协议(Communication Protocol)。而在JTA规范中,模型中又多了一个元素Application Server,如下所示:

下面介绍一下在JTA规范中,模型中各个组件的作用:
事务管理器(transaction manager):
处于图中最为核心的位置,其他的事务参与者都是与事务管理器进行交互。事务了管理器提供事务声明,事务资源管理,同步,事务上下文传播等功能。JTA规范定义了事务管理器与其他事务参与者交互的接口,而JTS规范定义了事务管理器的实现要求,因此我们看到事务管理器底层是基于JTS的。
应用服务器(application server):
顾名思义,是应用程序运行的容器。JTA规范规定,事务管理器的功能应该由application server提供,如上图中的EJB Server。一些常见的其他web容器,如:jboss、weblogic、websphere等,都可以作为application server,这些web容器都实现了JTA规范。特别需要注意的是,并不是所有的web容器都实现了JTA规范,如tomcat并没有实现JTA规范,因此并不能提供事务管理器的功能。
应用程序(application):
简单来说,就是我们自己编写的应用,部署到了实现了JTA规范的application server中,之后我们就可以我们JTA规范中定义的UserTransaction类来声明一个分布式事务。通常情况下,application server为了简化开发者的工作量,并不一定要求开发者使用UserTransaction来声明一个事务,开发者可以在需要使用分布式事务的方法上添加一个注解,就像spring的声明式事务一样,来声明一个分布式事务。
特别需要注意的是,JTA规范规定事务管理器的功能由application server提供。但是如果我们的应用不是一个web应用,而是一个本地应用,不需要被部署到application server中,无法使用application server提供的事务管理器功能。又或者我们使用的web容器并没有事务管理器的功能,如tomcat。对于这些情况,我们可以直接使用一些第三方的事务管理器类库,如JOTM和Atomikos。将事务管理器直接整合进应用中,不再依赖于application server。
资源管理器(resource manager):
理论上任何可以存储数据的软件,都可以认为是资源管理器RM。最典型的RM就是关系型数据库了,如mysql,另外一种比较常见的资源管理器是消息中间件,如ActiveMQ、RabbitMQ等, 这些都是真正的资源管理器。
事实上,将资源管理器(resource manager)称为资源适配器(resource adapter)似乎更为合适。因为在java程序中,我们都是通过client来于RM进行交互的,例如:我们通过mysql-connector-java-x.x.x.jar驱动包,获取Conn、执行sql,与mysql服务端进行通信;通过ActiveMQ、RabbitMQ等的客户端,来发送消息等。
正常情况下,一个数据库驱动供应商只需要实现JDBC规范即可,一个消息中间件供应商只需要实现JMS规范即可。 而引入了分布式事务的概念后,DB、MQ等在DTP模型中的作用都是RM,二者是等价的,需要由TM统一进行协调。
为此,JTA规范定义了一个XAResource接口,其定义RM必须要提供给TM调用的一些方法。之后,不管这个RM是DB,还是MQ,TM并不关心,因为其操作的是XAResource接口。而其他规范(如JDBC、JMS)的实现者,同时也对此接口进行实现。如MysqlXAConnection,就实现了XAResource接口。
通信资源管理器(Communication Resource Manager):
这个是DTP模型中就已经存在的概念,对于需要跨应用的分布式事务,事务管理器彼此之间需要通信,这是就是通过CRM这个组件来完成的。JTA规范中,规定CRM需要实现JTS规范定义的接口。
下图更加直观的演示了JTA规范中各个模型组件之间是如何交互的:

交互情况如下:
- application运行在application server中;
- application 需要访问3个资源管理器(RM)上资源:1个MQ资源和2个DB资源;
- 由于这些资源服务器是独立部署的,如果需要同时进行更新数据的话并保证一致性的话,则需要使用到分布式事务,需要有一个事务管理器来统一协调;
- Application Server提供了事务管理器的功能;
- 作为资源管理器的DB和MQ的客户端驱动包,都实现了XAResource接口,以供事务管理器调用。
参考文章
mysql 对XA事务的支持
3.0 JTA规范
我是御狐神,欢迎大家关注我的微信公众号:wzm2zsd

本文最先发布至微信公众号,版权所有,禁止转载!
