自己实现Controller——标准型


标准Controller
上一篇通过一个简单的例子,编写了一个controller-manager,以及一个极简单的controller。从而对controller的开发有个最基本的认识,但是细心观察前一篇实现的controller仅仅是每次全量获取了所有资源,虽然都是从缓存中获取速度是比较快的,如果单次处理一个资源时的时间比较长,而且没必要每次都把所有资源都扫描一遍,上一篇实现的controller显然不符合使用场景了,本篇将继续用另一种方式开发一个结构较为标准的Controller,并介绍支撑controller功能实现的Informer架构。
先介绍一下本次实现的controller需要实现的功能,本controller通过监控Node节点的新增,发现新增是通过特定方式加入集群的,就给该node打上label。
看下本次controller的结构包含的成员
type NodeController struct {
kubeClient *kubernetes.Clientset //用于给符合条件的node打标记用
nodeLister corelisters.NodeLister //用于获取被监控的node资源
nodeListerSynced cache.InformerSynced
nodesQueue workqueue.DelayingInterface //一个延时队列,用于记录需要controller的node的key
cloudProvider cloudproviders.CloudProvider //用于判定node是否符合条件打标记,此成员并非controller关键结构的成员
}
下面是Controller的构造函数
func NewNodeController(kubeClient *kubernetes.Clientset, nodeInformer coreinformers.NodeInformer, cp cloudproviders.CloudProvider) *NodeController {
n := &NodeController{
kubeClient: kubeClient,
nodeLister: nodeInformer.Lister(),
nodeListerSynced: nodeInformer.Informer().HasSynced,
nodesQueue: workqueue.NewNamedDelayingQueue("nodes"),
cloudProvider: cp,
}
nodeInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: func(cur interface{}) {
node := cur.(*v1.Node)
fmt.Printf("controller: Add event, nodes [%s]
", node.Name)
n.syncNodes(node)
},
DeleteFunc: func(cur interface{}) {
node := cur.(*v1.Node)
fmt.Printf("controller: Delete event, nodes [%s]
", node.Name)
n.syncNodes(node)
},
})
return n
}
传入构造函数的Informer除了提供Lister和HasSynced函数以外,多了一个事件注册的操作,注册了node资源的Add事件和Delete事件。这个AddEventHandler除了注册这两种事件外,还可以注册Update事件,由于在这次例子中不需要处理这方面的事件,因此没有用上。此处通过Informer的事件回调实现了哪个资源有变更,就会触发事件,通知到controller来,与前一个controller相比这种就能立马定位到有变更的资源,无需将资源全量扫描才找到对应的资源。代码中两个事件处理函数都是获取到变更的node,打印出node的名字和变更事件,最后调用syncNodes方法
func (n *NodeController) syncNodes(node *v1.Node) {
key, err := cache.DeletionHandlingMetaNamespaceKeyFunc(node)
if err != nil {
fmt.Printf("Couldn"t get key for object %#v: %v
", node, err)
return
}
fmt.Printf("working queue add node %s
", key)
n.nodesQueue.Add(key)
}
syncNodes单纯给资源求了一个key,再把这个key塞到workqueue中。接收informer传递过来的变更事件处理也就此结束。
然后到启动controller的Run方法
func (n *NodeController) Run(stopCh <-chan struct{}) {
defer runtime.HandleCrash()
defer n.nodesQueue.ShutDown()
fmt.Println("Starting service controller")
defer fmt.Println("Shutting down service controller")
if !cache.WaitForCacheSync(stopCh, n.nodeListerSynced) {
runtime.HandleError(fmt.Errorf("time out waiting for caches to sync"))
return
}
for i := 0; i < WorkerCount; i++ {
go wait.Until(n.worker, time.Second, stopCh)
}
<-stopCh
}
func (n *NodeController) worker() {
for {
func() {
key, quit := n.nodesQueue.Get()
if quit {
return
}
defer n.nodesQueue.Done(key)
err := n.handleNode(key.(string))
if err != nil {
fmt.Printf("controller: error syncing node, %v
", err)
}
}()
}
}
接收终止信号和缓存处理与之前的controller没多大区别,区别就在于启动了若干个worker协程,worker方法就从workqueue中取出key,然后处理node
func (n *NodeController) handleNode(key string) error {
_, name, err := cache.SplitMetaNamespaceKey(key)
if err != nil {
return err
}
node, err := n.nodeLister.Get(name)
switch {
case errors.IsNotFound(err):
fmt.Printf("Node has been deleted %v
", key)
return nil
case err != nil:
fmt.Printf("Unable to retrieve node %v from store: %v
", key, err)
n.nodesQueue.AddAfter(key, time.Second*30)
return err
default:
err := n.processNodeAddIntoCluster(node)
if err != nil {
n.nodesQueue.AddAfter(key, time.Second*30)
}
return err
}
return nil
}
由于workqueue里存的也只是代表资源的key,此时需要将key转换回资源的name,还是通过lister从cache中把资源取出。当取不出来,就表明资源已经被删除了,如果有相应的删除相关的逻辑就可以在此处执行;如果能取出来,当前的资源已经是最新版本的资源(更新时会有新旧两个版本的资源,这里拿到的是新版本的),当然在本例中没有更新这个事件的处理;整个过程中出现了非期望的错误(如因资源被删除导致的IsNotFound error),处理逻辑需要重试,重试的方式就是将延时重新入队,延时队列的作用在此处得以发挥,因为有可能出现这种极端场景:当前只有一个资源需要被处理,而且该资源在刚创建的时候因为其状态未就绪确实会一直处理失败,假设当其被处理失败时马上又重新入队,那整个controller就会陷入一个类似于死循环的状态中,直到资源状态就绪,这样会浪费不少计算资源。
最后的processNodeAddIntoCluster就是给node打上label并调用kubeclient更新之,这里就不展示了。
看到上面使用了workqueue,颇有生产者消费者的模式,从informer的事件处理函数中获取到变更的资源将其放入队列,这个是生产者;worker处理方法从workqueue里取出变更资源处理,这个是消费者。使用了这个workqueue而不是直接在事件处理函数直接处理的目的在于事件触发的速度与资源处理的速度不一致,有workqueue在其中起到缓冲作用,免除了因实际处理变更的逻辑造成了事件触发方的阻塞导致影响了事件的实时性。
类似的队列和生产者消费者模式在informer中也有出现,作为controller处理资源变更调谐资源状态的上游,它又如何提供及时的变更事件给下游的controller,以及给下游的controller提供与apiserver一致的资源缓存。
Informer机制
Informer机制架构如下图所示
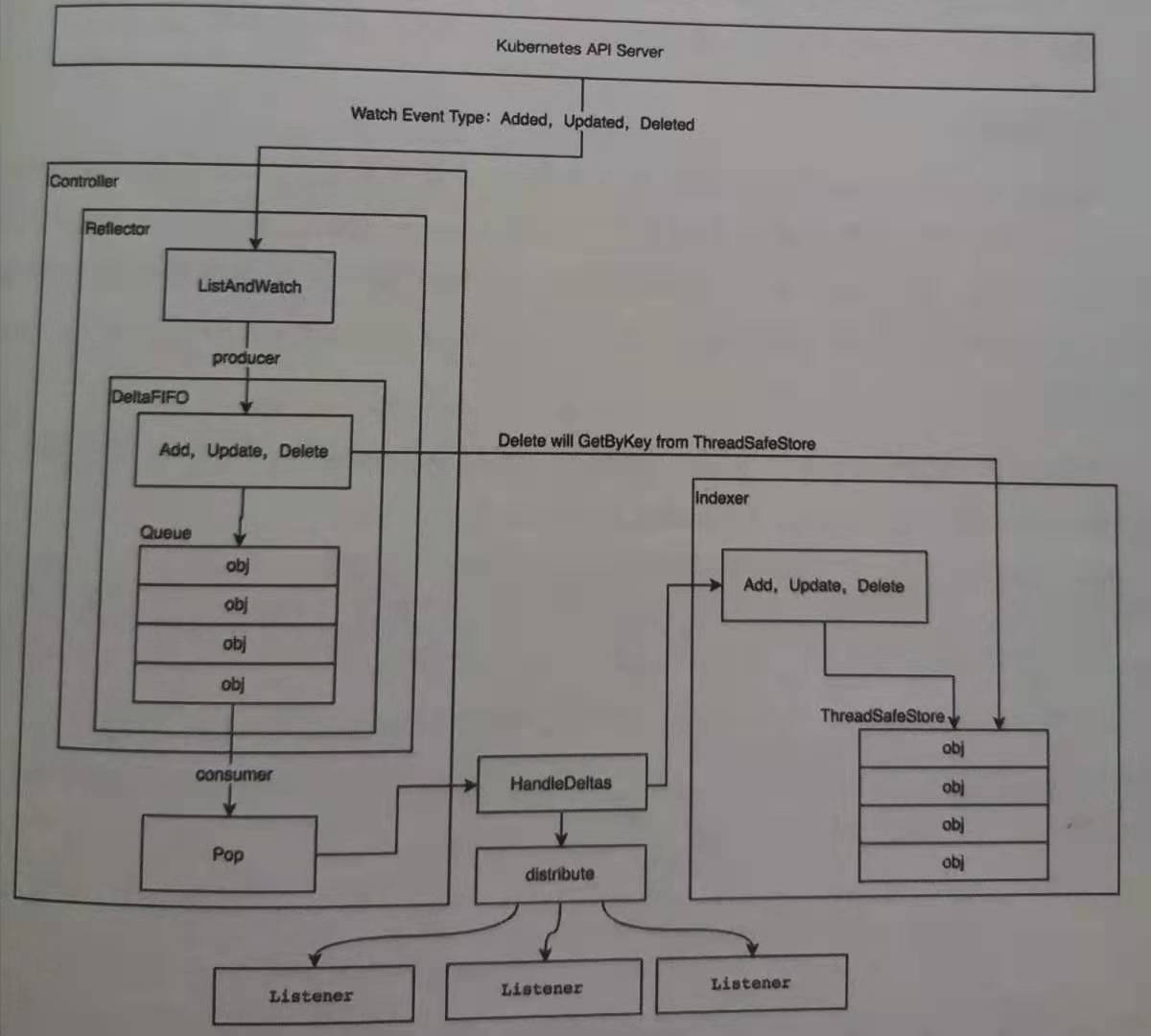
从该架构中还涉及了几个相关组件:
- Reflector:用于监控apiserver相关资源的变化,及时把变更获取回来,触发相关的变更事件,变更的资源存放到Delta FIFO里面;
- Delta FIFO:一个存放资源变更的FIFO队列,里面元素是以 Add/Update/Delete 为key,变更的资源为value这样的一个对象;
- Indexder:用于存放从Delta FIFO队列取出后,经过处理好的值,是apiserver的一个缓存,无需每次从apiserver以及Etcd中获取,减轻两者的压力,里面的缓存应与apiserver(实质是Etcd)保持一致。
从上面的结构中,尤其是Delta FIFO,模式与上面使用了WorkQueue的controller是一致的,生产者消费者模式:
- 生产者方面:主要操作由Reflector执行,它主要依靠ListAndWatch方法对apiserver的资源进行监控,ListAndWatch方法中就调用了由Informer提供的List方法和Watch方法,一旦获得变更的资源,就将资源及其变更的方式(Add,Update,Delete)一同存入Delta FIFO,如上面介绍Delta FIFO时所述;
- 消费者方面:主要操作由Controller执行,它主要调用Delta FIFO的Pop方法,从队列中取出变更的资源及其变更方式,调用之前注册到Informer里面相关的事件(即例子中NewNodeController函数中AddEventHandler方法注册进去的事件处理函数),将变更分发出去,在这里Delta FIFO除了记录变更的资源本身数据,也附带记录变更方式的作用体现出来了。最后将这个资源缓存到Indexer中,缓存时也是通过变更方式对缓存进行操作,比如是Add变更,则直接往缓存中Add一个记录;是Update则把缓存记录更新;是Delete则删除记录。这也是另一个体现记录变更方式的地方。
Informer和自定义的Controller(这个controller并非消费者的controller)的交互主要是两处,其一是AddEventHandler时,把变更资源收到自己的workerqueue中供后续执行调谐操作;其二是在调谐期间从Indexer(这个并非是直接调用,是通过调用Informer时嵌套调用的)获取缓存的资源值。整个过程所有涉及的成员如下图所示
小结Informer
Informer在整个过程中起到衔接各方的作用。Reflector对apiserver的监控是由Informer提供的ListAndWatch方法,资源从apiserver接口拿回来资源数据由注册进去Informer的反序列化器进行反序列化(这部分跟Schema有关)。而数据进入Indexer缓存前,的事件分发也是通过Informer调用各个已经注册上来的事件处理函数。
了解了Informer机制,后面则进行自定义资源的Controller开发,里面还需要给自定义资源扩展一个Informer,及封装跟apiserver访问自定义资源的client,实现完整的手捏Controller.
