你文件乱码了么


之前对文件的编码,解码一直停留在很抽象的层面,就想着各种编码方式,什么gbk,utf8,ascii等等,然后什么方式编码,就用什么方式解码,比较模糊的,而且项目中uft8编码无处不在,今天突然学习了一下,突然有种恍然大悟的感觉,做个笔记,嘿嘿╮(╯_╰)╭
1.初始阶段
首先我们要知道计算机最开始是用来干什么的?是用来计算的,而数字天生就可以用于转换成二进制的0和1,所以这个时候完全没有编码的概念,总不可能在中国的100和国外的100代表的数量不同吧….
但是技术的发展,使得计算机需要处理文字信息,最开始就是在美国,他们就在想着怎么让计算机处理文字….
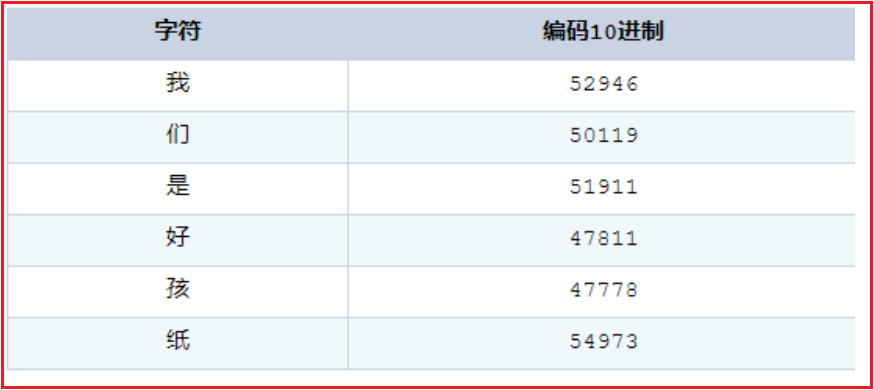
有个方法就是统计一下所有单词,给每个单词编个号,分别是1,2,3…..,但是一想,没必要这样给单词编号,英语单词最本质的不就是26个字母吗,加上大小写、特殊符号 一共也就一百多个字符,直接给每个字符进行编号1,2,3,4….,而一个字节的范围是0-255,足够用于给那100多个字符编号了,于是就有人写下了一张表,下图所示:
注:Char就是字符,Dec就是对应的十进制数字,所有的字符+特殊符号刚好是128个,就完成了对每个字符进行编号,然后我们在计算机中文本中输入:hello,每个字母都表示一个编号,对应的十进制编号是:104,101,108,108,111,存储肯定需要5个字节

使用飘准点的普通话来说:这张表全称”美国信息交换标准代码标准(American Standard Code for Information Interchange)”,简称ASCII表,ASCII码字符集总共的编码有128个,包括32个通用控制符,10个十进制数码,52个英文大小写字母和34个专用符号。
2.发展中阶段
如果计算机只有美国在使用,那肯定啥问题没有,但是慢慢普及了之后,每个国家都有自己的电脑了;
每个国家都有每个国家的文字,总不能让每个国家用电脑的时候都使用英语吧….比如我们中国用的是汉字,那怎么样在计算机中处理汉字呢?简单呀,美国之前不是已经做过了类似的事了么,我们仿照着来一遍不就行了么
于是我们国家就把每个汉字都用数字进行编号,但是汉字数量太多,常用字+生僻字一起就有两万多个吧,而一个字节最大也就只能表示0-255,比较拉胯,一个不行就用两个,那就用两个字节表示一个汉字吧!两个字节2^16=65536,足够给每个汉字和特殊字符编号使用了吧(这里就不说分区了,有兴趣的自己去了解),于是中国版的ascii表就出来了,弄了个全新的名字,表示是我们专用:GBK
可以去这个地方去玩玩编码:点击这里๑乛◡乛๑
肯定不会只有我们中国人这么聪明知道去创建张表,其他国家也不都是笨蛋呀,就好像秦国的商鞅变法的时候,其他六国肯定也没闲着看戏,都在各种变法呀!
于是每个国家都弄了一张对应他们国家文字的表,比如日本的就叫做Shift_JIS,韩国的就叫做KSC,于是间各国纷纷跟进,各种对应的表层出不穷,就连香港和台湾也有自己的编码表:BIG5
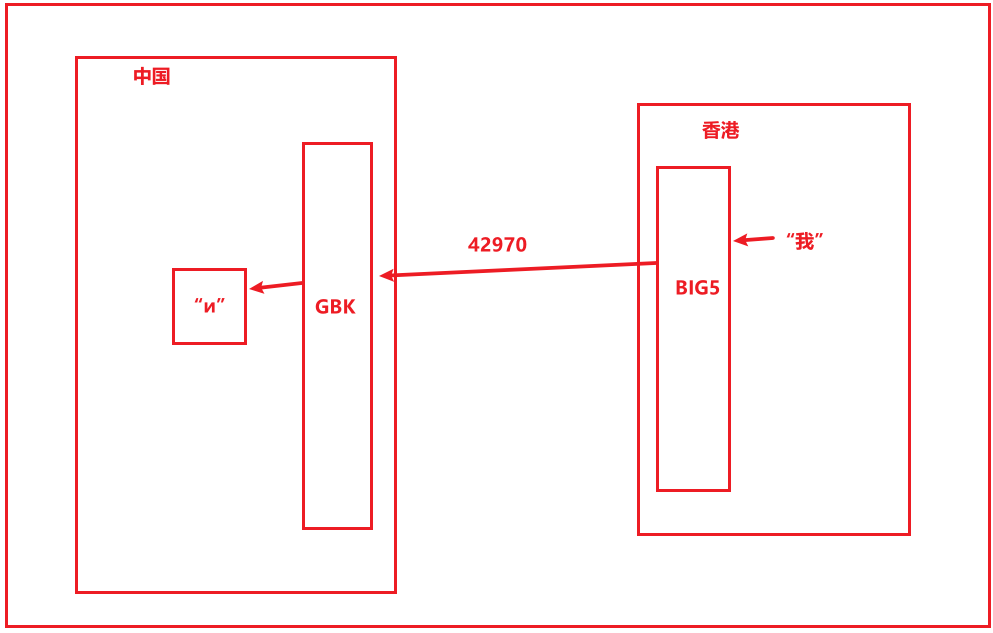
例如你在香港写的一个文本文件,发送到大陆这边来,你觉得看得懂么?
示例:你在香港那边输入了一个”我”,这个字BIG5编码对应的十进制是42970,然后将42970传到大陆这边,你打开文件的时候,计算机就会根据42970在GBK表中找到对应的汉字为“и”,你看不懂吧,没错,你就是乱码了,下图所示,想要看得懂,我们只需要将GBK换成BIG5就行了
3.大一统阶段
各个国家的编码表都不一样,很混乱,但是总会有人出来一统天下,于是就有人出来说话了:你们别搞花里胡哨的了,我用一张表把你们所有国家的文字、符号等等都给包含了得了,你们就用我这个吧!
所以就出现了一张贼鸡儿大的表:Unicode,俗称的万国码,这张表有多大呢?你想想你要对人类世界所有的文字,符号都进行编码,两个字节最大也就是65536,肯定不够用了;那就特喵的再加一个字节,3个子节,最大表示一千多万,肯定还是不够;那就继续加个字节,4个字节,最大将近就有43亿了,差不多就够了;
那么问题来了,原本一个英文字母只需要1个字节,一个汉字只需要2个字节,你现在都给我统统弄成4个字节,存储量翻倍了…所以我们需要对Unicode进行一定的处理,这种处理方式就是UTF8,这是可变的编码;
什么叫做可变的呢?就是说使用了UTF8编码之后,如果是英语字母,那就使用一个字节存储,如果是汉字,那就使用三个字节存储;当然为了和国际接轨,使用UTF8之后汉字比GBK多一个字节也勉强能接受;
所以在记事本中输入:hello你好, 使用UTF8编码, 占用的字节是5+3+3=11
这里只是简单的介绍一下,关于各种编码的相关知识真的是很多很多,感兴趣的一定要自己去多学习( ̄▽ ̄)ノ
