Netty入门(一):ByteBuf

网络数据的基本单位总是字节。Java NIO 提供了 ByteBuffer 作为它的字节容器,但是这个类使用起来过于复杂,而且也有些繁琐。Netty 的 ByteBuffer 替代品是 ByteBuf,一个强大的实现,既解决了 JDK API 的局限性,又为网络应用程序的开发者提供了更好的 API
ByteBuf优势
- 它可以被用户自定义的缓冲区类型扩展
- 通过内置的复合缓冲区类型实现了透明的零拷贝
- 容量可以按需增长
- 在读和写这两种模式之间切换不需要调用 ByteBuffer 的 flip()方法
- 读和写使用了不同的索引
- 支持方法的链式调用
- 支持引用计数
- 支持池化
ByteBuf实现原理
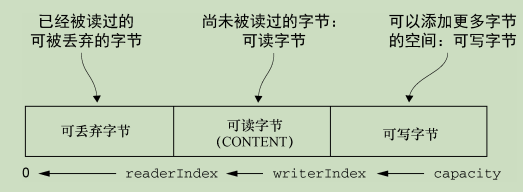
如图ByteBuf通维护了两个不同的索引:一个用于读取,一个用于写入。
当你从 ByteBuf 读取时,它的 readerIndex 将会被递增已经被读取的字节数。同样地,当你写入 ByteBuf 时,它的writerIndex 也会被递增
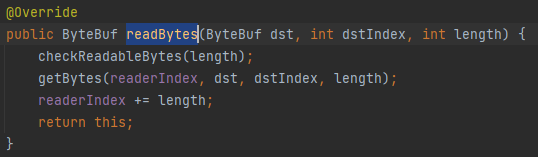
当调用readBytes时,readIndex会相应移动length位,如果readIndex移动后大于writeIndex则会抛异常。
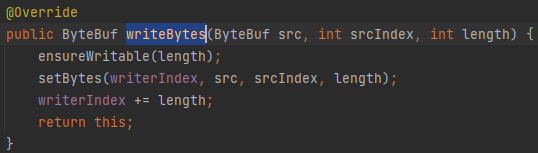
当调用writeBytes时,writeIndex会相应移动length位,且通过ensureWritable方法实现自动扩容
其他常用API
| getBytes | 获取可读字节数组 |
| setBytes | 写入字节 |
| discardReadBytes | 废弃已读字节 |
| mark | 标记index |
| reset | 将index重置到之前标记的位置(配合mark使用) |
| isReadable | 如果至少有一个字节可供读取,则返回 true |
| isWritable | 如果至少有一个字节可被写入,则返回 true |
| readableBytes | 返回可被读取的字节数 |
| writableBytes | 返回可被写入的字节数 |
| capacity | 返回 ByteBuf 可容纳的字节数。在此之后,它会尝试再次扩展直到达到 maxCapacity() |
| maxCapacity | 返回 ByteBuf 可以容纳的最大字节数 |
| hasArray | 如果 ByteBuf 由一个字节数组支撑,则返回 true |
| array | 如果 ByteBuf 由一个字节数组支撑则返回该数组;否则,它将抛出一个UnsupportedOperationException 异常 |
ByteBuf缓冲分类
1、Heap buffer(堆缓冲区):
就是将数据存在JVM堆空间中,在没有被池化的情况可以快速分配和释放。
优点:由于数据是存储在JVM堆中,因此可以快速的创建与快速的释放,并且它提供了直接访问内部字节数组的方法。
缺点:每次读写数据时,都需要先将数据复制到直接缓冲区中再进行网路传输。
2、Direct buffer(直接缓冲区):
直接缓冲区,在堆外直接分配内存空间,直接缓冲区并不会占用堆的容量空间,因为它是由操作系统在本地内存进行的数据分配。
优点:在使用Socket进行数据传递时,性能非常好,因为数据直接位于操作系统的本地内存中,所以不需要从JVM将数据复制到直接缓冲区中 。
缺点:因为Direct Buffer是直接在操作系统内存中的,所以内存空间的分配与释放要比堆空间更加复杂,而且速度要慢一些。
注意:
如果你的数据包含在一个在堆上的分配的缓冲区中,那么事实上,在通过套接字发送他之前,jvm将会在内部把你的缓冲区复制到一个直接缓冲区中;这样分配释放就比较浪费资源;
建议:
直接缓冲区并不支持通过字节数组的方式来访问数据。对于后端业务的消息编解码来说,推荐使用HeapByteBuf;对于I/O通信线程在读写缓冲区时,推荐使用DirectByteBuf;
3、Composite Buffer 复合缓冲区:
可以拥有以上两种的缓冲区,通过一种聚合视图来操作底层持有的多种类型Buffer。这种缓冲,jdk nio是没有这种特性的。
