基于SSL(TLS)的HTTPS网页下载——如何编写健壮的可靠的网页下载
源码下载地址
案例开发环境:VS2010
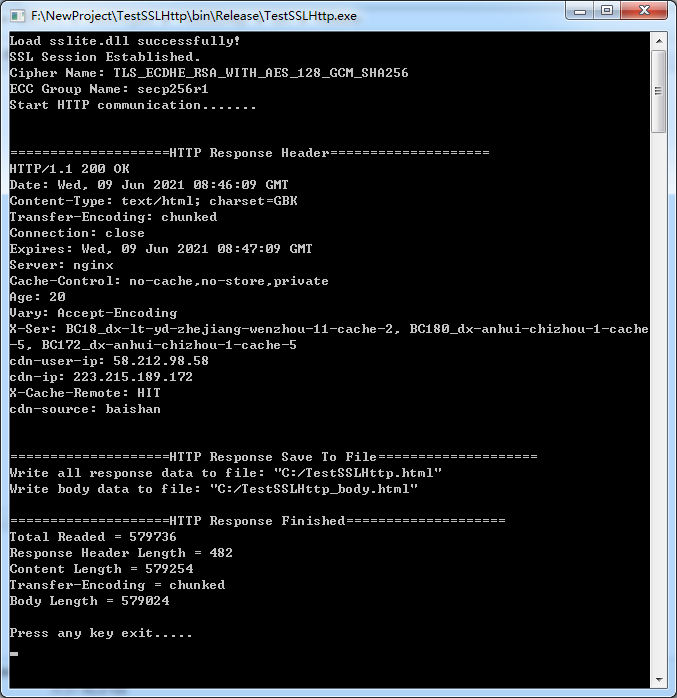
本案例未使用openssl库,内部提供了sslite.dll库进行TLS会话,该库提供了ISSLSession接口用于建立SSL会话。下载的是网易(www.163.com)的主页。程序执行后会打印SSL会话的加密套件名称和Http响应头,并在C盘根目录下输出“TestSSLHttp.html”和“TestSSLHttp_body.html”两个文件。前者是服务器响应的原始文件即包含了响应头,后者是响应数据文件(本案例中为主页HTML)。
HTTP协议很简单,写个简单的socket程序通过GET命令就能把网页给down下来。但接收大的网络资源就复杂多了。何时解析、如何解析完整的HTTP响应头,就是个头疼问题。因为你不能指望一次recv就能接收完所有响应数据,也不能指望服务器先发送完HTTP响应头,然后再发送响应数据(有可能是两者一并发送的)。只有把HTTP响应头彻底解析了,我们才能知道后续接收的Body数据有多大,何时才能接收完毕。
比如通过响应头的”Content-Length”字段,才能知道后续Body的大小。这个大小可能超过了你之前开辟的接收数据缓存区大小。当然你可以在得知Body大小后,重新开辟一个与”Content-Length”一样大小的缓存区。但这样做显然是不明智的,比如你get的是一部4K高清蓝光小电影,蓝光电影不一定能get到,蓝屏电脑倒有可能get到。。。。。。
遇到服务器明确给出”Content-Length”字段,是一件值得额手称庆的大喜事,但不是每个IT民工都这么幸运。如果遇到的是不靠谱的服务器,发送的是”Transfer-Encoding: chunked”,那你就必须锻炼自己真正的解析和组织能力了。这些分块传输的数据,显然不会以你接收的节奏到达你的缓冲区,比如先接收到一个block块大小,然后是一个完整的块数据,很有可能你会接收到多个块或者不完整的块,这就需要你站在宏观的角度把他们拼接起来。
如果你遇到的是甩的一米的服务器,它不仅给你的是chunked,而且还增加了”Content-Encoding: gzip”,那么你就需要拼接后进行解压,当然你也可能遇到的是”deflate”压缩。
附:我写过web服务器,所以也知道服务器的心理。。。。。。
HttpServer:一款Windows平台下基于IOCP模型的高并发轻量级web服务器
题外话:我一直困惑的是HTTP协议为何不是对分块数据单独gzip压缩然后传输,而只能是整体gzip压缩后再分块传输。这个对大资源传输很关键,比如上面的4K高清蓝光小电影,显然不能通过gzip+chunked方式传输,土豪服务器例外。
当然你也可以用开源的llhttp来解析收到的http数据,从而避免上述可能会遇到的各种坑。最新版本的nodejs中就使用llhttp代替之前的的http-parser,据说解析效率有大幅提升。为此我下载了nodejs源码,并编译了一把,这是一个快乐的过程,因为你可以看到v8引擎,openssl,zlib等各种开源库。。。。,不过llhttp只负责解析,不负责缓存,因此你还是需要在解析的过程中,进行数据缓存。
关于V8引擎的使用参见文章
V8引擎静态库及其调用方法
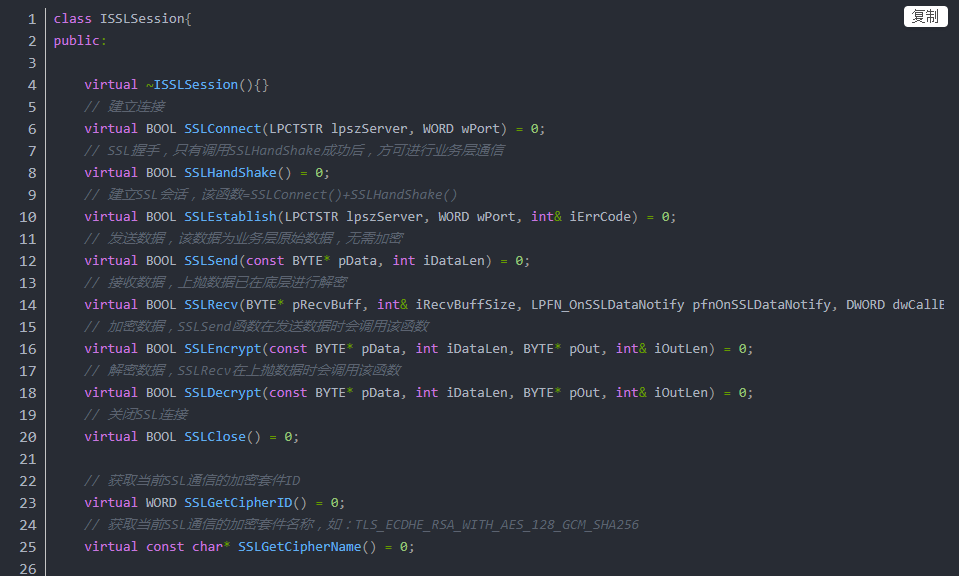
以下是sslite库提供的接口,SSLConnect是建立连接,SSLHandShake是SSL握手,握手成功后即可调用SSLSend和SSLRecv进行数据接收和发送,非常简单。如果接收数据很多,SSLRecv会通过回调函数将数据抛给调用层。
以下是部分源码截图,注释很多,就不一一解释了。