Python爬虫实战,wordcloud模块,简单分析Chrome浏览器浏览记录


前言
利用Python简单分析一下Chrome浏览器的网页浏览记录,我们一起愉快的学习吧。

开发工具
Python版本:3.6.4
相关模块:
pyecharts模块;
wordcloud模块;
以及一些Python自带的模块。
DB.Browser版本:3.11.0
环境搭建
关于python:
安装Python并添加到环境变量,pip安装需要的相关模块即可。
关于DB.Browser:
下载地址:
https://github.com/sqlitebrowser/sqlitebrowser/releases
建议下载免安装版本的(相关文件中也提供了免安装版本)。
原理简介
Chrome浏览器的网页浏览历史记录一般保存在:
C:Users<USERNAME>AppDataLocalGoogleChromeUserDataDefaulthistory
利用DB.Browser打开它,发现与历史浏览记录相关的表有urls和visits:
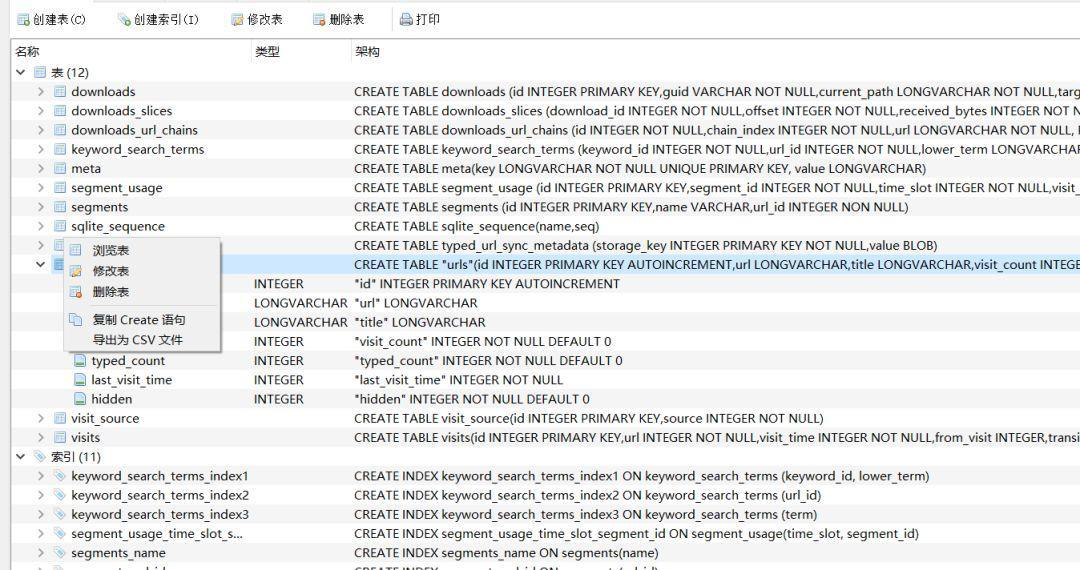
打开观察一下表的结构:
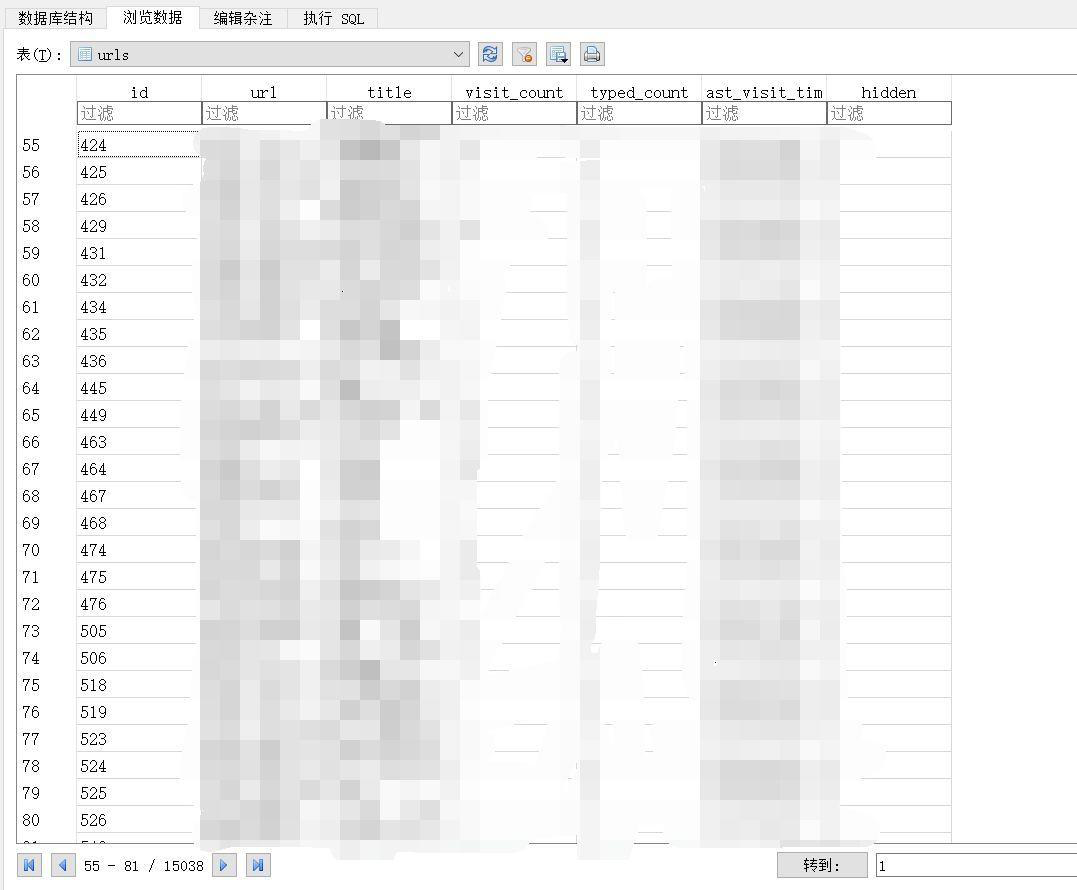
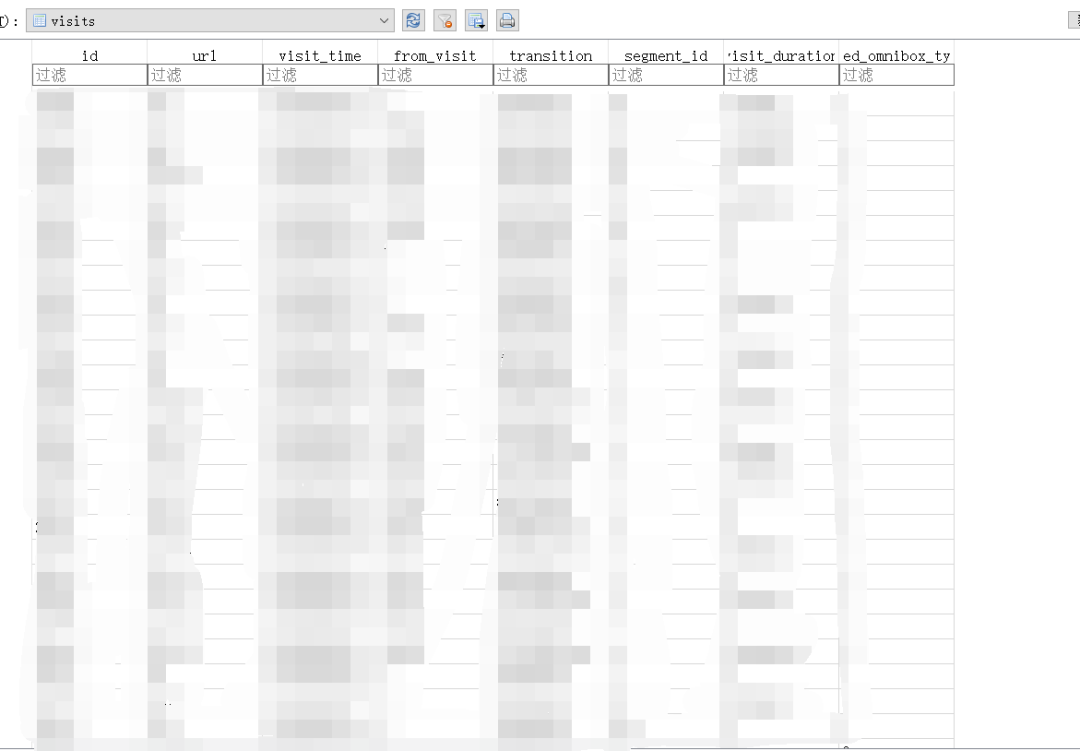
了解了表的结构之后,我们就可以愉快地写代码提取历史浏览记录了:
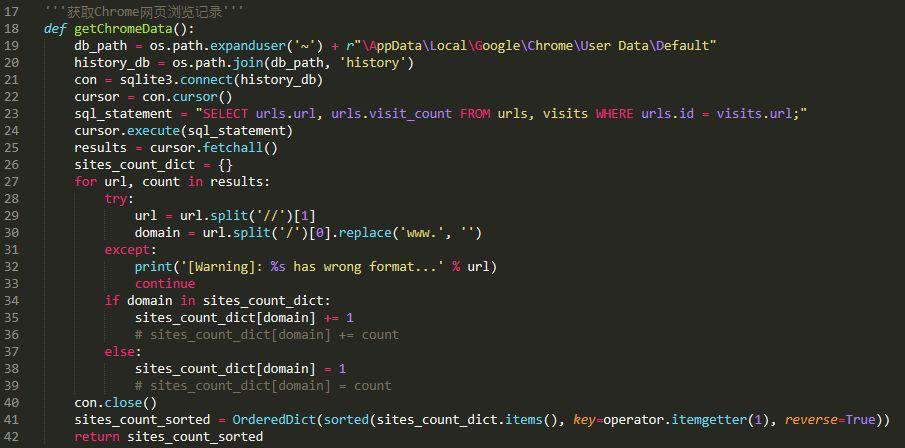
将获取到的数据进行简单的可视化,结果如下:

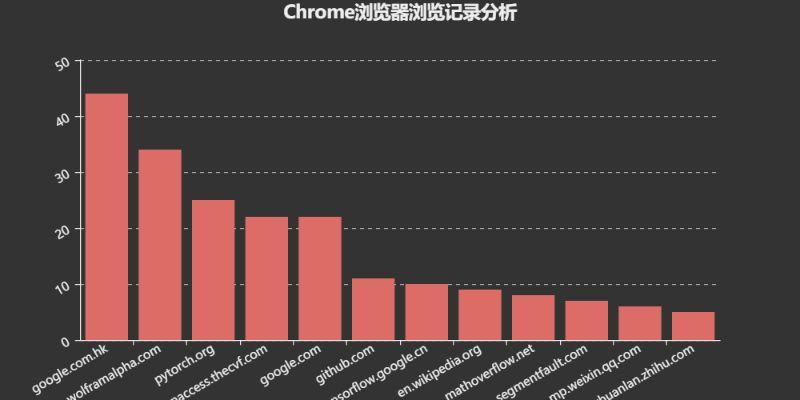
文章到这里就结束了,喜欢的朋友可以点波关注我每天分享Python数据爬虫案例系列(https://www.jianshu.com/nb/45921843),下篇文章分享是监控比特币价格走势
为了感谢读者们,我想把我最近收藏的一些编程干货分享给大家,回馈每一个读者,希望能帮到你们。
干货主要有:
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
⑥ 两天的Python爬虫训练营直播权限
All done~完整源代码详见个人简介或者私信获取相关文件。。
