Python基础之爬取豆瓣图书信息


概述
所谓爬虫,就是帮助我们从互联网上获取相关数据并提取有用的信息。在大数据时代,爬虫是数据采集非常重要的一种手段,比人工进行查询,采集数据更加方便,更加快捷。刚开始学爬虫时,一般从静态,结构比较规范的网页入手,然后逐步深入。今天以爬取豆瓣最受关注图书为例,简述Python在爬虫方面的初步应用,仅供学习分享使用,如有不足之处,还请指正。
涉及知识点
如果要实现爬虫,需要掌握的Pyhton相关知识点如下所示:
- requests模块:requests是python实现的最简单易用的HTTP库,建议爬虫使用requests。关于requests模块的相关内容,可参考官方文档及简书上的说明
- BeautifulSoup模块:Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库。它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式。关于BeautifulSoup的更多内容,可参考官方文档。
- json模块:JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,易于人阅读和编写。使用 JSON 函数需要导入 json 库。关于json的更多内容,可参考菜鸟笔记。
- re模块:re模块提供了与 Perl 语言类似的正则表达式匹配操作。关于re模块的更多内容,可参考官方文档。
目标页面
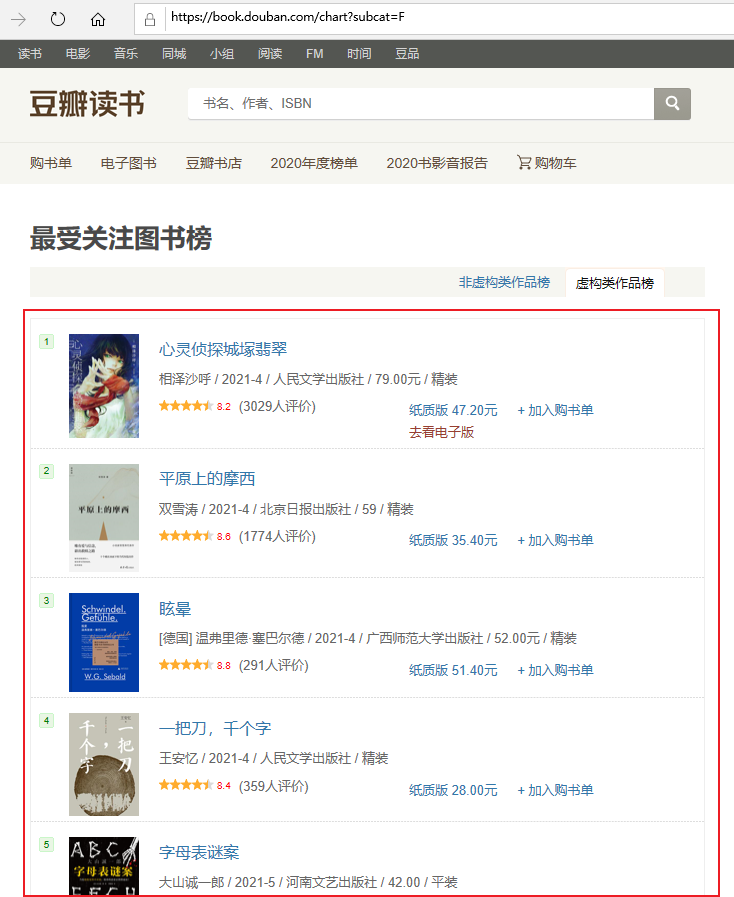
本例中爬取的信息为豆瓣最受关注图书榜信息,共10本当前最受欢迎图书。
爬取页面URL【Uniform Resource Locator,统一资源定位器】:https://book.douban.com/chart?subcat=F
爬取页面截图,如下所示:
爬取数据步骤
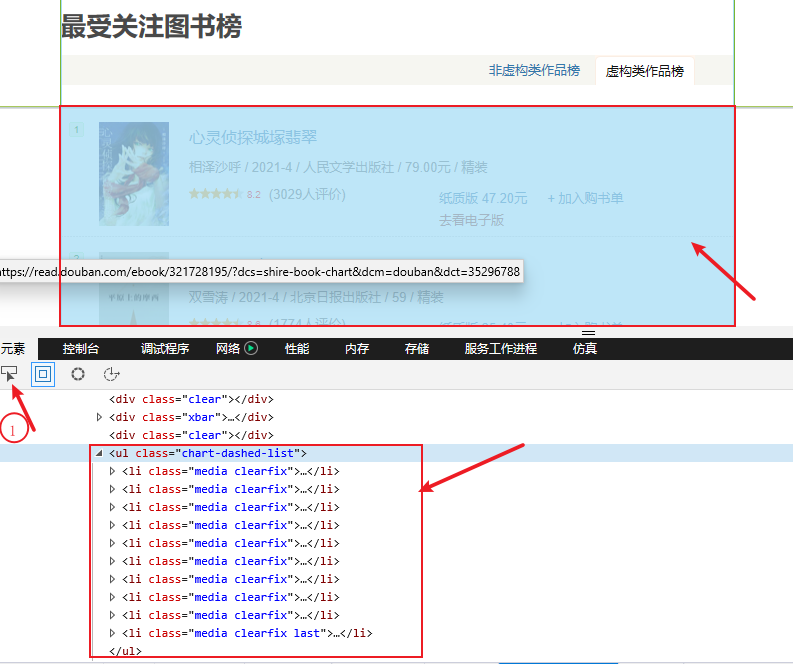
1. 分析页面
通过浏览器提供的开发人员工具(快捷键:F12),可以方便的对页面元素进行定位,经过定位分析,本次所要获取的内容,包括在UL【class=chart-dashed-list】标签内容,每一本书,都对应一个LI元素,是本次爬取的目标,如下所示:
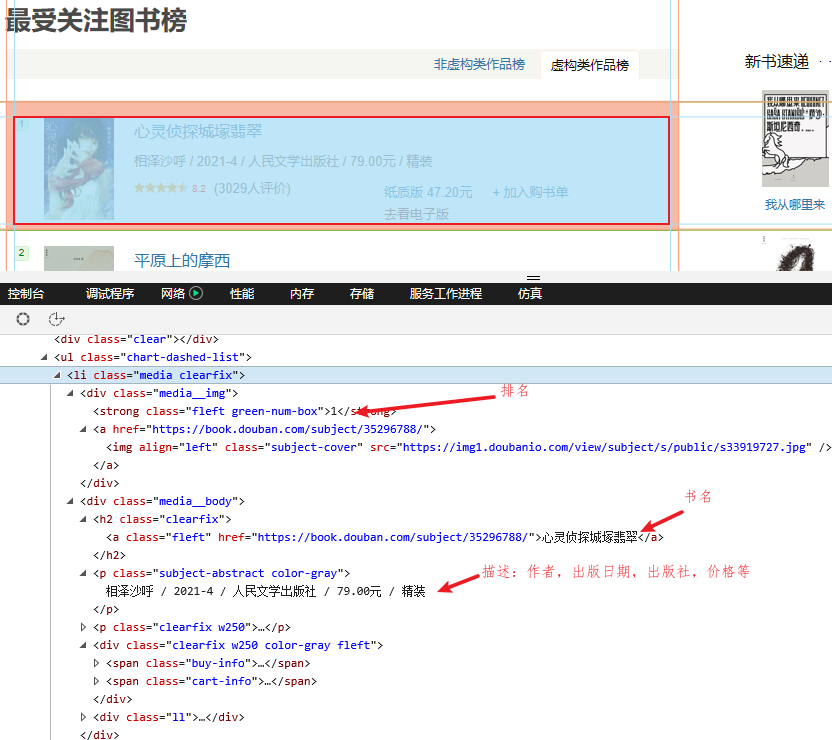
每一本书,对应一个Li【class=media clearfix】元素,书名为对应a【class=fleft】元素,描述为P【class=subject-abstract color-gray】标签元素内容,具体到每一本书的的详细内容,如下所示:
2. 下载数据
如果要分析数据,首先要进行下载,获取要爬取的数据信息,在Python中爬取数据,主要用requests模块,如下所示:
1 def get_data(url):
2 """
3 获取数据
4 :param url: 请求网址
5 :return:返回请求的页面内容
6 """
7 # 请求头,模拟浏览器,否则请求会返回418
8 header = {
9 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
10 "Chrome/70.0.3538.102 Safari/537.36 Edge/18.18363"}
11 resp = requests.get(url=url, headers=header) # 发送请求
12 if resp.status_code == 200:
13 # 如果返回成功,则返回内容
14 return resp.text
15 else:
16 # 否则,打印错误状态码,并返回空
17 print("返回状态码:", resp.status_code)
18 return ""
