并发编程之:ForkJoin


大家好,我是小黑,一个在互联网苟且偷生的农民工。
在JDK1.7中引入了一种新的Fork/Join线程池,它可以将一个大的任务拆分成多个小的任务并行执行并汇总执行结果。
Fork/Join采用的是分而治之的基本思想,分而治之就是将一个复杂的任务,按照规定的阈值划分成多个简单的小任务,然后将这些小任务的结果再进行汇总返回,得到最终的任务。
分治法
分治法是计算机领域常用的算法中的其中一个,主要思想就是将将一个规模为N的问题,分解成K个规模较小的子问题,这些子问题相互独立且与原问题性质相同;求解出子问题的解,合并得到原问题的解。
解决问题的思路
- 分割原问题;
- 求解子问题;
- 合并子问题的解为原问题的解。
使用场景
二分查找,阶乘计算,归并排序,堆排序、快速排序、傅里叶变换都用了分治法的思想。
ForkJoin并行处理框架
在JDK1.7中推出的ForkJoinPool线程池,主要用于ForkJoinTask任务的执行,ForkJoinTask是一个类似线程的实体,但是比普通线程更轻量。
我们来使用ForkJoin框架完成以下1-10亿求和的代码。
public class ForkJoinMain {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ForkJoinPool forkJoinPool = new ForkJoinPool();
ForkJoinTask<Long> rootTask = forkJoinPool.submit(new SumForkJoinTask(1L, 10_0000_0000L));
System.out.println("计算结果:" + rootTask.get());
}
}
class SumForkJoinTask extends RecursiveTask<Long> {
private final Long min;
private final Long max;
private Long threshold = 1000L;
public SumForkJoinTask(Long min, Long max) {
this.min = min;
this.max = max;
}
@Override
protected Long compute() {
// 小于阈值时直接计算
if ((max - min) <= threshold) {
long sum = 0;
for (long i = min; i < max; i++) {
sum = sum + i;
}
return sum;
}
// 拆分成小任务
long middle = (max + min) >>> 1;
SumForkJoinTask leftTask = new SumForkJoinTask(min, middle);
leftTask.fork();
SumForkJoinTask rightTask = new SumForkJoinTask(middle, max);
rightTask.fork();
// 汇总结果
return leftTask.join() + rightTask.join();
}
}
上述代码逻辑可通过下图更加直观的理解。
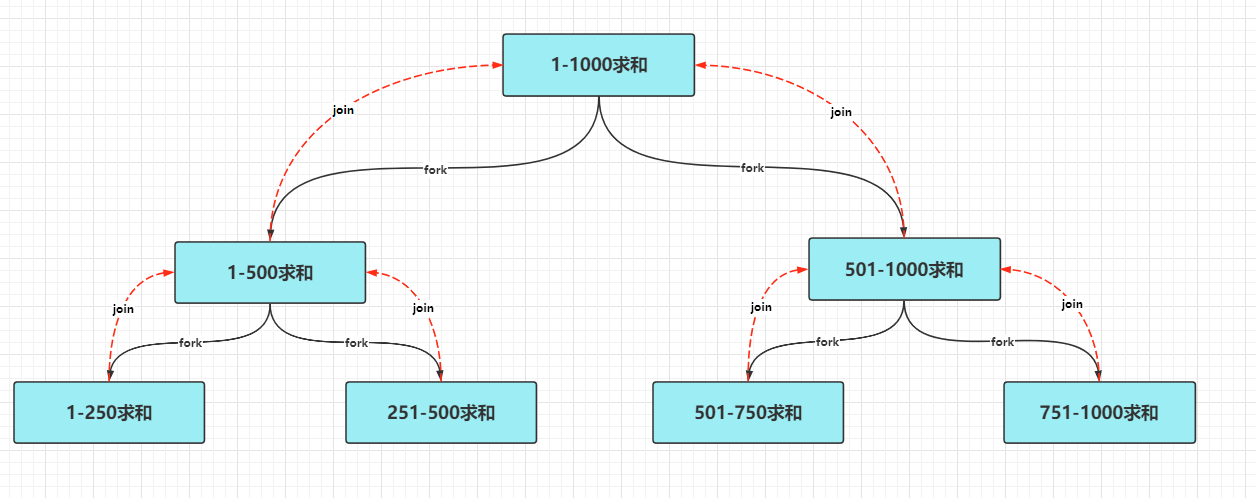
ForkJoin框架实现
在ForkJoin框架中重要的一些接口和类如下图所示。
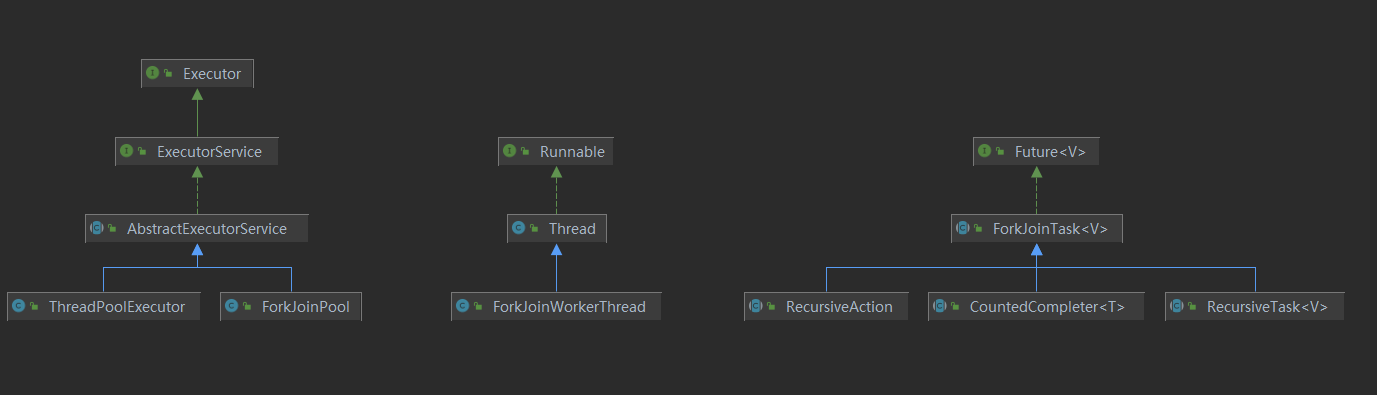
ForkJoinPool
ForkJoinPool是用于运行ForkJoinTasks的线程池,实现了Executor接口。
可以通过new ForkJoinPool()直接创建ForkJoinPool对象。
public ForkJoinPool() {
this(Math.min(MAX_CAP, Runtime.getRuntime().availableProcessors()),
defaultForkJoinWorkerThreadFactory, null, false);
}
public ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
boolean asyncMode){
this(checkParallelism(parallelism),
checkFactory(factory),
handler,
asyncMode ? FIFO_QUEUE : LIFO_QUEUE,
"ForkJoinPool-" + nextPoolId() + "-worker-");
checkPermission();
}
通过查看构造方法源码我们可以发现,在创建ForkJoinPool时,有以下4个参数:
- parallelism:期望并发数。默认会使用
Runtime.getRuntime().availableProcessors()的值 - factory:创建
ForkJoin工作线程的工厂,默认为defaultForkJoinWorkerThreadFactory - handler:执行任务时遇到不可恢复的错误时的处理程序,默认为
null - asyncMode:工作线程获取任务使用FIFO模式还是LIFO模式,默认为LIFO
ForkJoinTask
ForkJoinTask是一个对于在ForkJoinPool中运行任务的抽象类定义。
可以通过少量的线程处理大量任务和子任务,ForkJoinTask实现了Future接口。主要通过fork()方法安排异步任务执行,通过join()方法等待任务执行的结果。
想要使用ForkJoinTask通过少量的线程处理大量任务,需要接受一些限制。
- 拆分的任务中避免同步方法或同步代码块;
- 在细分的任务中避免执行阻塞I/O操作,理想情况下基于完全独立于其他正在运行的任务访问的变量;
- 不允许在细分任务中抛出受检异常。
因为ForkJoinTask是抽象类不能被实例化,所以在使用时JDK为我们提供了三种特定类型的ForkJoinTask父类供我们自定义时继承使用。
- RecursiveAction:子任务不返回结果
- RecursiveTask:子任务返回结果
- CountedCompleter:在任务完成执行后会触发执行
ForkJoinWorkerThread
ForkJoinPool中用于执行ForkJoinTask的线程。
ForkJoinPool既然实现了Executor接口,那么它和我们常用的ThreadPoolExecutor之前又有什么差异呢?
如果们使用ThreadPoolExecutor来完成分治法的逻辑,那么每个子任务都需要创建一个线程,当子任务的数量很大的情况下,可能会达到上万个,那么使用ThreadPoolExecutor创建出上万个线程,这显然是不可行、不合理的;
而ForkJoinPool在处理任务时,并不会按照任务开启线程,只会按照指定的期望并行数量创建线程。在每个线程工作时,如果需要继续拆分子任务,则会将当前任务放入ForkJoinWorkerThread的任务队列中,递归处理直到最外层的任务。
工作窃取算法
ForkJoinPool的各个工作线程都会维护一个各自的任务队列,减少线程之间对于任务的竞争;
每个线程都会先保证将自己队列中的任务执行完,当自己的任务执行完之后,会去看其他线程的任务队列中是否有未处理完的任务,如果有则会帮助其他线程执行;
为了减少在帮助其他线程执行任务时发生竞争,会使用双端队列来存放任务,被窃取的任务只会从队列的头部获取任务,而正常处理的线程每次都是从队列的尾部获取任务。
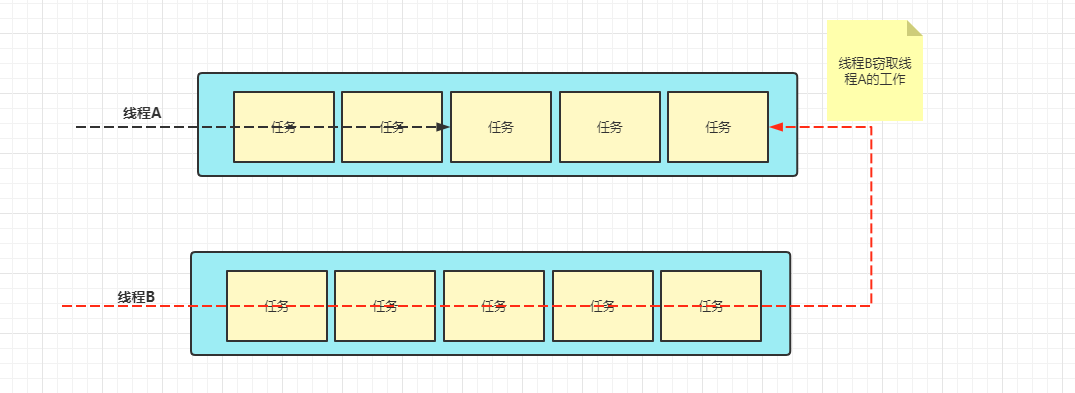
优点
充分利用了线程资源,避免资源的浪费,并且减少了线程间的竞争。
缺点
需要给每个线程开辟一个队列空间;在工作队列中只有一个任务时同样会存在线程竞争。
最后
如果觉得文章对你有点帮助,不妨扫码点个关注。我是小黑,下期见~

