Python实用工具,fuzzywuzzy模块,Python实现鲁迅名言查询系统


前言:
有媒体报道北京鲁迅博物馆官网资料查询在线检索系统可以实现“鲁迅说过的话,可以一键查询”功能。听说报道出来第二天,系统就被挤瘫痪了。当时就在想自己能不能也做一个简单的查询系统来玩玩。让我们愉快地开始吧~

开发工具
Python版本:3.6.4
相关模块:
PyQt5模块;
python-Levenshtein模块;
fuzzywuzzy模块;
以及一些Python自带的模块。
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
原理简介
首先,下载一份鲁迅全集的.txt文件:

然后用PyQt布局实现个简单的GUI:
"""简单的GUI"""
class GUI(QWidget):
def __init__(self, parent=None):
super().__init__()
self.setWindowTitle("鲁迅名言查询-微信公众号:Charles的皮卡丘")
self.setWindowIcon(QIcon("data/icon.jpg"))
self.label1 = QLabel("句子:")
self.line_edit = QLineEdit()
self.label2 = QLabel("查询结果:")
self.text = QTextEdit()
self.button = QPushButton()
self.button.setText("查询")
self.cmb = QComboBox()
self.cmb.setStyle(QStyleFactory.create("Fusion"))
self.cmb.addItem("匹配度: 100%")
self.cmb.addItem("匹配度: 90%")
self.cmb.addItem("匹配度: 80%")
self.cmb.addItem("匹配度: 70%")
self.grid = QGridLayout()
self.grid.setSpacing(12)
self.grid.addWidget(self.label1, 1, 0)
self.grid.addWidget(self.line_edit, 1, 1, 1, 38)
self.grid.addWidget(self.button, 1, 39)
self.grid.addWidget(self.label2, 2, 0)
self.grid.addWidget(self.text, 2, 1, 1, 40)
self.grid.addWidget(self.cmb, 1, 40)
self.setLayout(self.grid)
self.resize(200, 400)
self.button.clicked.connect(self.inquiry)
self.paragraphs = self.loadData("data/book.txt")
大概长这个样子:
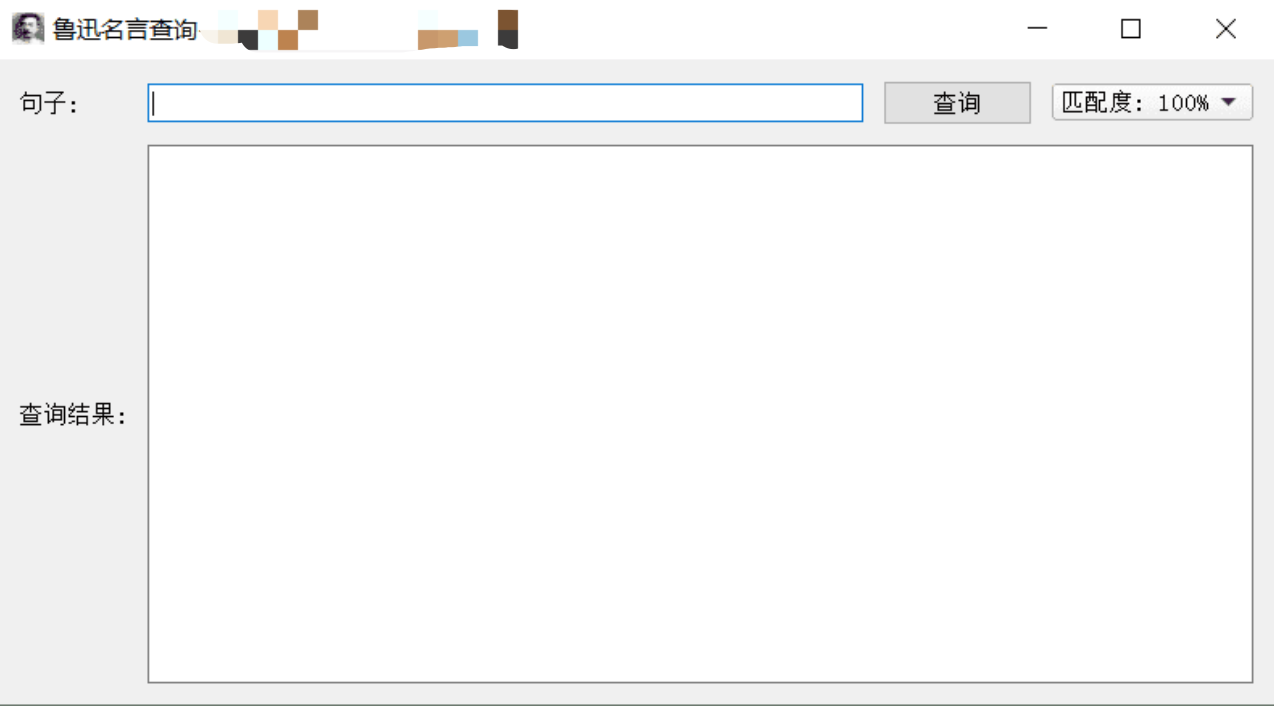
那么接下来,只需要当用户点击查询按钮时,根据用户选择的匹配度下限,找到鲁迅全集的book.txt文件中的所有与待搜索句子匹配度大于该匹配度下限的段落并在查询结果框中显示出来即可。
在这里投机取巧偷个懒,直接当调包侠了,即这里直接使用了python的fuzzywuzzy包。
fuzzywuzzy是一个可以对字符串进行模糊匹配的小工具,使用起来非常简单。
这里我们直接调用它的partial_ratio方法来匹配两段话的相似度,并将相似度大于给定阈值的所有段落显示在结果框中。具体而言,代码实现如下:
"""查询"""
def inquiry(self):
sentence = self.line_edit.text()
matched = []
score_thresh = self.getScoreThresh()
if not sentence:
QMessageBox.warning(self, "Warning", "请先输入需要查询的鲁迅名言")
else:
for p in self.paragraphs:
score = fuzz.partial_ratio(p, sentence)
if score >= score_thresh and len(sentence) <= len(p):
matched.append([score, p])
infos = []
for match in matched:
infos.append("[匹配度]: %d
[内容]: %s
" % (match[0], match[1]))
if not infos:
infos.append("未匹配到任何相似度大于%d的句子.
" % score_thresh)
self.text.setText("
".join(infos)[:-1])
文章到这里就结束了,感谢你的观看,关注我每天分享Python小工具系列,下篇文章不用声卡让电脑自己哼起歌
为了感谢读者们,我想把我最近收藏的一些编程干货分享给大家,回馈每一个读者,希望能帮到你们。
干货主要有:
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
⑥ 两天的Python爬虫训练营直播权限
**All done~完整源代码+干货详见个人主页简介或私信获取
