深入理解上篇之 Python的进程和线程

python视频教程栏目介绍进程和线程。

进程(Process)和线程(Thread)都是操作系统中的基本概念,它们之间有一些优劣和差异,那么在Python中如何使用进程和线程?
CPU
计算机的核心是CPU,它承担了计算机的所有计算任务,CPU就像一个工厂,时刻在运行着,而操作系统管理着计算机,负责任务的调度、资源的分配和管理。
进程
进程是指在系统中能独立运行并作为资源分配的基本单位,它是由一组机器指令、数据和堆栈等组成的,是一个能独立运行的活动实体。
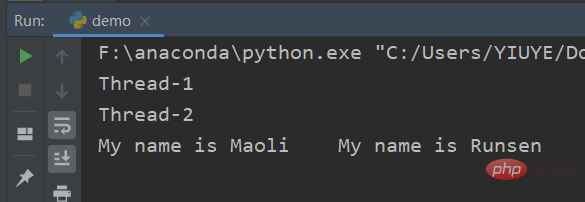
我们打开我们的计算机就会看到进程和线程,点击我的电脑就可以看到CPU的运算。
从如图中,CPU一共运行着190个进程,2620个线程。比如,当我们再次点击QQ,登陆另一个账号的时候又会开启另一个QQ进程。
因此,如果想在电脑登入多个微信。只需要找到你的微信快捷方式,单击右键查看属性,在目标中复制链接;新建一个记事本,随便取个名字,双击打开后,在其中输入 start ""(注意引号为英文状态,且前后有空格),将刚刚复制的链接(也就是微信安装的路径)粘贴进去;然后复制整行,想开几个微信就粘贴几行;保存文件,更改后缀名为 bat。双击运行即可。
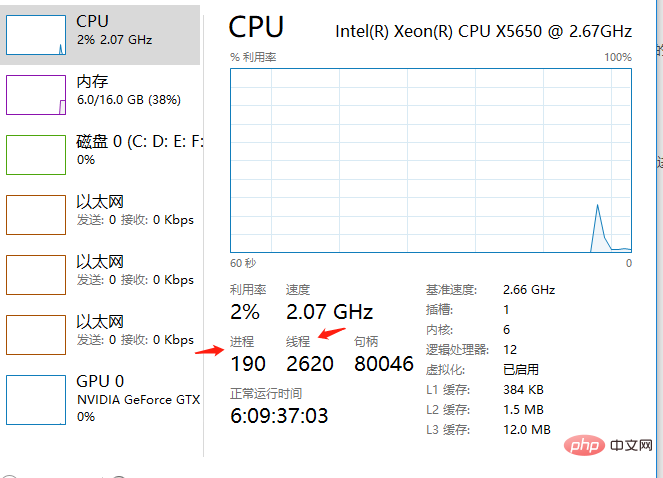
从如图中,CPU一共运行着190个进程,2620个线程。比如,当我们再次点击QQ,登陆另一个账号的时候又会开启另一个QQ进程。
因此,如果想在电脑登入多个微信。只需要找到你的微信快捷方式,单击右键查看属性,在目标中复制链接;新建一个记事本,随便取个名字,双击打开后,在其中输入 start ""(注意引号为英文状态,且前后有空格),将刚刚复制的链接(也就是微信安装的路径)粘贴进去;然后复制整行,想开几个微信就粘贴几行;保存文件,更改后缀名为 bat。双击运行即可。
线程
线程(Thread)也叫轻量级进程,是操作系统能够进行运算调度的最小单位,它被包涵在进程之中,是进程中的实际运作单位。
记得阮一峰写过的博客:假定工厂的电力有限,一次只能供给一个车间使用。也就是说,一个车间开工的时候,其他车间都必须停工。背后的含义就是,单个CPU一次只能运行一个任务。
进程就好比工厂的车间,它代表CPU所能处理的单个任务。任一时刻,CPU总是运行一个进程,其他进程处于非运行状态。
线程就好比车间里的工人。一个进程可以包括多个线程,协同完成一个任务。
总结来说:程序可以包含多个进程,多个进程并发执行,相互独立,因此,进程也是系统进行资源分配和调度基本单位。专业化来说:进程是指程序执行时的一个实例。线程是最小的执行单元,而进程由至少一个线程组成。如何调度进程和线程,完全由操作系统决定。

进程就好比工厂的车间,它代表CPU所能处理的单个任务。任一时刻,CPU总是运行一个进程,其他进程处于非运行状态。
线程就好比车间里的工人。一个进程可以包括多个线程,协同完成一个任务。
总结来说:程序可以包含多个进程,多个进程并发执行,相互独立,因此,进程也是系统进行资源分配和调度基本单位。专业化来说:进程是指程序执行时的一个实例。线程是最小的执行单元,而进程由至少一个线程组成。如何调度进程和线程,完全由操作系统决定。
在Python中线程和进程的使用
现在讲下在Python线程和进程的使用。
在Python中,通过两个标准库 thread和 Threading提供对线程的支持,threading对 thread进行了封装。threading模块中提供了 Thread,Lock, RLOCK, Condition等组件
Thread
在Python中线程和进程的使用就是通过Thread这个类。这个类在我们的_thread和threading模块中。我们一般通过threading导入。
默认情况下,只要在解释器中,如果没有报错,则说明线程可用。
>> from threading import Thread复制代码
下面是Thread类的常用参数说明和实例方法。

我们看一个官方文档中标准的多线程的例子。
我们看一个官方文档中标准的多线程的例子。
import threading import time # 定义线程要运行的函数 def func(name): # 为了便于观察,睡眠2秒 time.sleep(2) print("My name is %s " % name) # 创建第一个线程的实例,args参数是一个元组,后面必须加逗号分隔 t1 = threading.Thread(target=func, args=("Runsen",)) # 创建第二个线程的实例 t2 = threading.Thread(target=func, args=("Maoli",)) t1.start() t2.start() # 先打印线程名 print(t1.getName()) print(t2.getName())复制代码由于两个线程是同时运行的,所以
下面我写了下面的代码,加深threading模块的使用。
下面我写了下面的代码,加深threading模块的使用。
# -*- coding:utf-8 -*-# time :2019/4/9 21:52# author: Runsenimport threadingimport timedef fun1(): print('hello') time.sleep(2) print('Bye')def fun2(): print('hi') time.sleep(2) print('OUT') t1 = threading.Thread(target=fun1) t2 = threading.Thread(target=fun2) t1.start() t2.start()# t1.join()# t2.join()print('主线程完毕')复制代码下面是输出结果。
hello hi 主线程完毕 Bye OUT复制代码我们先不加
join()来阻塞,t1和t2两个线程同时执行,由于位置关系先打印hello,再打印hi,这个时候都sleep2秒钟,但是它sleep2秒钟,主程序还是在执行,所以下面打印print('主线程完毕'),最后才打印Bye和OUT。线程间变量的共享
在多线程中,所有变量对于所有线程都是共享的,因此,线程之间共享数据的最大危险在于多个线程同时修改一个变量,那就乱套了,所以我们需要互斥锁,来锁住数据。
代码如上图所示,上面代码中打印的a是1还是2?
答案是:2。因为出现了
global关键字,线程间变量的共享,在func函数中的a是全局变量。因此在函数中a的值发生了变化。下面,我们提高一点点难度,代码如下图所示,还是猜一猜a是啥东西。注意:这里出现了join来阻塞,并且增加了加和减的操作。
相信很多人都认为是0,其实这个a的值是变化的,可能这次是0 ,下次是1,还有可能是
1000000,比如,我可以a就是在
[-1000000,1000000]中的一个随机数。为什么呢?这是因为虽然他们是同时运行的,但是同时在修改我们的a,那就乱了。a在
for i in range(1000000),就是遍历了1000000,incr和decr的方法都加上一起了,在这1000000次遍历中,不知道有多少加,多少减,比如,我1000000都是加,没有减,a就是1000000,但是这种情况的概率很低。如果你就是想出现0,其实只需要加一个互斥锁就可以了。这样你加多少次,我就减多少次,加减的次数不会叠加。因此来了lock的用法,具体代码如下图所示。
这个a怎么运行都是 0。因为我们把这个a锁上了,这样就加1000000次,减1000000次,怎么出来都是我们的0。
相关免费学习推荐:python视频教程