并发编程之:深入解析线程池

大家好,我是小黑,一个在互联网苟且偷生的农民工。
本期带来线程池的第二期内容,如果对线程池的基本概念还不是很清楚,可以先看我上一篇文章。
面试官:谈谈你对线程池的理解
本期内容会从以下几个方面解析线程池的具体实现:
- 线程池状态
- 线程池初始化
- 如何执行任务
- 钩子方法
- 等待队列和排队策略
- 自定义拒绝策略
- 线程池关闭
- 动态调整容量
- 合理配置容量
线程池状态
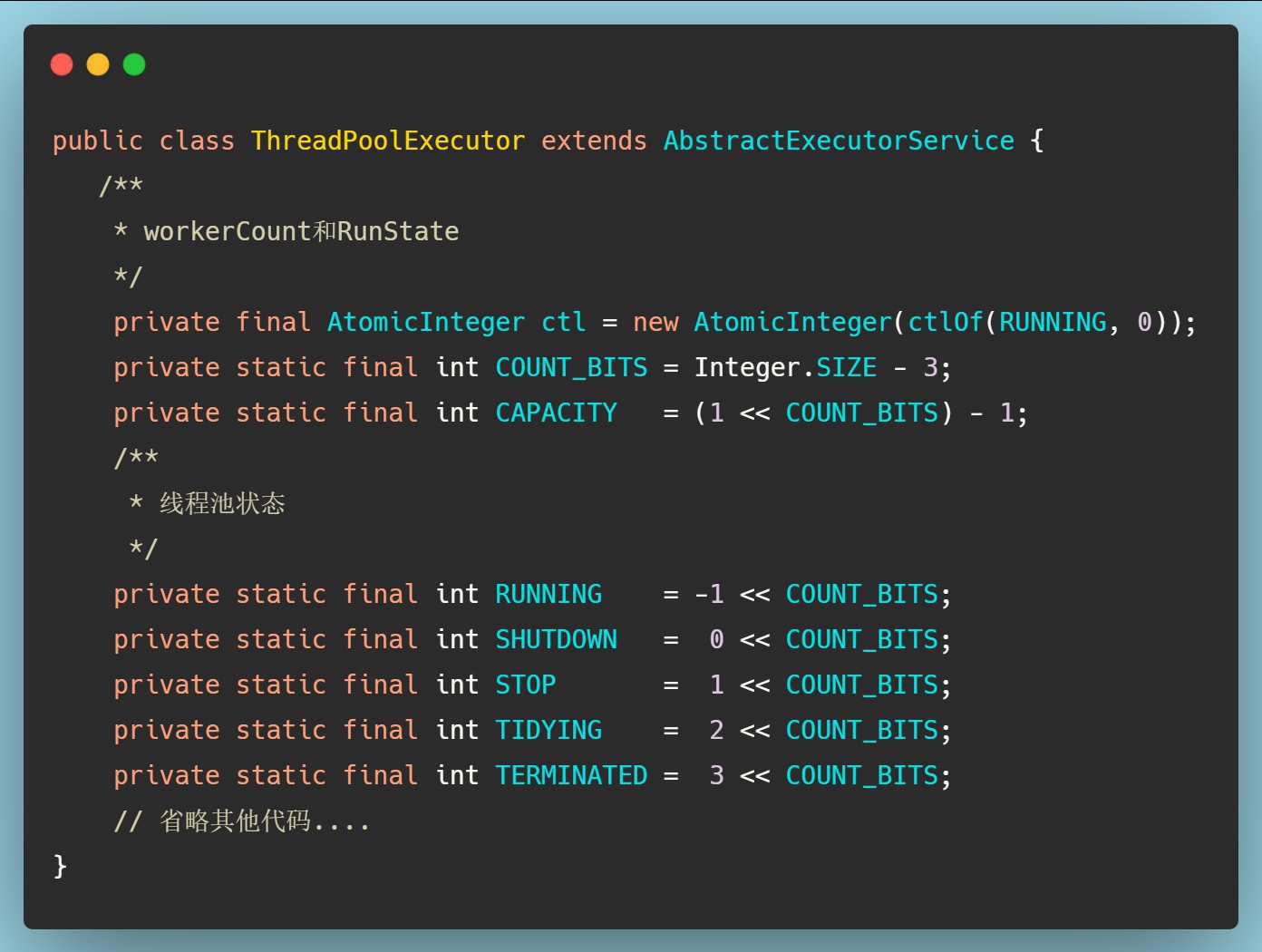
ThreadPoolExecutor中定义了如下几种线程池状态:
- RUNNING :运行状态,该线程池可以接受新任务和处理排队任务
- SHUTDOWN:关闭状态,不接受新任务,但处理排队任务
- STOP:停止状态,不接受新任务、不处理排队任务和中断进行中任务
- TIDYING:整理状态,所有的线程任务已终止,workerCount为零,转换到整理状态的线程将运行terminated()钩子方法
- TERMINATED:终止状态,terminated()执行完毕,线程池将会被设置为TERNINATED状态。
我们在上面代码中看到了对于线程池状态的定义,但是并没有发现有定义一个int类型的变量表示当前线程池的状态,那是怎么做的呢?
我们看到在最上面有定义一个AtomicInteger ctl这样一个原子类型的Integer,这个ctl不光可以表示线程池的运行状态,同时能够表示线程池的有效线程数workerCount。那么是怎么做到的呢?我们都知道Integer类型的内存大小是4个字节,对应32个bit,ctl将32位的高三位用来表示线程池的运行状态,低29位表示有效线程数。

这里可以想一下为什么是用高三位表示runState,不是两位,也不是4位呢?
因为线程池的状态定义了5种,而二进制要能够表示5种值最少要用3位。比如1位只能表示0和1,两位能表示00/01/10/11四种,那3位能表示的值则是2^3也就是8种,所以要标识5种状态则最少需要3位。
因为这一点,也限制了一个线程池理论上能设置的最大线程数是2^29-1个。
那如果想要从这一个字段里取出runState或者workCount的值应该怎么做的?

可以看到是通过位运算来实现的。这里先给大家插播一下位运算的逻辑。
- 按位与&:两数同为1则为1,其他情况为0,如0101& 0100 的结果是0100
- 按位或|:两数只要有1个是1,则为1,如 0101|0100的结果是0101
- 按位取反~:0变1,1变0,如0101按位取反则等于1010
要获取高位的runState则使用ctl的值c和容量(也就是2^29-1)取反做与运算;

取低位的workerCount则不用取反。

通过一个字段来表示两个概念,并且使用Atomic可以保证操作的原子性,不得不说Doug Lea,YYDS!!!

线程池初始化
通过ThreadPoolExecutor的构造方法我们来看一下线程池在创建的时候都做了些什么。
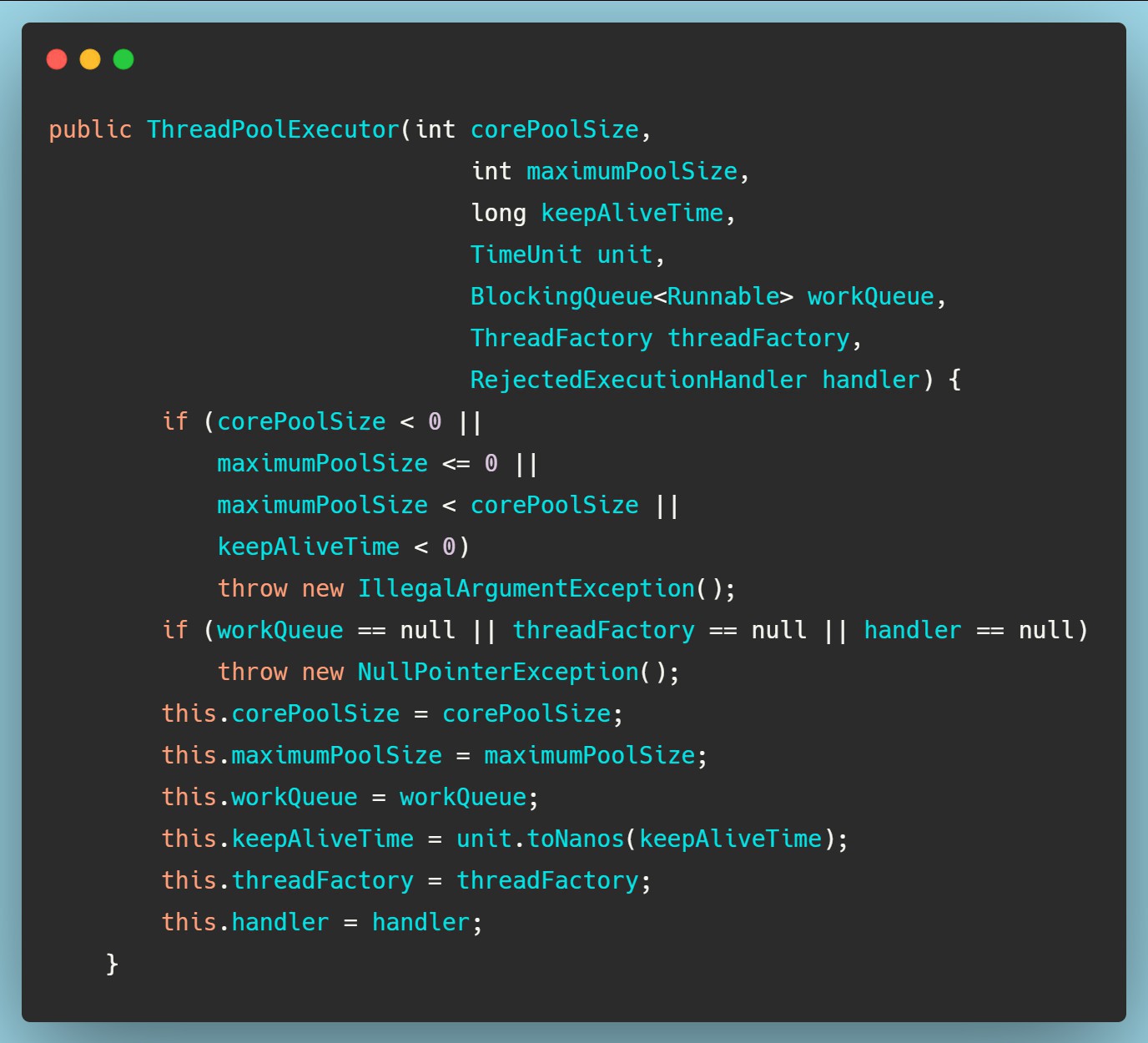
可以发现,在构造方法中只是对7个参数进行赋值,并没有去做线程的创建,所以在默认情况下,线程池创建后是没有线程的,需要在任务提交时才会创建线程。
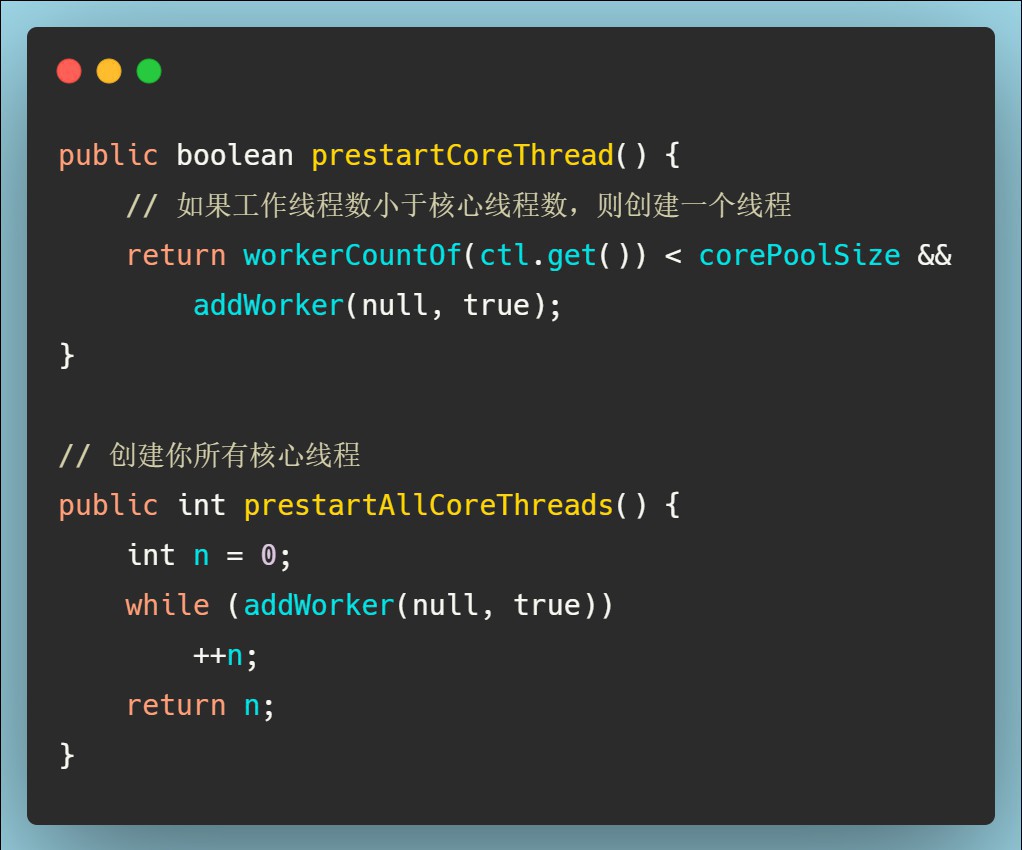
如果需要在线程池创建之后立即创建线程,ThreadPoolExecutor提供了两个方法可以实现:
如何执行任务
通过ThreadPoolExecutor执行任务时可以通过调用execute()方法和submit()方法来完成。
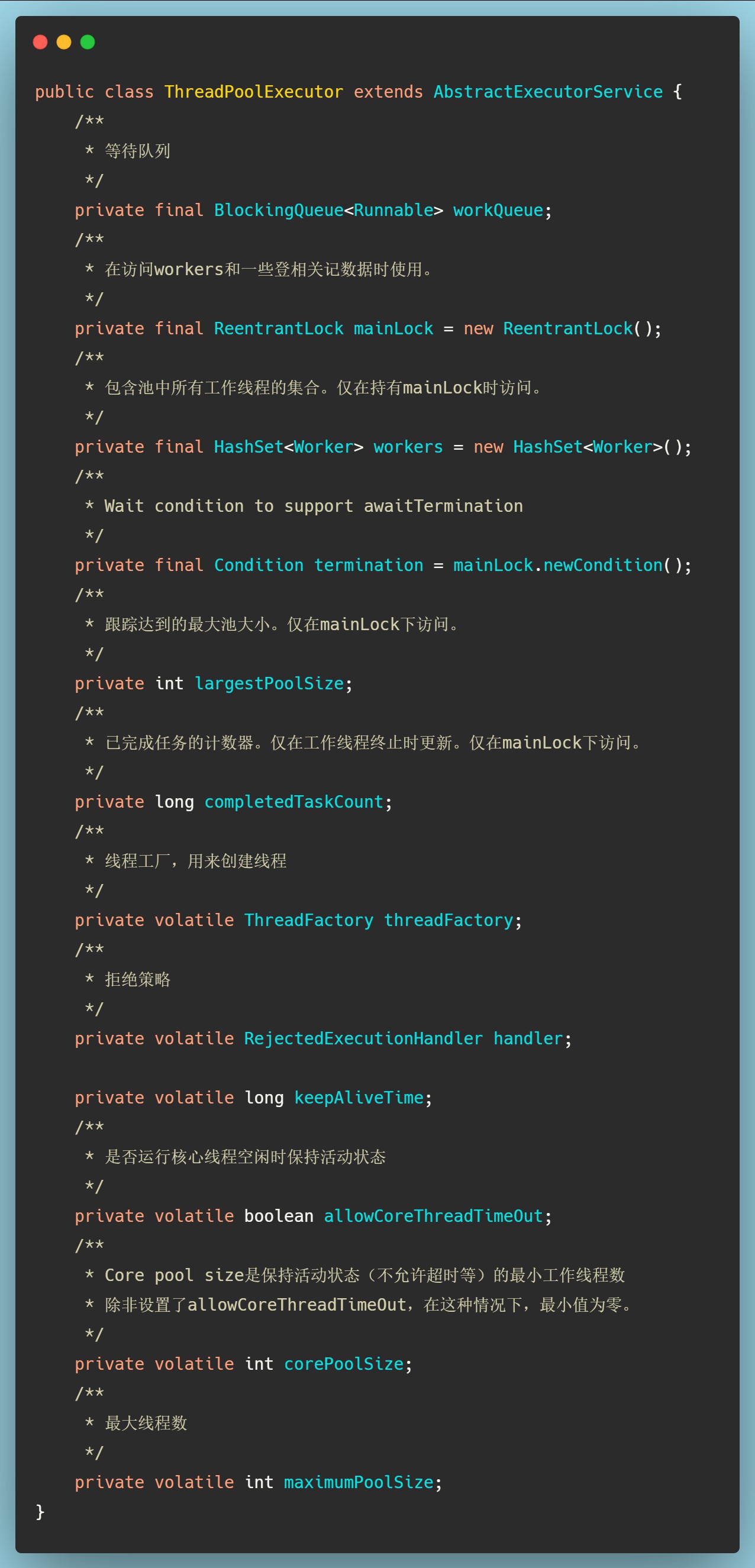
在这之前我们需要先知道ThreadPoolExecutor中一些比较重要的变量,可点开下图查看。
接下来我们来看execute()是如何执行任务的。

以上execute()方法的执行步骤可以总结为3步:
- 如果有效线程数workerCount小于核心线程数,则尝试增加一个线程执行当前任务,如果成功,则会在新线程中执行任务,如果失败,则执行下一步;
- 如果线程池状态是running,则尝试加入到等待队列,如果入队成功,则需要重新检查线程池状态是否是running,如果已经不是running则要将任务从队列中remove并按照拒绝策略处理;如果重新检查线程池状态是running,则要判断workCount是不是等于0,如果等于0则需要创建一个新的Worker用于执行刚入队的任务;
- 如果在第二步入队失败,会再次尝试增加一个Worker执行该任务,如果这里还是不行,则表示线程池确实shutdown或者等待队列满了,就执行拒绝策略。
有了这个整体之后,我们再进一步看看addWorker()方法,在这之前需要先了解Worker类的结构。
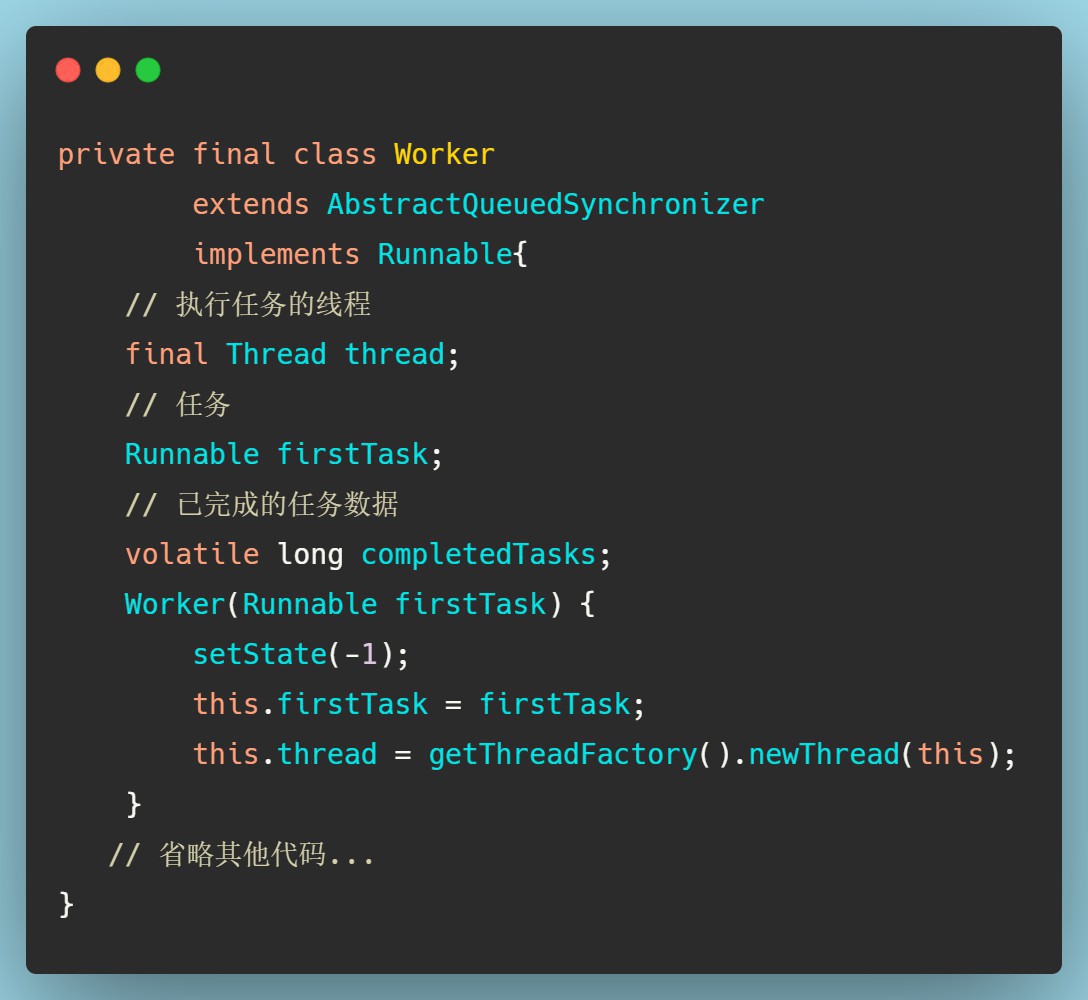
可以发现Worker类继承了AQS,并且实现Runnable接口,也就是说Worker对象可以交给一个Thread创建线程后执行。从Worker的构造方法里我们也能看出,thread是通过线程工厂创建一个线程,将this作为参数传递的。
然后我们再来看addWorker()方法:

简单总结一下addWorker()方法分以下4步:
- 如果线程池状态并且工作队列为空,则直接返回false,如果工作线程数workerCount小于核心线程数或者最大线程数(这里取决于传入的参数),则对workerCount自旋加1;
- 先加锁,然后将Worker加入到workerset中,解锁;
- 如果worker加入workerset成功,将线程启动;
- 如果线程启动失败,则将worke移除,workerCount原子减1
既然Worker类实现了Runnable方法,那对应run()方法中的逻辑就必须要看一下了。
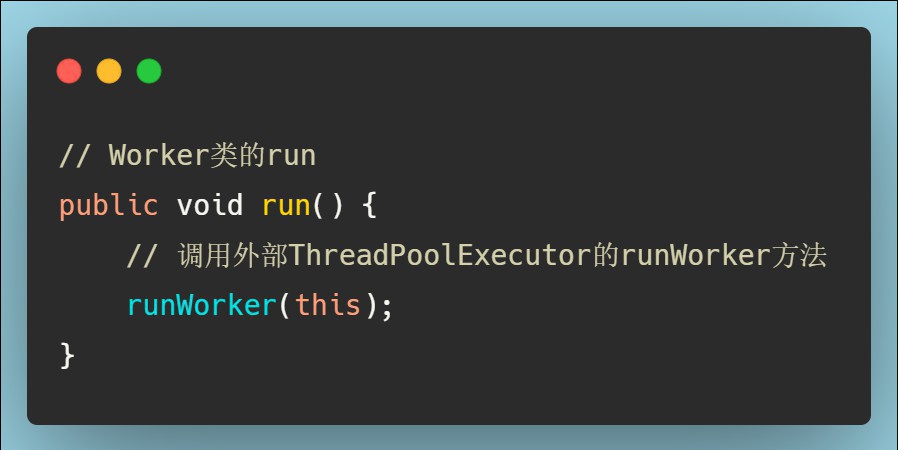
在Worker的run方法中直接调用外部类ThreadPoolExecutor的runWorker(Worker)方法。
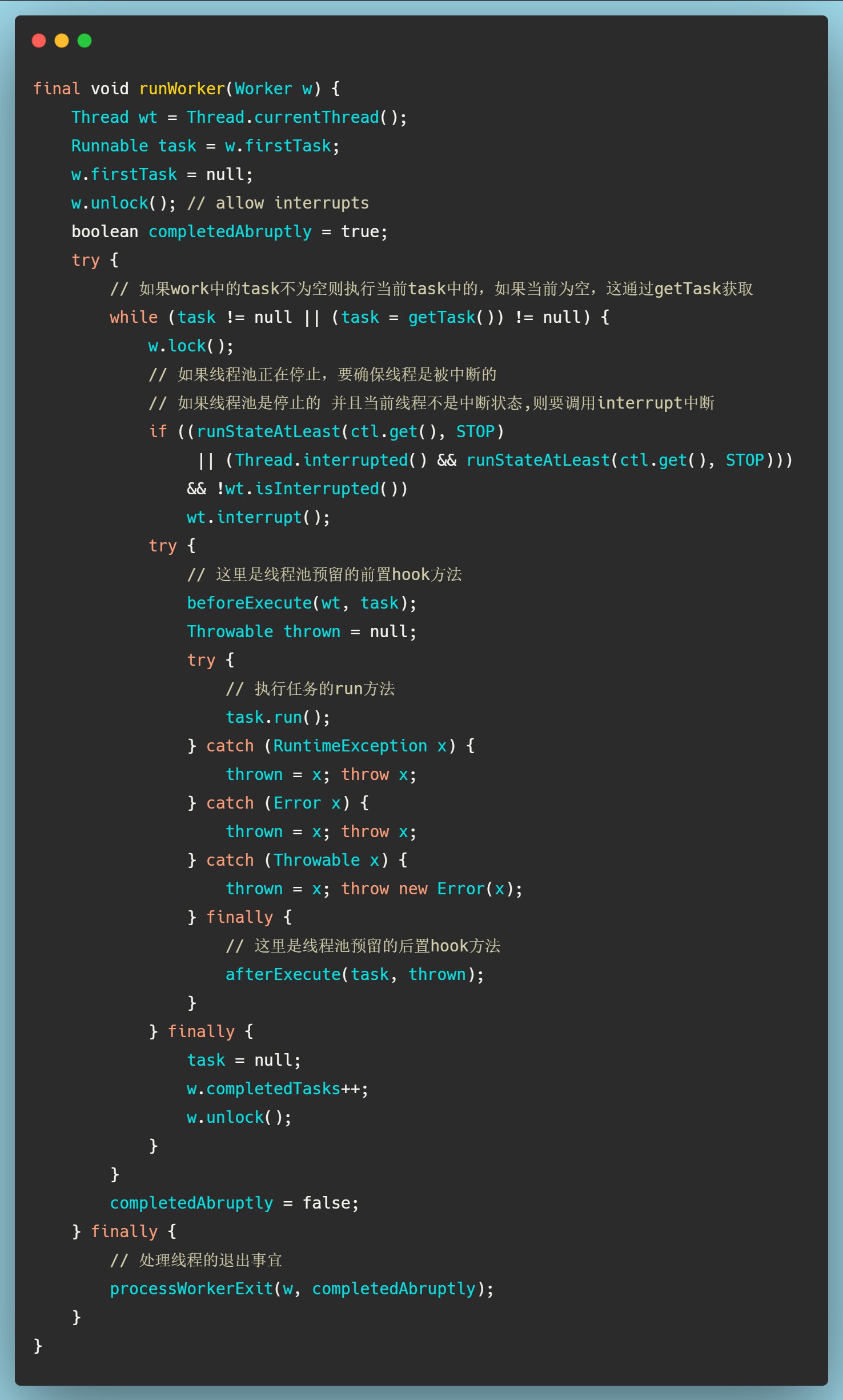
对runWorker()方法总结为以下几个步骤:
- 从传入worker对象的初始任务开始执行,如果初始任务为空则会调用
getTask()方法获取任务,如果返回空着该Worker线程则会退出;如果因为外部任务代码导致的异常抛出,则也会终止循环,但是不会将Worker线程退出; - 在运行任务之前都会获取锁防止其他任务执行时发生其他的池中断,并确保在池没有停止的情况下保证该线程不会设置其他中断;
- 每个运行任务都会调用
beforeExecute()方法,这个方法可能会抛出异常,这种情况下会导致任务不处理,并且线程会终止; - 如果
beforeExecute()正常执行,则会运行任务执行run(),在运行任务出抛出的异常和Error等会收集在thrown变量上,传给afterExecute(); run()执行完之后会执行afterExecute()如果该方法抛出异常同样会让线程终止。
那么getTask()是去哪里获取任务呢?当然是从等待队列中获取。
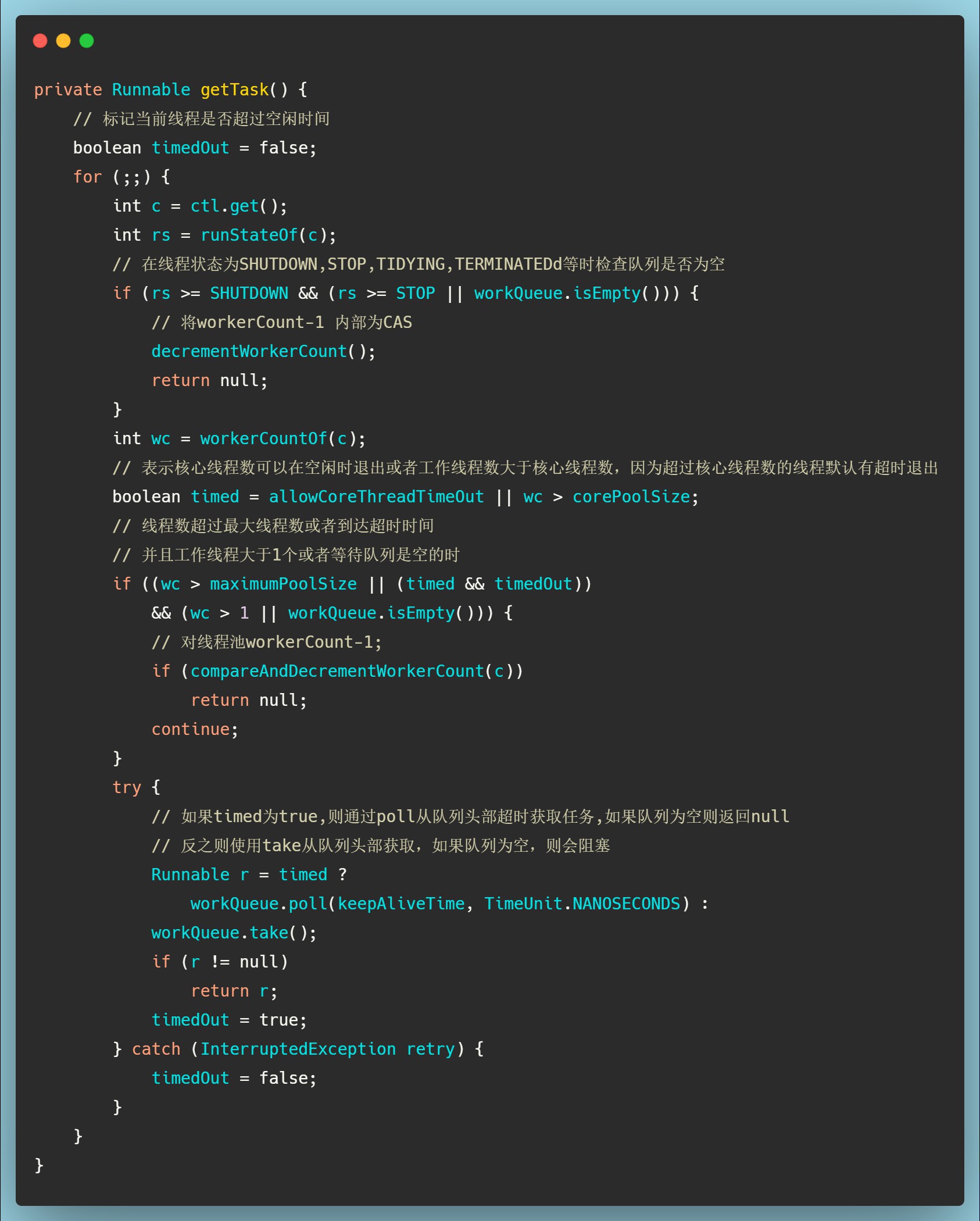
getTask()的执行可以总结如下:
- 会根据当前线程池设置的核心线程数,最大线程数,超时时间等,从任务队列获取任务,可能会超时等待,也可能会阻塞知道任务到达;
- 如果线程池STOP,或者有超过最大线程数的工作线程,或者线程是SHUTDOWN并且队列为空,或者在超时等待任务时超时这4种情况下会返回空。
钩子方法
在线程池执行任务的runWorker(Worker)方法中我们发现,会在任务执行前和执行后有两个方法。

从方法签名上可以看到这两个方法都是protected的,当时在ThreadPoolExecutor中都没有具体实现。所以这两个方法主要用于在自定义线程池时覆盖,可以在任务执行前和执行后做一些事情。比如初始化threadLocals,收集统计信息,打印日志等。需要注意的是这两个方法中如果抛出异常都会使线程终止。
另外,ThreadPoolExecutor中的terminated()也可以被覆盖,可以用于在线程完全终止后执行一些特殊处理。
等待队列和排队策略
在上面的内容中很多次的提到了等待队列,也就是ThreadPoolExecutor中的workQueue,用来存放等待执行的任务。
workQueue的类型定义为BlockingQueue<Runnable>通过可以使用以下的三种类型。
有界队列
有界队列顾名思义就是有边界的队列,需要指定队列的大小,主要有ArrayBlockingQueue和PriorityBlockingQueue。PriorityBlockingQueue的优点是等待队列中的任务可以按照任务的优先级处理。
有界队列的大小设置需要和线程池大小相互配合,线程池较小队列较大时,可以减少内存消耗,降低线程切换次数和CPU的使用率,但是可能会限制系统的吞吐量,所以要结合实际场景考虑如何设置。
无界队列
队列的大小没有限制,常用的有LinkedBlockingQueue,使用该队列是要谨慎,当任务比较耗时时,可能会导致大量任务堆积在队列中导致内存溢出。使用Executors.newFixedThreadPool创建的线程池就是使用的LinkedBlockingQueue。
同步移交队列
如果不希望队列等待,而是直接交给工作线程执行,则可以使用同步移交队列SynchronousQueue,该队列实际不会存放元素,要放入时必须有另一个现在在等待接收元素才能成功,在这之前会一直阻塞。
自定义拒绝策略
上一期我们有讲到过线程池的4种拒绝策略。
- AbortPolicy:拒绝处理,抛出异常
- CallerRunsPolicy:由创建该线程的线程(main)执行
- DiscardPolicy: 丢弃,不抛出异常
- DiscardOldestPolicy:和最早创建的线程进行竞争,不抛出异常
当然我们也可以自定义拒绝策略,比如我们在拒绝策略中做一些日志记录等自定义的需求。

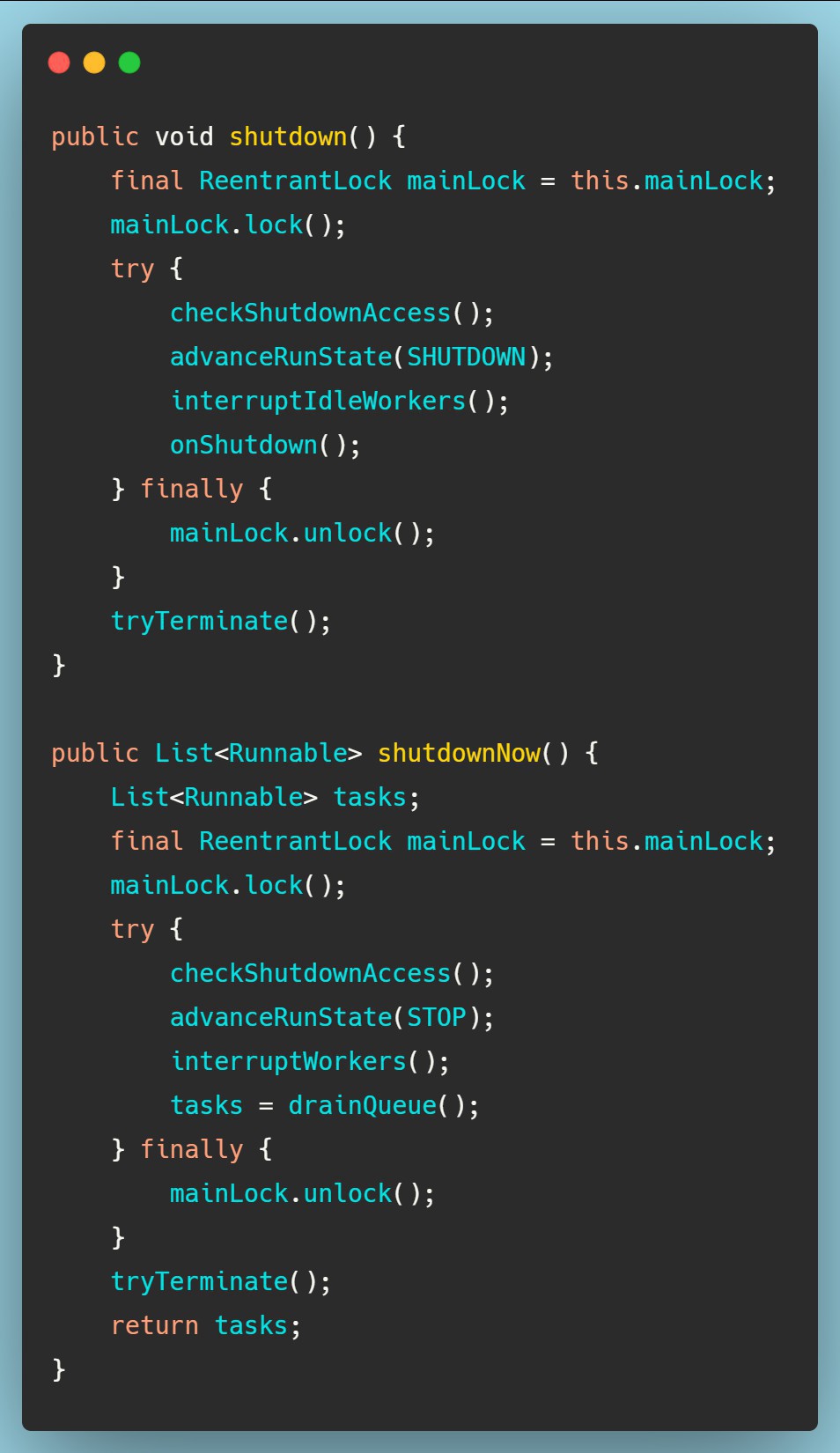
线程池关闭
ThreadPoolExecutor中有两个方法可以让线程池关闭,如下:
- shutdown():不会立即终止线程池,而是要等所有任务缓存队列中的任务都执行完后才终止,但再也不会接受新的任务
- shutdownNow():立即终止线程池,并尝试打断正在执行的任务,并且清空任务缓存队列,返回尚未执行的任务
动态调整容量
ThreadPoolExecutor提供了动态调整线程池容量大小的方法:setCorePoolSize()和setMaximumPoolSize()。
- setCorePoolSize:设置核心池大小,如果设置的值小于核心线程数,则多余线程会在下一次空闲时终止,如果设置的值较大,并且等待队列中有任务,则会立即创建线程执行等待队列中的任务。
- setMaximumPoolSize:设置线程池最大能创建的线程数目大小,如果新值小于当前的最大线程数,则多余的线程会在下次空闲时终止。
配置线程池大小
那么最后我们来说一下应该如何来配置线程池的大小呢?或许大多数程序员都听过这样一种说法:
- CPU 密集型应用,线程池大小设置为 CPU核数 + 1
- IO 密集型应用,线程池大小设置为 2*CPU核数
到底对不对呢?
我认为是不对的,因为在实际场景中,一台服务器可能都不止一个应用,而这两个公式都只和CPU核数相关,所以肯定是不正确的,只有在一台服务器只部署一个应用时才能勉强说的通;还有一个原因就是在一个应用中可能不仅仅是CPU密集型或者IO密集型,可能二者都有,那又该如何选择呢?以及一个应用中可能会按照功能划分多个线程池,所以最终结论我觉得这两种说法不对。
那么我们到底应该如何设置线程池的大小呢?有没有什么可以实践的方法,这里需要给大家介绍一个理论知识。
利特尔法则 (Little”s Law)

一个系统请求数等于请求的到达率与平均每个单独请求花费的时间之乘积
别看这个名字感觉很高大上,其实概念很简单。
结合到我们的场景中,我们设定单位时间为1秒钟来计算,λ=每秒收到的请求数,W=每个任务执行的时间,L=λW=每秒平均在系统中运行的线程。
假设我们的应用是单核的,则可以直接将L设置为线程池大小,但是真实情况并不是,那么多个CPU对我们这个公式中的哪部分数据会有影响呢?
主要是对于W的值有影响,需要知道一个请求中的线程IO时间和线程CPU时间。带入公式后则是:
λ=((IO时间+CPU时间)/CPU时间)*CPU个数
那么需要获得IO时间和CPU时间,则需要通过在代码中进行埋点才能准确获得,比如通过AOP切面编程在请求前后获取时间得到结果。
当然,仅仅依靠这个公式还是不够的,还需要通过压力测试进行调整和检验,才能更准确的配置。
以上就是本期的全部内容,我们下期见,关注我的公众号【小黑说Java】,更多干货内容。
