亿级流量架构怎么做资源隔离?写得太好了!

作者:等不到的口琴
链接:https://www.cnblogs.com/Courage129/p/14421585.html
为什么要资源隔离
常见的资源,例如磁盘、网络、CPU等等,都会存在竞争的问题,在构建分布式架构时,可以将原本连接在一起的组件、模块、资源拆分开来,以便达到最大的利用效率或性能。资源隔离之后,当某一部分组件出现故障时,可以隔离故障,方便定位的同时,阻止传播,避免出现滚雪球以及雪崩效应。
常见的隔离方式有:
- 线程隔离
- 进程隔离
- 集群隔离
- 机房隔离
- 读写隔离
- 动静隔离
- 爬虫隔离
- 等等
线程隔离
网络上很多帖子,大多是从框架开始聊的,这儿说人话其实就是对线程进行治理,把核心业务线程与非核心业务线程隔开,不同的业务需要的线程数量不同,可以设置不同的线程池,来举一些框架中应用的例子,例如Netty中的主从多线程、Tomcat请求隔离、Dubbo线程模型。
Netty主从程模型
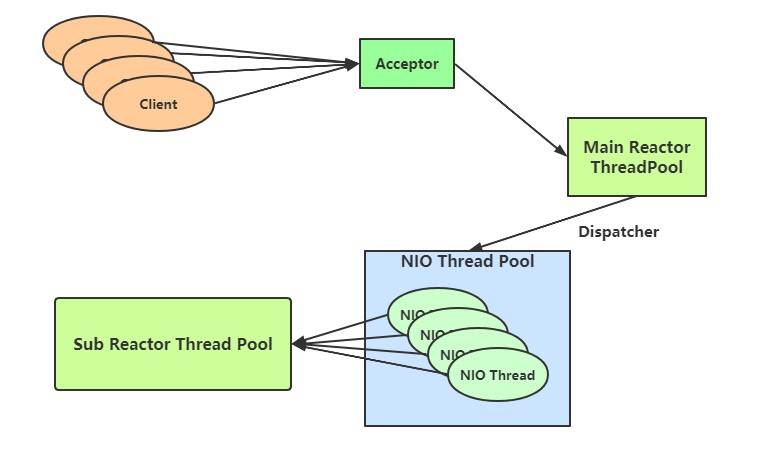
主线程负责认证,连接,成功之后交由从线程负责连接的读写操作,大致如下代码:
EventLoopGroup bossGroup = new NioEventLoopGroup(1);
EventLoopGroup workerGroup = new NioEventLoopGroup();
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup);
主线程是一个单线程,从线程是一个默认为cpu*2个数的线程池,可以在我们的业务handler中做一个简单测试:
public void channelRead(ChannelHandlerContext ctx, Object msg) {
System.out.println("thread name=" + Thread.currentThread().getName() + " server receive msg=" + msg);
}
服务端在读取数据的时候打印一下当前的线程:
thread name=nioEventLoopGroup-3-1 server receive msg="..."
可以发现这里使用的线程其实和处理io线程是同一个;
Dubbo线程隔离模型
Dubbo的底层通信框架其实使用的就是Netty,但是Dubbo并没有直接使用Netty的io线程来处理业务,可以简单在生产者端输出当前线程名称:
thread name=DubboServerHandler-192.168.1.115:20880-thread-2,...
可以发现业务逻辑使用并不是nioEventLoopGroup线程,这是因为Dubbo有自己的线程模型,可以看看官网提供的模型图:
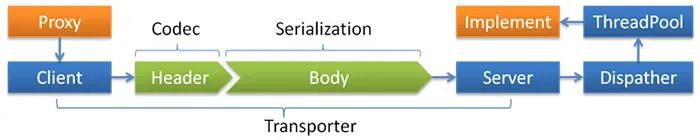
由图可以知道,Dubbo服务端接收到请求后,通过调度器(Dispatcher)分发到不同的线程池,也简单做一些关于调度器(Dispatcher)总结:
Dispatcher调度器可以配置消息的处理线程:
all所有消息都派发到线程池,包括请求,响应,连接事件,断开事件,心跳等。direct所有消息都不派发到线程池,全部在 IO 线程上直接执行。message只有请求响应消息派发到线程池,其它连接断开事件,心跳等消息,直接在 IO 线程上执行。execution只有请求消息派发到线程池,不含响应,响应和其它连接断开事件,心跳等消息,直接在 IO 线程上执行。connection在 IO 线程上,将连接断开事件放入队列,有序逐个执行,其它消息派发到线程池。
通过看源码可以知道,Dubbo默认使用的线程池是FixedThreadPool ,线程数默认为200 ;
Tomcat请求线程隔离
Tomcat是Servelet的具体实现,在Tomcat请求支持四种请求处理方式分别为:BIO、AIO、NIO、APR
BIO模式:阻塞式I/O操作,表示Tomcat使用的是传统Java。I/O操作(即Java.io包及其子包)。Tomcat7以下版本默认情况下是以bio模式运行的,由于每个请求都要创建一个线程来处理,线程开销较大,不能处理高并发的场景,在几种模式中性能也最低。
NIO模式:同步非阻塞I/O操作,是一个基于缓冲区、并能提供非阻塞I/O操作的API,它拥有比传统I/O操作具有更好的并发性能。
在Tomcat7版本之后,Tomcat把连接介入和业务处理拆分成两个线程池来处理,即:
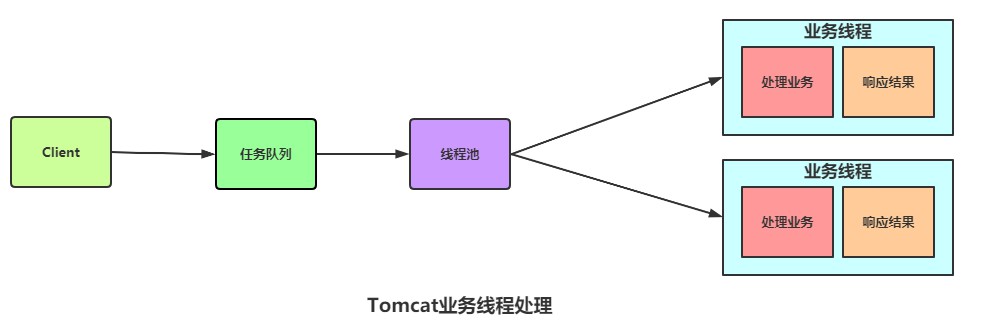
可以使用独立的线程池来维护servlet的创建。连接器connector能介入的请求肯定比业务复杂的servlet处理的个数要多,在中间,Tomcat加入了队列,来等待servlet线程池空闲。这两步是Tomcat内核完成的,在一阶段无法区分具体业务或资源,所以只能在连接介入,servlet初始化完成后我们根据自己的业务线去划分独立的连接池。
这样做,独立的业务或资源中如果出现崩溃,不会影响其他的业务线程,从而达到资源隔离和服务降级的效果。
在使用了servlet3之后,系统线程隔离变得更灵活了。可以划分核心业务队列和非核心业务队列:
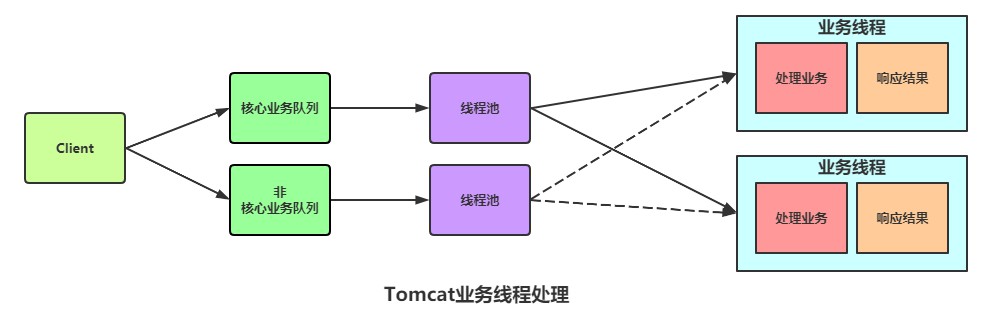
线程隔离小总结
- 资源一旦出现问题,虽然是隔离状态,想要让资源重新可用,很难做到不重启jvm。
- 线程池内部线程如果出现OOM、FullGC、cpu耗尽等问题也是无法控制的
- 线程隔离,只能保证在分配线程这个资源上进行隔离,并不能保证整体稳定性
进程隔离
进程隔离这种思想其实并不陌生,Linux操作系统中,利用文件管理系统将各个进程的虚拟内存与实际的物理内存映射起来,这样做的好处是避免不同的进程之间相互影响,而在分布式系统中,线程隔离不能完全隔离故障避免雪崩,例如某个线程组耗尽内存导致OOM,那么其他线程组势必也会受影响,所以进程隔离的思想是,CPU、内存等等这些资源也通过不同的虚拟机来做隔离。
具体操作是,将业务逻辑进行拆分成多个子系统(拆分原则可以参考:Redis集群拆分原则之AKF),实现物理隔离,当某一个子系统出现问题,不会影响到其他子系统。
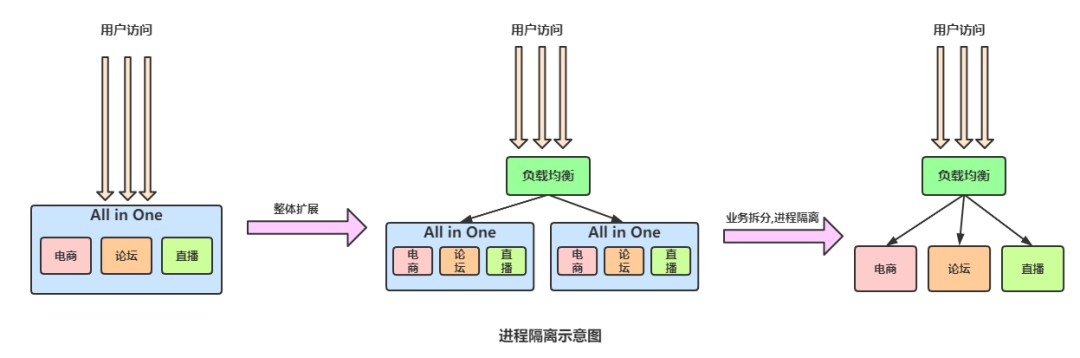
集群隔离
如果系统中某个业务模块包含像抢购、秒杀、存储I/O密集度高、网络I/o高、计算I/O高这类需求的时候,很容易在并发量高的时候因为这种功能把整个模块占有的资源全部耗尽,导致响应编码甚至节点不可用。
像上图的的拆分之后,如果某一天购物人数瞬间暴增,电商交易功能模块可能受影响,损坏后导致电商模块其他的浏览查询也无法使用,因此就要建立集群进行隔离,具体来说就是继续拆分模块,将功能微服务化。
解决方案
- 独立拆分模块
- 微服务化
可以使用hystrix在微服务中隔离分布式服务故障。他可以通过线程和信号量进行隔离。
线程池隔离与信号量隔离对比
这儿同上面的线程隔离,不多赘述,简单叙述一下hystrix的两种隔离方式的区别:
| 隔离方式 | 是否支持超时 | 是否支持熔断 | 隔离原理 | 是否是异步调用 | 资源消耗 |
|---|---|---|---|---|---|
| 线程池隔离 | 支持,可直接返回 | 支持,当线程池到达maxSize后,再请求会触发fallback接口进行熔断 | 每个服务单独用线程池 | 可以是异步,也可以是同步。看调用的方法 | 大,大量线程的上下文切换,容易造成机器负载高 |
| 信号量隔离 | 不支持,如果阻塞,只能通过调用协议(如:socket超时才能返回) | 支持,当信号量达到maxConcurrentRequests后。再请求会触发fallback | 通过信号量的计数器 | 同步调用,不支持异步 | 小,只是个计数器 |
信号量隔离
说人话就是,很多线程涌过来,要去获得信号量,获得了才能继续执行,否则先进入队列等待或者直接fallback回调
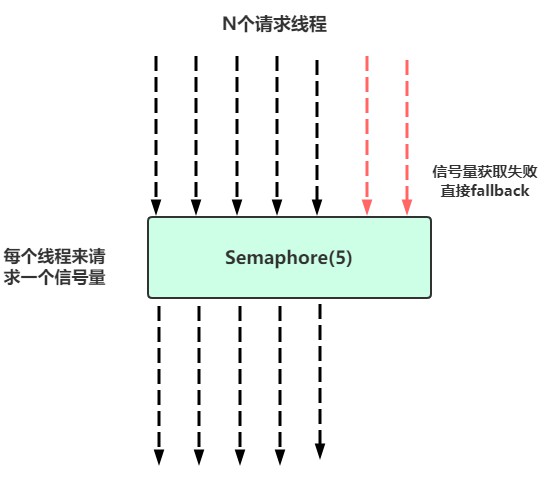
最重要的是,信号量的调用是同步的,也就是说,每次调用都得阻塞调用方的线程,直到结果返回。这样就导致了无法对访问做超时(只能依靠调用协议超时,无法主动释放)
官网对信号量隔离的描述建议
- Generally the only time you should use semaphore isolation for
HystrixCommands is when the call is so high volume (hundreds per second, per instance) that the overhead of separate threads is too high; this typically only applies to non-network calls.
理解下两点:
- 隔离的细粒度太高,数百个实例需要隔离,此时用线程池做隔离开销过大
- 通常这种都是非网络调用的情况下
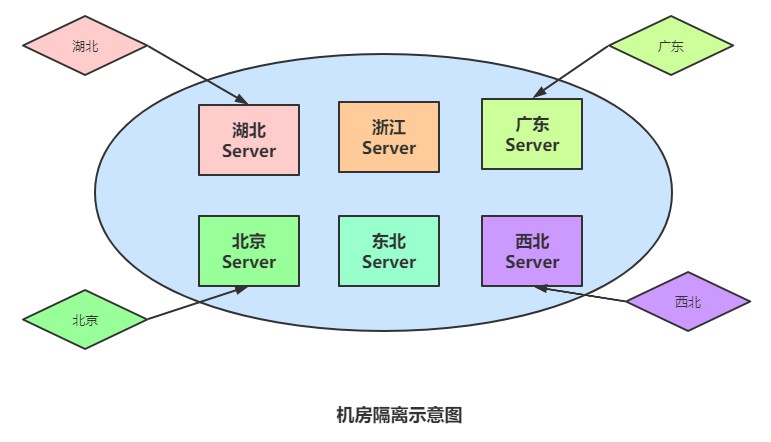
机房隔离
机房隔离主要目的有两个,一方面是将不同区域的用户数据隔离到不同的地区,例如湖北的数据放在湖北的服务器,浙江的放在浙江服务器,等等,这样能解决数据容量大,计算密集,i/o(网络)密集度高的问题,相当于将流量分在了各个区域。
另一方面,机房隔离也是为了保证安全性,所有数据都放在一个地方,如果发生自然灾害或者爆炸等灾害时,数据将全都丢失,所以把服务建立整体副本(计算服务、数据存储),在多机房内做异地多活或冷备份、是微服务数据异构的放大版本。
如果机房层面出现问题的时候,可以通过智能dns、httpdns、负载均衡等技术快速切换,让区域用户尽量不收影响。
数据读写隔离
通过主从模式,将mysql、redis等数据存储服务集群化,读写分离,那么在写入数据不可用的时候,也可以通过重试机制 临时通过其他节点读取到数据。
多节点在做子网划分的时候,除了异地多活,还可以做数据中心,所有数据在本地机房crud 异步同步到数据中心,数据中心再去分发数据给其他机房,那么数据临时在本地机房不可用的时候,就可以尝试连接异地机房或数据中心。
静态隔离
主要思路是将一些静态资源分发在边缘服务器中,因为日常访问中有很多资源是不会变的,所以没必要每次都想从主服务器上获取,可以将这些数据保存在边缘服务器上降低主服务器的压力。
有一篇很详细的讲解参考:全局负载均衡与CDN内容分发
爬虫隔离
建立合适的规则,将爬虫请求转移到另外的集群 。
目前我们开发的都是API接口,并且多数都是开放的API接口。也就是说,只要有人拿到这个接口,任何人都可以通过这个API接口获取数据,如果是网络爬虫请求速度快,获取的数据多,不仅会对服务器造成影响,不用多久,爬虫方完全可以用我们API的接口来开发一个同样的网站,开放平台的API接口调用需要限制其频率,以节约服务器资源和避免恶意的频繁调用,在大型互联网项目中,对于web服务和网络爬虫的访问流量能达到5:1,甚至更高,有的系统有时候就会因为爬虫流量过高而导致资源耗尽,服务不可用。解决策略大致两个方面:
一是限流,限制访问的频率;
二是将爬虫请求转发到固定地方。
爬虫限流
- 登录/会话限制
- 下载限流
- 访问频率
- ip限制,黑白名单
想要分辨出来一个访问是不是爬虫,可以简单的使用nginx来分析ua处理
UA介绍
User Agent 简称UA,就是用户代理。通常我们用浏览器访问网站,在网站的日志中,我们的浏览器就是一种UA。
禁止特定UA访问,例如最近有个网站A抄袭公司主站B的内容,除了域名不同,内容、图片等都完全是我们主站的内容。出现这种情况,有两种可能:
一种是:它用爬虫抓取公司主站B的内容并放到自己服务器上显示;
另一种是:通过将访问代理至公司主站B,而域名A是盗用者的,骗取流量。
无论怎样,都要禁止这种行为的继续。有两种方法解决:
1)禁止IP
2)禁止UA
从nginx日志观察,访问者的代理IP经常变,但是访问UA却是固定的,因而可以禁止UA。
nginx不仅可以处理ua来分离流量,还可以通过更强大的openresty来完成更复杂的逻辑,实现一个流量网关,软防火墙。
近期热文推荐:
1.1,000+ 道 Java面试题及答案整理(2021最新版)
2.别在再满屏的 if/ else 了,试试策略模式,真香!!
3.卧槽!Java 中的 xx ≠ null 是什么新语法?
4.Spring Boot 2.5 重磅发布,黑暗模式太炸了!
5.《Java开发手册(嵩山版)》最新发布,速速下载!
觉得不错,别忘了随手点赞+转发哦!
