Python爬虫之json动态数据抓取

python爬虫之get请求
# 安装requests包:pip install requests
import requests
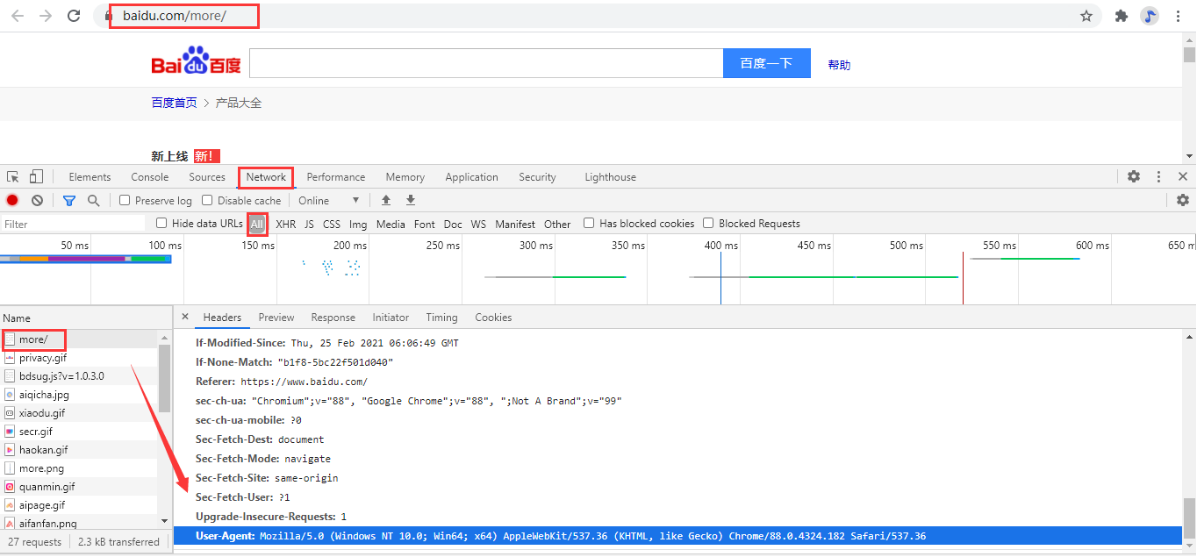
response = requests.get("https://www.baidu.com/more/")
print(response) # <Response [200]>
headers = {
# 浏览器类型
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36"
}
print(response.content.decode("utf-8"))
python爬虫之post请求
# post 请求
import requests
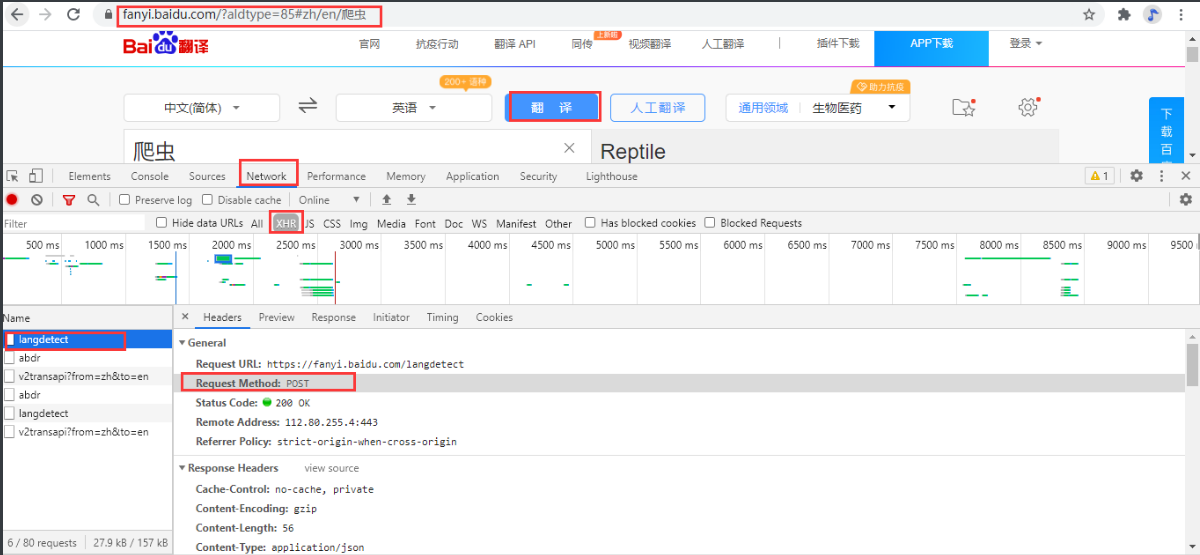
url = "https://fanyi.baidu.com/langdetect"
form_data = {
"query":"爬虫"
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36"
}
response = requests.post(url,data=form_data,headers = headers)
print(response.json())
python爬虫之xpath数据提取
"""
xpath语法
// -> 跟节点
/ -> 节点
@ -> 属性
"""
import requests
from lxml import etree
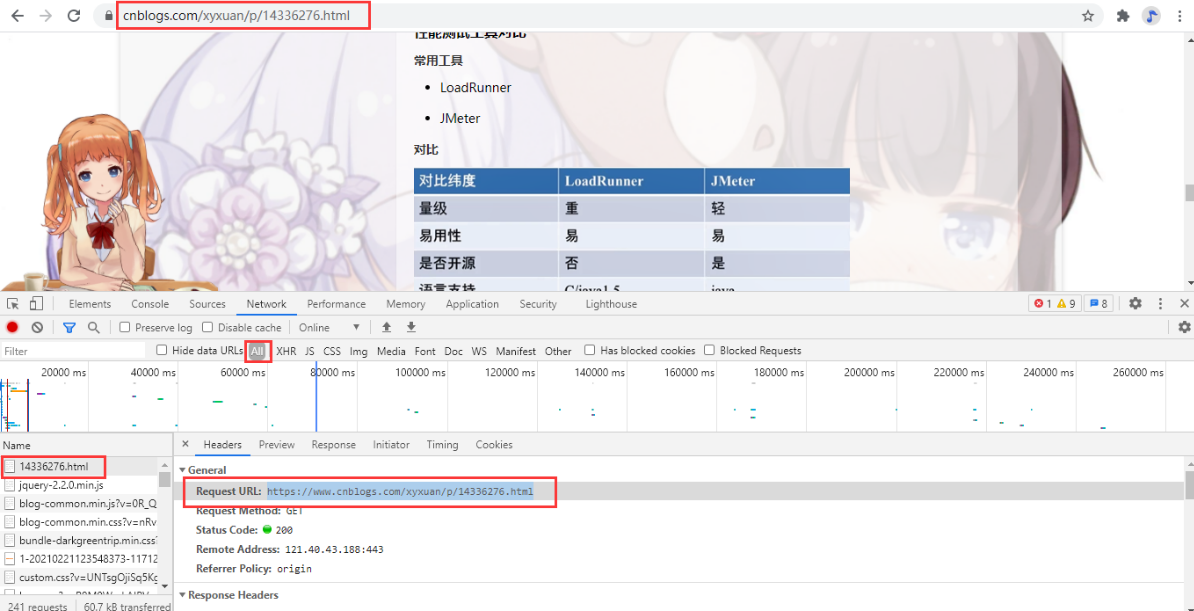
url = "https://www.cnblogs.com/xyxuan/p/14336276.html"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36"
}
# 获取网页数据
response = requests.get(url,headers = headers).content.decode("utf-8")
# 提取网页图片地址
html = etree.HTML(response)
img_url = html.xpath("//p/img/@src")
print(img_url)
json动态数据抓取
好啦,实战开始!!!
直接上源码,以爬取51Job的职位信息为例,可以根据自己需要抓取的网站替换 URL & headers
"""
@ Time:2021/06/15
利用python爬取职位信息,并写入CSV文件中
* 数据来源: 51job
* 开发环境:win10、python3.9
* 开发工具:pycharm、Chrome
项目思路:
1. 首先列出需要获取的数据信息:["职位名称", "公司名称", "薪资","工作地点","公司类型","其他"]
2. 对页面数据进行解析,对页面数据进行JSON格式化,找出所需要的字段,并根据需要进行分类
3. 将获取的数据写入到CSV文件中【注:运行代码时,CSV文件不能是打开的状态,不然会报文件找不到】
"""
import requests
import time
import csv
def inner():
"""
简单的装饰器,主要用于console窗口打印或者写入到TXT文件时,看起来一目了然
:return:
"""
print("******************************************
")
def RequestsTools(url, headers):
"""
爬虫请求工具参数
:param headers: 请求头
:param url: 请求地址
:return: json格式数据
"""
response = requests.get(url=url, headers=headers).json()
return response
def Index(page):
"""
根据页数查询数据函数
:param page:页数
"""
print("@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ 第" + str(page) + "页 @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
")
# 请求头
headers = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"Cookie": "adv=adsnew%3D1%26%7C%26adsnum%3D7093970%26%7C%26adsresume%3D1%26%7C%26adsfrom%3Dhttps%253A%252F%252Fwww.baidu.com%252Fother.php%253Fsc.Kf00000T8huPAl74RAWWief16RqsEaFV3GEpSPlG_RH0OAZZM913BX4XW42Rq9wSaxNCEdrFH59E8nm_o2Blo0QXlwIwEzKH3XKfx9bWUnDd6UIPrw7IjCBTkDu4QJYRQsPbuYCnHiw1COgZeWIT1Q5-pquOVZXVfbnqRTyPXgbOsPGr-2-rTiM16KOck4fyM8ye8sI3nKQch1AbJ0l52PBRzExL.DR_NR2Ar5Od66CHnsGtVdXNdlc2D1n2xx81IZ76Y_XPhOWEtUrorgAs1SOOo_9OxOBI5lqAS61kO56OQS9qxuxbSSjO_uPqjqxZOg7SEWSyWxSrOSFO_OguCOBxQetZO03x501SOOoCgOQxG9YelZ4EvOqJGMqEOggjSS4Wov_f_lOA7MuvyNdleQeAI1PMAeB-5Wo9Eu88lN2s1f_TTMHYv00.TLFWgv-b5HDkrfK1ThPGujYknHb0THY0IAYqPH7JUvc0IgP-T-qYXgK-5H00mywxIZ-suHY10ZIEThfqPH7JUvc0ThPv5HD0IgF_gv-b5HDdnWT1rHcLrj60UgNxpyfqnHfzP1f3rHD0UNqGujYknjb1rj0LP6KVIZK_gv-b5HDznWT10ZKvgv-b5H00pywW5R420ZKGujYz0APGujY1rHm0mLFW5HcvPH6s%2526ck%253D2896.2.223.275.159.314.188.588%2526dt%253D1623736783%2526wd%253D51job%2526tpl%253Dtpl_12273_25609_20875%2526l%253D1527392788%2526us%253DlinkName%25253D%252525E6%252525A0%25252587%252525E9%252525A2%25252598-%252525E4%252525B8%252525BB%252525E6%252525A0%25252587%252525E9%252525A2%25252598%252526linkText%25253D%252525E3%25252580%25252590%252525E5%25252589%2525258D%252525E7%252525A8%2525258B%252525E6%25252597%252525A0%252525E5%252525BF%252525A751Job%252525E3%25252580%25252591-%25252520%252525E5%252525A5%252525BD%252525E5%252525B7%252525A5%252525E4%252525BD%2525259C%252525E5%252525B0%252525BD%252525E5%2525259C%252525A8%252525E5%25252589%2525258D%252525E7%252525A8%2525258B%252525E6%25252597%252525A0%252525E5%252525BF%252525A7%2521%252526linkType%25253D%26%7C%26; guid=fa4573e0cb7f90a6371f267812a399a8; slife=lowbrowser%3Dnot%26%7C%26; nsearch=jobarea%3D%26%7C%26ord_field%3D%26%7C%26recentSearch0%3D%26%7C%26recentSearch1%3D%26%7C%26recentSearch2%3D%26%7C%26recentSearch3%3D%26%7C%26recentSearch4%3D%26%7C%26collapse_expansion%3D; search=jobarea%7E%60020000%7C%21ord_field%7E%600%7C%21recentSearch0%7E%60020000%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FA%C8%ED%BC%FE%B2%E2%CA%D4%B9%A4%B3%CC%CA%A6%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36"
}
url = "https://search.51job.com/list/020000,000000,0000,00,9,99,%25E8%25BD%25AF%25E4%25BB%25B6%25E6%25B5%258B%25E8%25AF%2595%25E5%25B7%25A5%25E7%25A8%258B%25E5%25B8%2588,"
"2,{}.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=".format(page)
response = RequestsTools(url,headers)
# 需要获取的信息
information = ["job_name", "company_name", "providesalary_text", "workarea_text", "companytype_text","attribute_text"]
# top 广告位
def top():
list = []
data = ["top_ads", "auction_ads", "market_ads"]
for top in data:
if len(response[top]):
for i in information:
content = response[top][0][i]
list.append(content)
print(list)
write(list)
list = []
inner()
time.sleep(6) # 让他睡一会吧,不然查询太过频繁IP被封了
else:
print(top + "广告位为空!!!
")
# 正常广告位
def ordinarys():
list = []
ordinarys = response["engine_search_result"]
for ordinary in ordinarys:
for i in information:
content = ordinary[i]
list.append(content)
print(list)
write(list)
list = []
inner()
time.sleep(6)
if page == 1:
top()
ordinarys()
else:
ordinarys()
# 写入数据到CSV文件中
def write(list):
path = r"D:learnprojecteptile51job.csv"
with open(path, mode="a", encoding="gbk", newline="") as f:
# 基于文件对象构建CSV写入对象
csv_writer = csv.writer(f)
# 将构建好的数组依次写入表格,每次调用会自动换行
csv_writer.writerow(list)
# 关闭文件
f.close()
if __name__ == "__main__":
for page in range(0,11):
page += 1
Index(page)
console窗口显示:
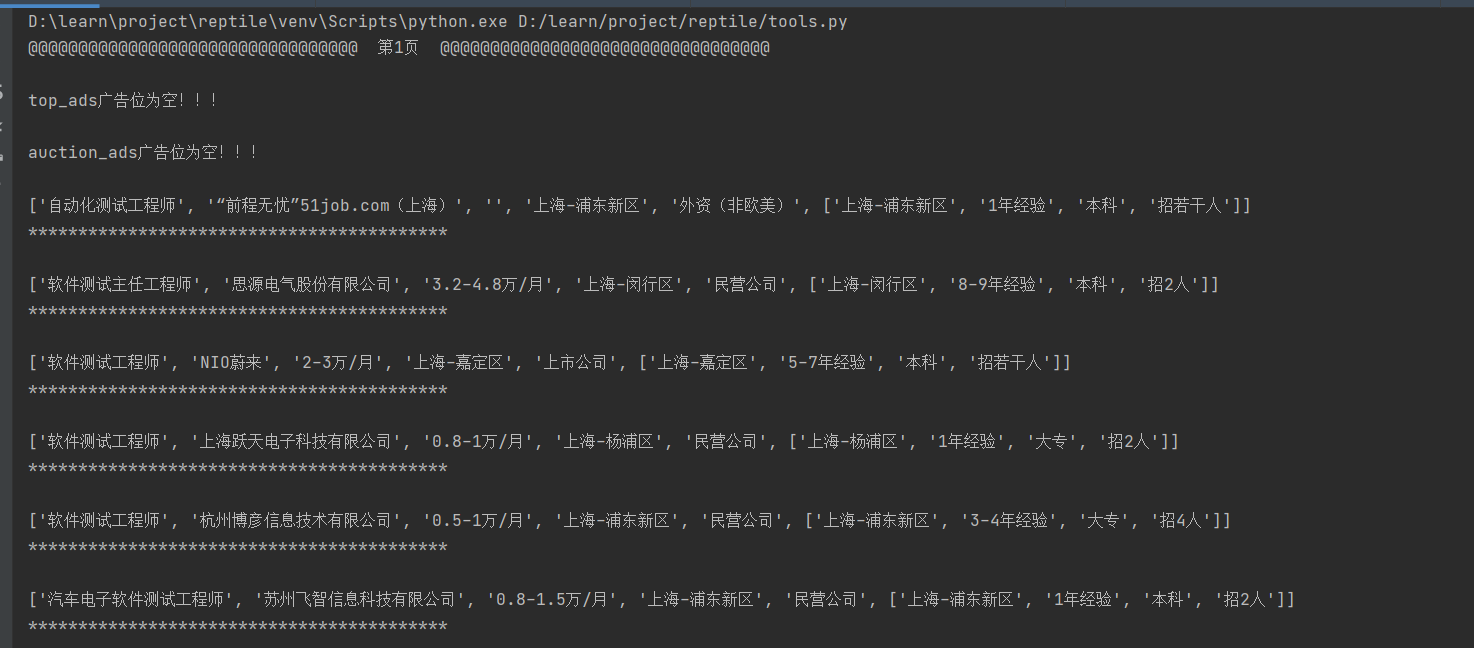
写入到CSV文件显示:
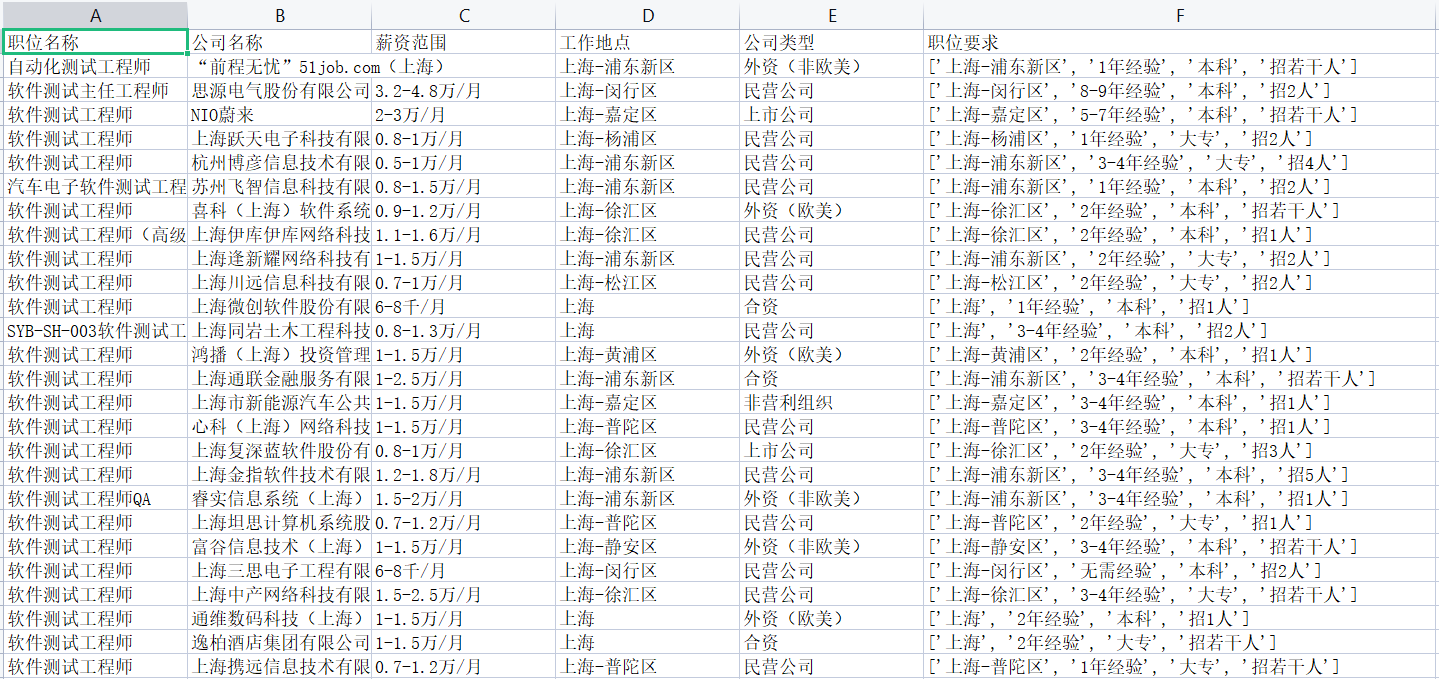
同样的,也可以写入的txt文件中,且不需要转换为List 格式,直接str格式即可写入,样式自己调整~
import requests
"""
需要获取的信息
"""
information = ["job_name", "company_name", "providesalary_text", "workarea_text", "companytype_text", "attribute_text"]
"""
装饰器
"""
def inner():
print("******************************************
")
def url(num):
print("@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ 第"+str(num)+"页 @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
")
wfile("@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ 第"+str(num)+"页 @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
")
# 动态url
url = "https://search.51job.com/list/020000,000000,0000,32,9,99,%25E8%25BD%25AF%25E4%25BB%25B6%25E6%25B5%258B%25E8%25AF%2595%25E5%25B7%25A5%25E7%25A8%258B%25E5%25B8%2588,2,"+ str(num) +".html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare="
headers = {
# 请求类型
"Accept": "application/json, text/javascript, */*; q=0.01",
"Referer": "https://search.51job.com/list/020000,000000,0000,32,9,99,%25E8%25BD%25AF%25E4%25BB%25B6%25E6%25B5%258B%25E8%25AF%2595%25E5%25B7%25A5%25E7%25A8%258B%25E5%25B8%2588,2,"+ str(num) +".html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36"
}
# 建立一个session,用来存储cookies
# session = requests.session().get(url,headers = headers)
# cokie = session.cookies
response = requests.get(url=url,headers=headers).json()
# top 广告位
def top():
data = ["top_ads","auction_ads","market_ads"]
for top in data:
if len(response[top]):
for i in information:
content = response[top][0][i]
print(str(content))
wfile(str(content))
wfile("
")
inner()
wfile("******************************************
")
else:
print(top + "广告位为空!!!
")
wfile(top + "广告位为空!!!
")
inner()
wfile("******************************************
")
# 正常广告位
def ordinarys():
ordinarys = response["engine_search_result"]
for ordinary in ordinarys:
for i in information:
content = ordinary[i]
print(content)
wfile(str(content))
wfile("
")
inner()
wfile("******************************************
")
if num == 1:
top()
ordinarys()
else:
ordinarys()
# 将文件写入到excel中 ---["w":覆盖写模式,‘a’:追加写模式]
def wfile(reptile):
with open("/Users/yexuan/python/python_reptile/information.txt", mode="a", encoding="utf-8") as f:
for line in reptile:
f.write(line)
if __name__ == "__main__":
number = 1
while number <= 10:
url(number)
number += 1
bingo~
下一步计划,将爬出的数据通过数据可视化图形显示@.@
