Python爬虫实战,DecryptLogin模块,Python模拟登录抓取京东商品数据并实现数据可视化

前言:
今天再带大家简单爬一波京东的商品数据呗,废话不多说,让我们愉快地开始吧~
效果
开发工具
Python版本:3.6.4
相关模块:
DecryptLogin模块;
argparse模块;
以及一些python自带的模块。
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
原理简介
原理其实挺简单的,首先,我们利用之前开源的DecryptLogin库来实现一下微博的模拟登录操作:
"""模拟登录京东"""
@staticmethod
def login():
lg = login.Login()
infos_return, session = lg.jingdong()
return session
然后写几行简单的代码来保存一下登录后的会话,省得每次运行程序都要先模拟登录京东:
if os.path.isfile("session.pkl"):
print("[INFO]: 检测到已有会话文件session.pkl, 将直接导入该文件...")
self.session = pickle.load(open("session.pkl", "rb"))
self.session.headers.update({"Referer": ""})
else:
self.session = JDGoodsCrawler.login()
f = open("session.pkl", "wb")
pickle.dump(self.session, f)
f.close()
接着去京东抓一波包,一样的套路,有种屡试不爽的感觉:
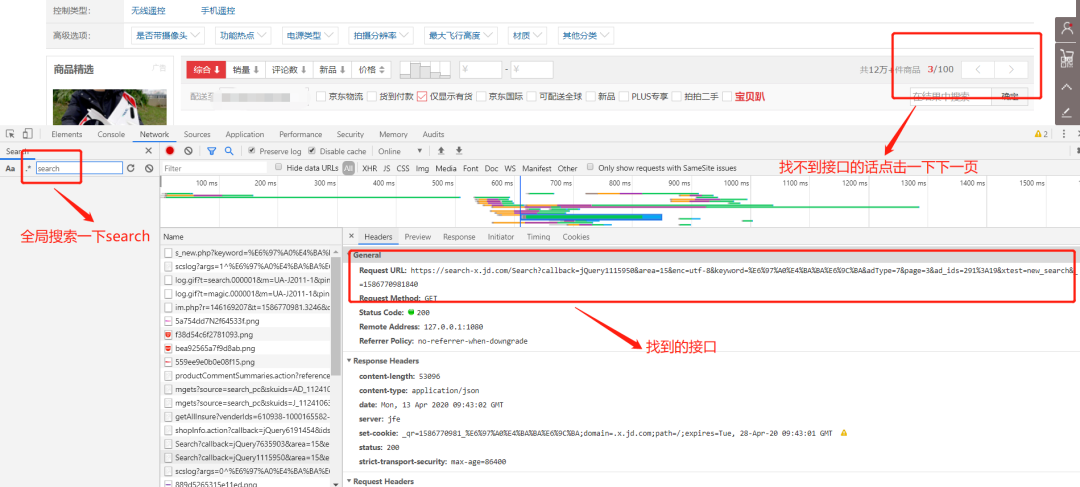
看看请求这个接口需要提交的参数:
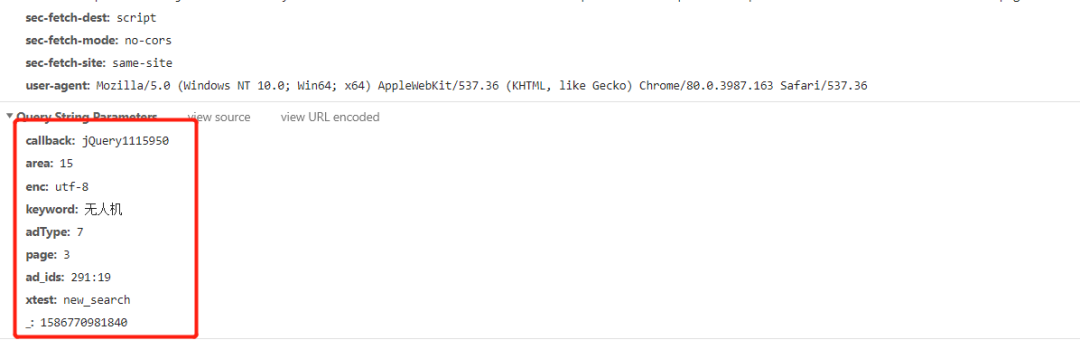
我们可以简单分析一下每个参数的含义:
area: 不用管,可以看作一个固定值
enc: 指定编码, 可以看作固定值"utf-8"
keyword: 搜索的关键词
adType: 不用管,可以看作一个固定值
page: 当前的页码
ad_ids: 不用管,可以看作一个固定值
xtest: 不用管,可以看作一个固定值
_: 时间戳
也就是说我们需要提交的params的内容大概是这样子的:
params = {
"area": "15",
"enc": "utf-8",
"keyword": goods_name,
"adType": "7",
"page": str(page_count),
"ad_ids": "291:19",
"xtest": "new_search",
"_": str(int(time.time()*1000))
}
构造好需要提交的params之后,只需要利用登录后的session去请求我们抓包得到的接口:
response = self.session.get(search_url, params=params)
然后从返回的数据里解析并提取我们需要的数据就可以了:
response_json = response.json()
all_items = response_json.get("291", [])
for item in all_items:
goods_infos_dict.update({len(goods_infos_dict)+1:
{
"image_url": item.get("image_url", ""),
"price": item.get("pc_price", ""),
"shop_name": item.get("shop_link", {}).get("shop_name", ""),
"num_comments": item.get("comment_num", ""),
"link_url": item.get("link_url", ""),
"color": item.get("color", ""),
"title": item.get("ad_title", ""),
"self_run": item.get("self_run", ""),
"good_rate": item.get("good_rate", "")
}
})
数据可视化
老规矩,可视化一波我们爬取到的数据呗。以我们爬取到的无人机商品数据为例。首先,我们来看看京东里卖无人机的自营店和非自营店比例:
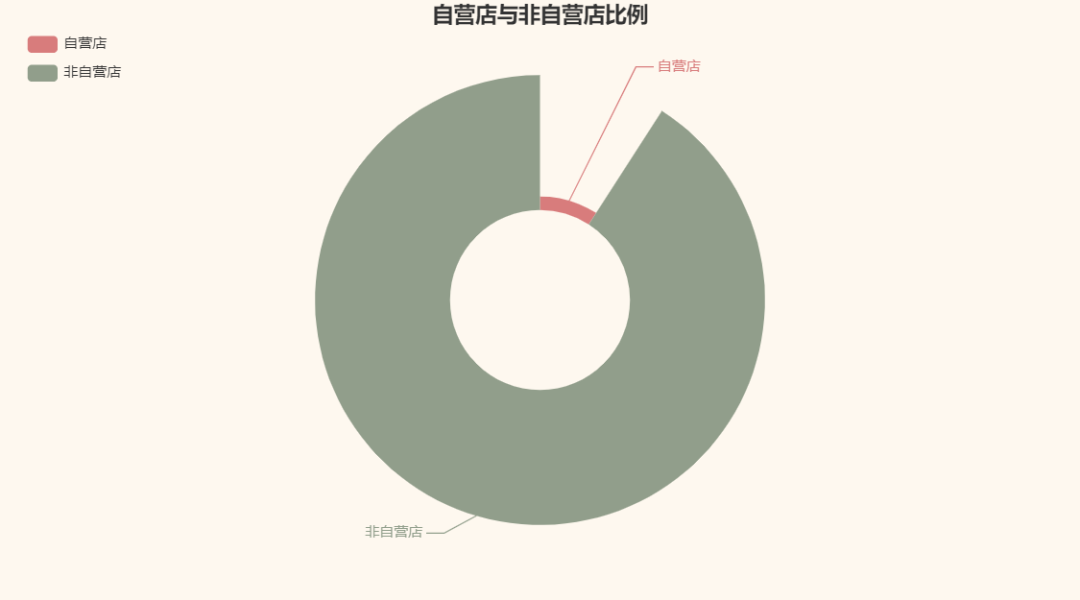
咦,竟然是非自营店占多。我一直以为京东基本都是自营店,虽然我基本不用京东。真是个天大的误解。
接着,我们再来看看京东自己给的商品排名前10的那几家店的商品评论数量:
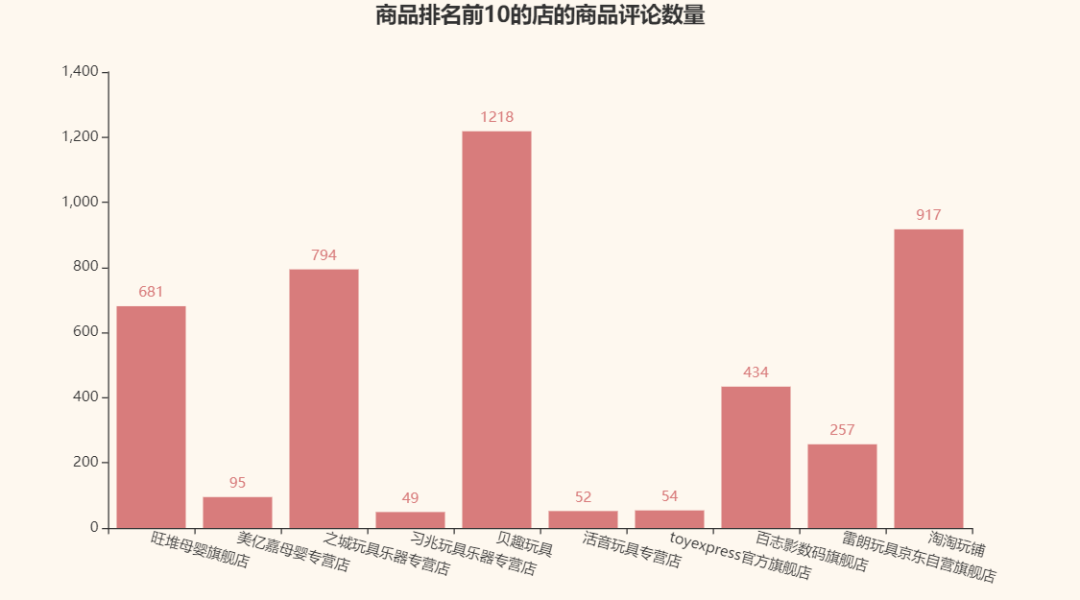
对比一下评论最多的店铺:
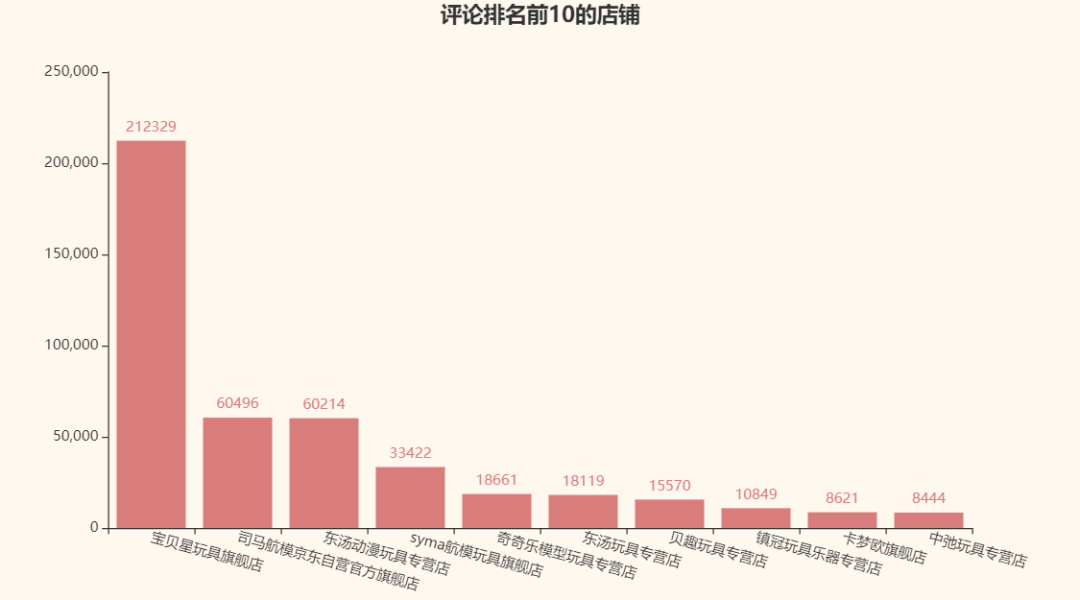
看来评论数量和京东给的商品排名并没有直接联系T_T,竟然没有一家店是重复的。
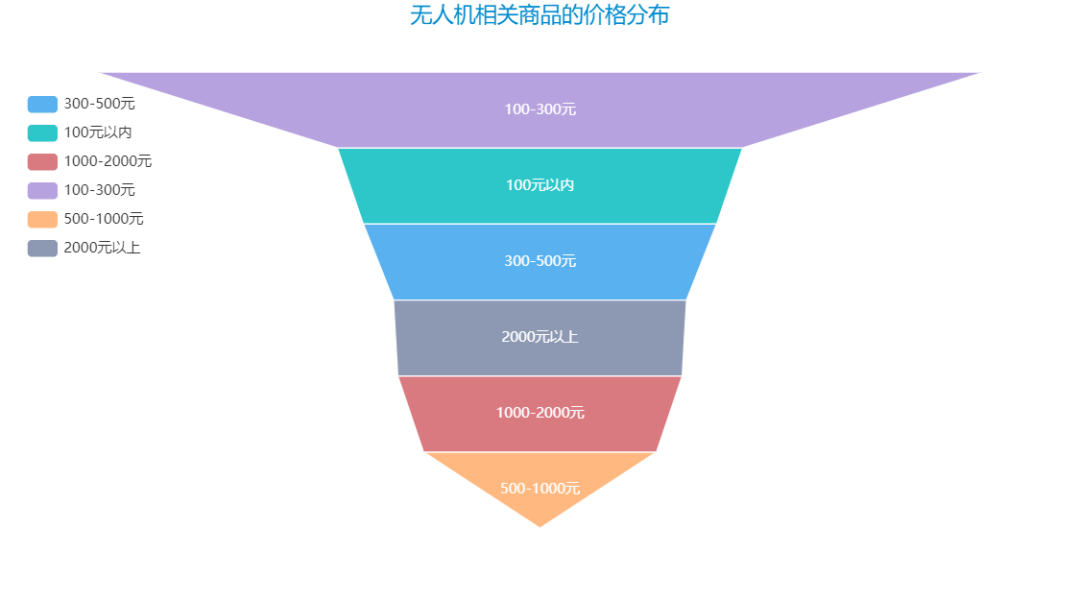
再来看看无人机相关商品的价格分布:
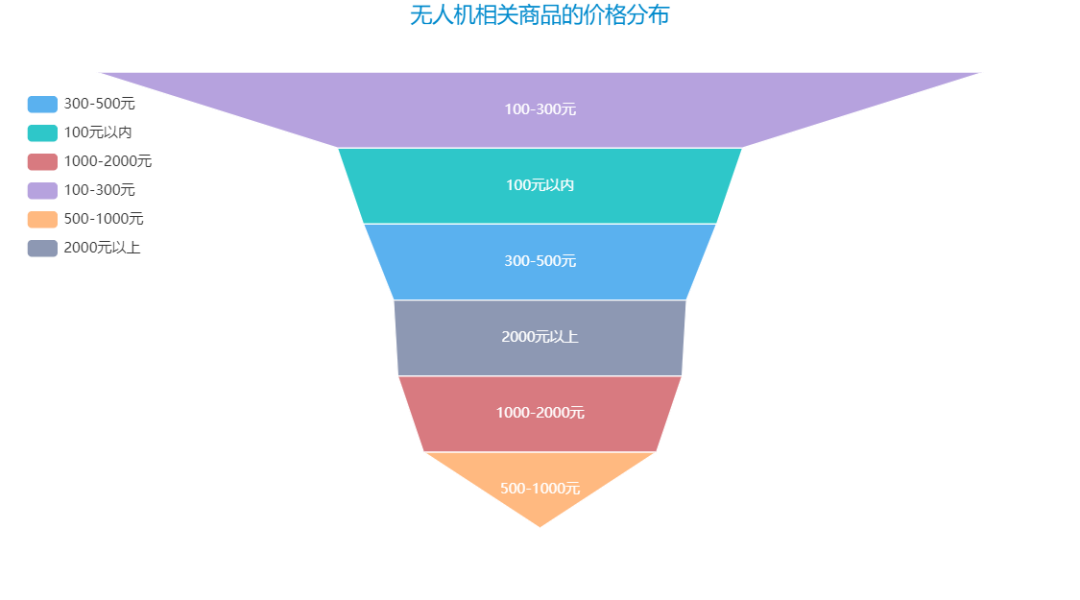
文章到这里就结束了,感谢你的观看,Python模拟登录系列系列,下篇文章分享删除批量微博。
为了感谢读者们,我想把我最近收藏的一些编程干货分享给大家,回馈每一个读者,希望能帮到你们。
干货主要有:
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
⑥ 两天的Python爬虫训练营直播权限
All done~点赞+评论~详见个人简介或者私信获取完整源代码。。