Python基础之爬取小说


近些年里,网络小说盛行,但是小说网站为了增加收益,在小说中增加了很多广告弹窗,令人烦不胜烦,那如何安静观看小说而不看广告呢?答案就是爬虫。本文主要以一个简单的小例子,简述如何通过爬虫来爬取小说,仅供学习分享使用,如有不足之处,还请指正。
目标页面
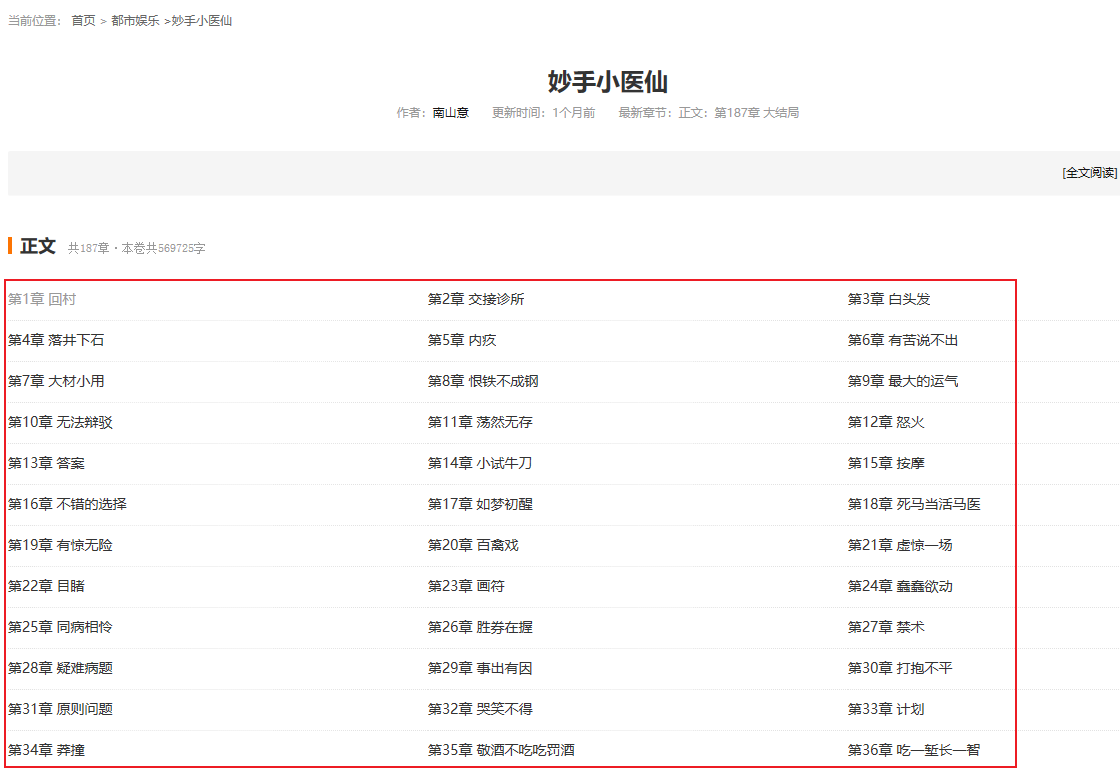
本文爬取的为【纵横中文网】的一部小说【妙手小医仙】,已完结,共187章,信息如下:
网址:http://book.zongheng.com/showchapter/1102448.html
本次主要爬取小说章节信息,及每一章对应的正文信息。章节信息如下所示:
目标分析
1. 章节目录分析
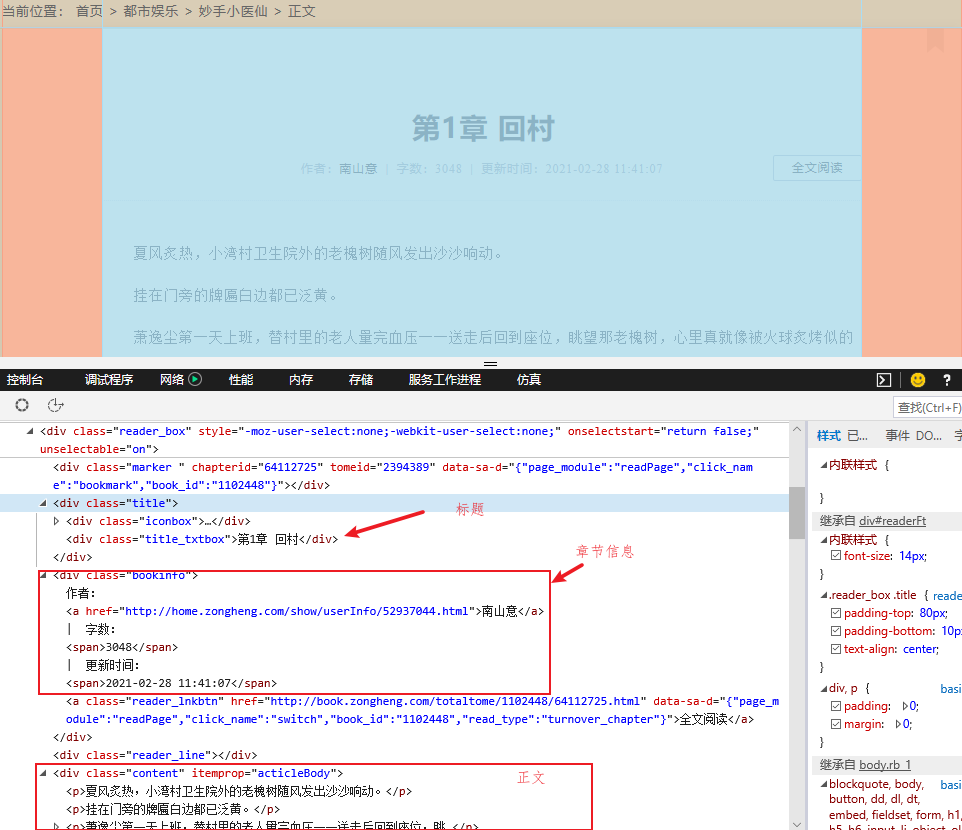
通过浏览器自带的开发人员工具【快捷键F12或Ctrl+Shift+I】进行分析,发现所有的章节都包含在ul【无序列表标签】中,每一个章节链接对应于li【列表项目标签】标签中的a【超链接标签】标签,其中a标签的href属性就是具体章节网址,a标签的文本就是章节标题,如下所示:

2. 章节正文分析
通过分析,发现章节全部内容,均在div【class=reader_box】中,其中包括标题div【class=title_txtbox】,章节信息div【class=bookinfo】,及正文信息div【class=content】,所有正文包含在p【段落标签】中。如下所示:
爬虫设计思路
- 获取章节页面内容,并进行解析,得到章节列表
- 循环章节列表:
- 获取每一章节内容,并进行解析,得到正文内容,
- 保存到文本文档。每一个章节,一个文档。
示例源码
获取请求页面内容,因为本例需要多次获取页面内容,所以封装为一个单独的函数,如下所示:
1 def get_data(url: str = None):
2 """
3 获取数据
4 :param url: 请求网址
5 :return:返回请求的页面内容
6 """
7 # 请求头,模拟浏览器,否则请求会返回418
8 header = {
9 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
10 "Chrome/70.0.3538.102 Safari/537.36 Edge/18.18363"}
11 resp = requests.get(url=url, headers=header) # 发送请求
12
13 if resp.status_code == 200:
14 if resp.encoding != resp.apparent_encoding:
15 # 如果返回的编码和页面显示编码不一致,直接获取text会出现乱码,需要转码
16 return resp.content.decode(encoding=resp.apparent_encoding)
17 else:
18 # 如果返回成功,则返回内容
19 return resp.text
20 else:
21 # 否则,打印错误状态码,并返回空
22 print("返回状态码:", resp.status_code)
23 return
