Python爬虫实战,Scrapy实战,大众点评爬虫

前言
爬一波大众点评上美食板块的数据,顺便再把爬到的数据做一波可视化分析

开发工具
Python版本:3.6.4
相关模块:
scrapy模块;
requests模块;
fontTools模块;
pyecharts模块;
以及一些python自带的模块。
环境搭建
安装python并添加到环境变量,pip安装需要的相关模块即可。
数据爬取
首先,我们新建一个名为大众点评的scrapy项目:
scrapy startproject dazhongdianping
效果如下:

然后去大众点评踩个点吧,这里以杭州为例:
http://www.dianping.com/hangzhou/ch10
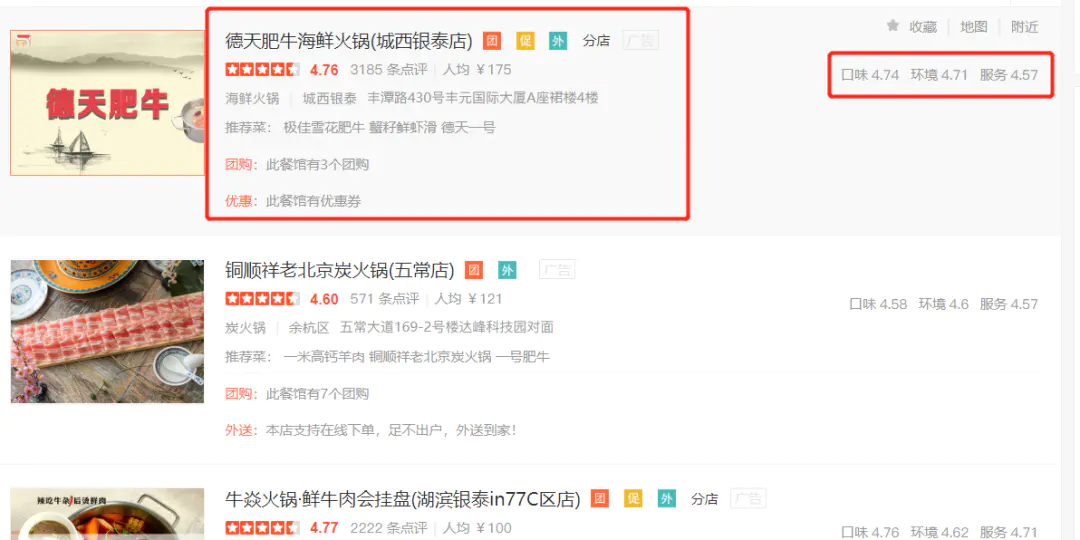
显然,我们想爬取的数据如下图红框所示:
在items.py里定义一下这些数据类型:
"""定义要爬取的数据"""
class DazhongdianpingItem(scrapy.Item):
# 店名
shopname = scrapy.Field()
# 点评数量
num_comments = scrapy.Field()
# 人均价格
avg_price = scrapy.Field()
# 美食类型
food_type = scrapy.Field()
# 所在商区
business_district_name = scrapy.Field()
# 具体位置
location = scrapy.Field()
# 口味评分
taste_score = scrapy.Field()
# 环境评分
environment_score = scrapy.Field()
# 服务评分
serve_score = scrapy.Field()
然后利用正则表达式来提取网页中我们想要的数据(字体反爬我就不讲了,知乎随便搜一下,就好多相关的文章T_T。只要下载对应的字体文件,然后找到对应的映射关系就ok啦):
# 提取我们想要的数据
all_infos = re.findall(r"<li class="" >(.*?)<div class="operate J_operate Hide">", response.text, re.S|re.M)
for info in all_infos:
item = DazhongdianpingItem()
# --店名
item["shopname"] = re.findall(r"<h4>(.*?)</h4>", info, re.S|re.M)[0]
# --点评数量
try:
num_comments = re.findall(r"LXAnalytics("moduleClick", "shopreview").*?>(.*?)</b>", info, re.S|re.M)[0]
num_comments = "".join(re.findall(r">(.*?)<", num_comments, re.S|re.M))
for k, v in shopnum_crack_dict.items():
num_comments = num_comments.replace(k, str(v))
item["num_comments"] = num_comments
except:
item["num_comments"] = "null"
# --人均价格
try:
avg_price = re.findall(r"<b>¥(.*?)</b>", info, re.S|re.M)[0]
avg_price = "".join(re.findall(r">(.*?)<", avg_price, re.S|re.M))
for k, v in shopnum_crack_dict.items():
avg_price = avg_price.replace(k, str(v))
item["avg_price"] = avg_price
except:
item["avg_price"] = "null"
# --美食类型
food_type = re.findall(r"<a.*?data-click-name="shop_tag_cate_click".*?>(.*?)</span>", info, re.S|re.M)[0]
food_type = "".join(re.findall(r">(.*?)<", food_type, re.S|re.M))
for k, v in tagname_crack_dict.items():
food_type = food_type.replace(k, str(v))
item["food_type"] = food_type
# --所在商区
business_district_name = re.findall(r"<a.*?data-click-name="shop_tag_region_click".*?>(.*?)</span>", info, re.S|re.M)[0]
business_district_name = "".join(re.findall(r">(.*?)<", business_district_name, re.S|re.M))
for k, v in tagname_crack_dict.items():
business_district_name = business_district_name.replace(k, str(v))
item["business_district_name"] = business_district_name
# --具体位置
location = re.findall(r"<span class="addr">(.*?)</span>", info, re.S|re.M)[0]
location = "".join(re.findall(r">(.*?)<", location, re.S|re.M))
for k, v in address_crack_dict.items():
location = location.replace(k, str(v))
item["location"] = location
# --口味评分
try:
taste_score = re.findall(r"口味<b>(.*?)</b>", info, re.S|re.M)[0]
taste_score = "".join(re.findall(r">(.*?)<", taste_score, re.S|re.M))
for k, v in shopnum_crack_dict.items():
taste_score = taste_score.replace(k, str(v))
item["taste_score"] = taste_score
except:
item["taste_score"] = "null"
# --环境评分
try:
environment_score = re.findall(r"环境<b>(.*?)</b>", info, re.S|re.M)[0]
environment_score = "".join(re.findall(r">(.*?)<", environment_score, re.S|re.M))
for k, v in shopnum_crack_dict.items():
environment_score = environment_score.replace(k, str(v))
item["environment_score"] = environment_score
except:
item["environment_score"] = "null"
# --服务评分
try:
serve_score = re.findall(r"服务<b>(.*?)</b>", info, re.S|re.M)[0]
serve_score = "".join(re.findall(r">(.*?)<", serve_score, re.S|re.M))
for k, v in shopnum_crack_dict.items():
serve_score = serve_score.replace(k, str(v))
item["serve_score"] = serve_score
except:
item["serve_score"] = "null"
# --yield
yield item
最后在终端运行如下命令就可以爬取我们想要的数据啦:
scrapy crawl dazhongdianping -o infos.json -t json
文章到这里就结束了,感谢你的观看,关注我每天分享Python爬虫实战系列,下篇文章分享中国地震台网爬虫。
为了感谢读者们,我想把我最近收藏的一些编程干货分享给大家,回馈每一个读者,希望能帮到你们。
干货主要有:
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
All done~完整源代码+干货详见个人简介或者私信获取相关文件。。
