揭秘Java高效随机数生成器

![揭秘Java高效随机数生成器
[编程语言教程]](https://www.zixueka.com/wp-content/uploads/2024/01/1706710866-0f6cdbb5f0cefe6.jpg)
1.前言
在Java中一提到随机数,很多人就会想到Random类,如果有生成随机数的需求的时候,大多数时候都会选择使用Random来进行随机数生成,虽然其内部使用CAS来实现,但是在多线程并发的情况下的时候它的表现并不是很好。在JDK1.7之后,JDK提供了提供了更好的解决方案,接下来让我们一起学习下到底为什么Random会慢?又是怎么解决的呢?
2.Random
Random这个类是JDK提供的用来生成随机数的一个类,这个类并不是真正的随机,而是伪随机,伪随机的意思是生成的随机数其实是有一定规律的,而这个规律出现的周期随着伪随机算法的优劣而不同,一般来说周期比较长,但是可以预测。通过下面的代码我们可以对Ramdom进行简单的使用:
2.1Ramdom原理
Ramdom中的方法比较多,这里就针对比较常见的nextInt()和nextInt(int bound)方法进行分析,前者会计算出int范围内随机数,后者如果我们传入10,那么他会求出[0,10)之间的int类型的随机数,左闭右开。在具体分析之前我们先看一下Ramdom()的构造方法: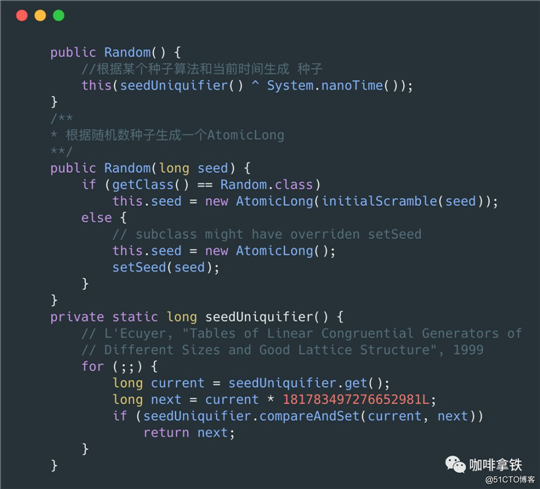
可以看见在构造方法当中根据当前时间的种子生成了一个AtomicLong类型的seed,这也是我们后续的关键所在。
2.1.1 nextInt()
在nextInt()中代码如下:
这个里面直接调用的是next()方法,传入的32,这里的32指的是Int的位数。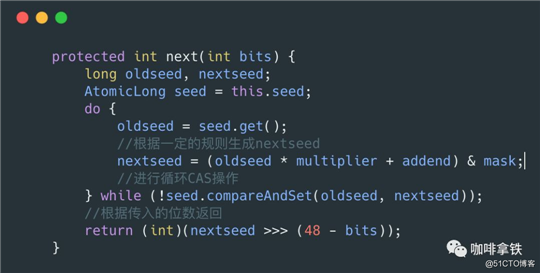
这里会根据seed当前的值,通过一定的规则(伪随机)算出下一个seed,然后进行cas,如果cas失败继续循环上面的操作。最后根据我们需要的bit位数来进行返回。
2.1.2 nextInt(int bound)
在nextInt(int bound)中代码如下: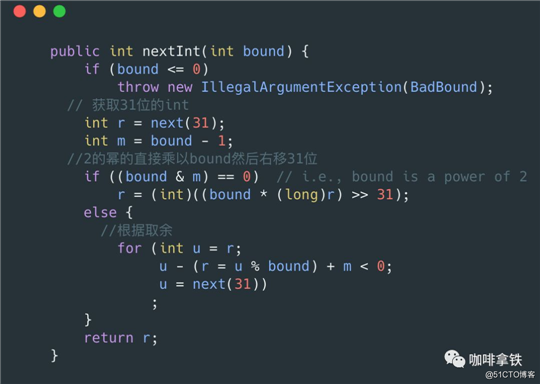
这个流程比nextInt()多了几步,具体步骤如下:
- 首先获取31位的随机数,注意这里是31位,和上面32位不同,因为在nextInt()方法中可以获取到负数的随机数,而nextInt(int bound)规定只能获取到[0,bound)之前的随机数,也就是必须是正数,而int的第一位是符号位所以只获取了31位。
- 然后进行取bound操作。
- 如果bound是2的幂,那么直接将第一步获取的数据乘以bound然后右移31位,解释一下:如果bound是4那么,如果乘以4其实就是左移2位,那么其实就是变成了33位,那么再右移31位的话,就又会变成2位,那么2位的int的大小范围其实就是[0,4)了。
- 如果不是2的幂,通过取余的操作进行处理。
2.1.3 并发瓶颈
CAS: 可以看见在next(int bits)方法中,对AtomicLong进行CAS操作,如果失败则会对其进行循环重试。很多人一看见CAS,因为其不需要加锁,所以马上就想到高性能,高并发。但是在这里,他却成为了我们多线程并发性能的瓶颈,可以想象当我们多个线程都进行CAS的时候必定只有一个失败其他的继续会循环做CAS操作,当并发线程越多的时候,其性能肯定越低。
伪共享:有关于伪共享和缓存行的描述可以看我的还在用BlockingQueue?读这篇文章,了解下Disruptor吧,对于AtomicLong中的value并没有处理缓存行
3.ThreadLocalRandom
在JDK1.7之后提供了新的类ThreadLocalRandom用来代替Ramdom。使用方法比较简单: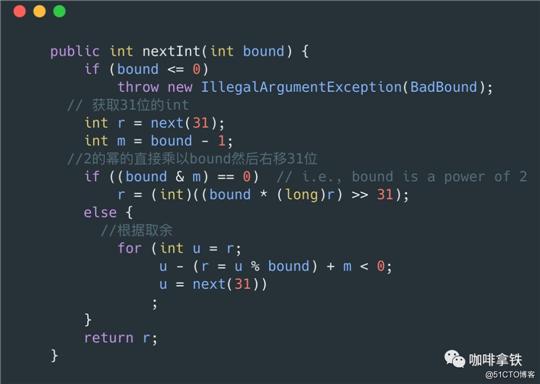
在current方法中有:
可以看见如果没有初始化会对其进行初始化,而这里我们的seed不再是一个全局变量,在我们的Thread中有三个变量: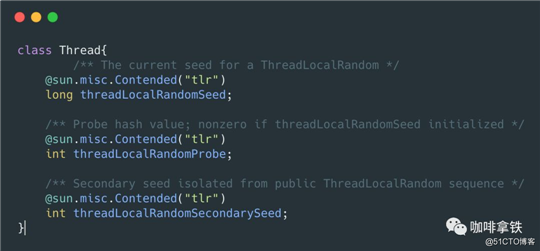
- threadLocalRandomSeed:这个是我们用来控制随机数的种子。
- threadLocalRandomProbe:这个是ThreadLocalRandom用来控制初始化。
- threadLocalRandomSecondarySeed:这个是二级种子。
可以看见所有的变量都加了@sun.misc.Contended这个注解,这个是用来处理伪共享的问题。
在nextInt()方法当中代码如下: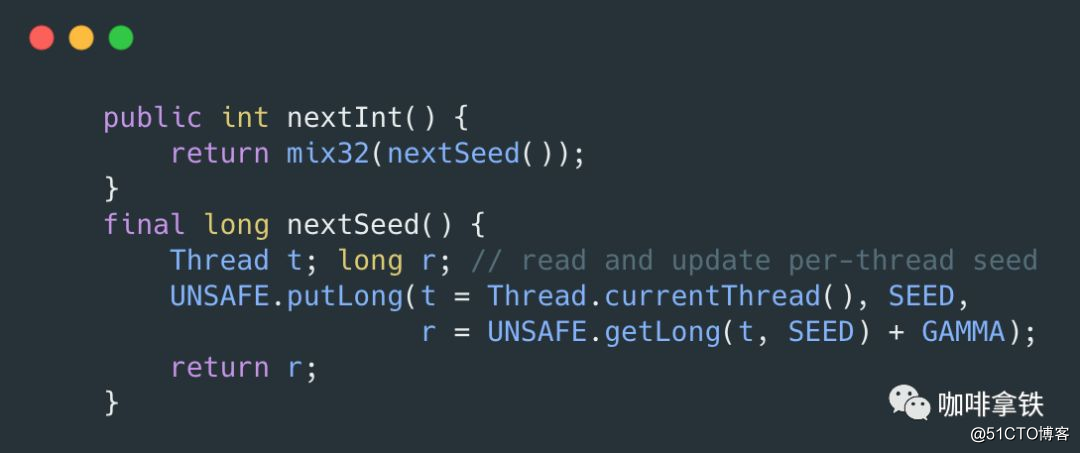
我们的关键代码如下:
UNSAFE
.
putLong
(
t
=
Thread
.
currentThread
(),
SEED
,
r
=
UNSAFE
.
getLong
(
t
,
SEED
)
+
GAMMA
);可以看见由于我们每个线程各自都维护了种子,这个时候并不需要CAS,直接进行put,在这里利用线程之间隔离,减少了并发冲突,所以ThreadLocalRandom性能很高。
4.性能数据
使用JMH进行基准测试:
@BenchmarkMode
({
Mode
.
AverageTime
})
@OutputTimeUnit
(
TimeUnit
.
NANOSECONDS
)
@Warmup
(
iterations
=
3
,
time
=
5
,
timeUnit
=
TimeUnit
.
SECONDS
)
@Measurement
(
iterations
=
3
,
time
=
5
)
@Threads
(
4
)
@Fork
(
1
)
@State
(
Scope
.
Benchmark
)
public
class
Myclass
{
Random
random
=
new
Random
();
ThreadLocalRandom
threadLocalRandom
=
ThreadLocalRandom
.
current
();
@Benchmark
public
int
measureRandom
(){
return
random
.
nextInt
();
}
@Benchmark
public
int
threadLocalmeasureRandom
(){
return
threadLocalRandom
.
nextInt
();
}
}并发线程 Random ThreadLocalRandom
1 12.798 ns/op 4.690 ns/op
4 361.027 ns/op 5.930 ns/op
16 2288.391 ns/op 22.155 ns/op
32 4812.740 ns/op 49.144 ns/op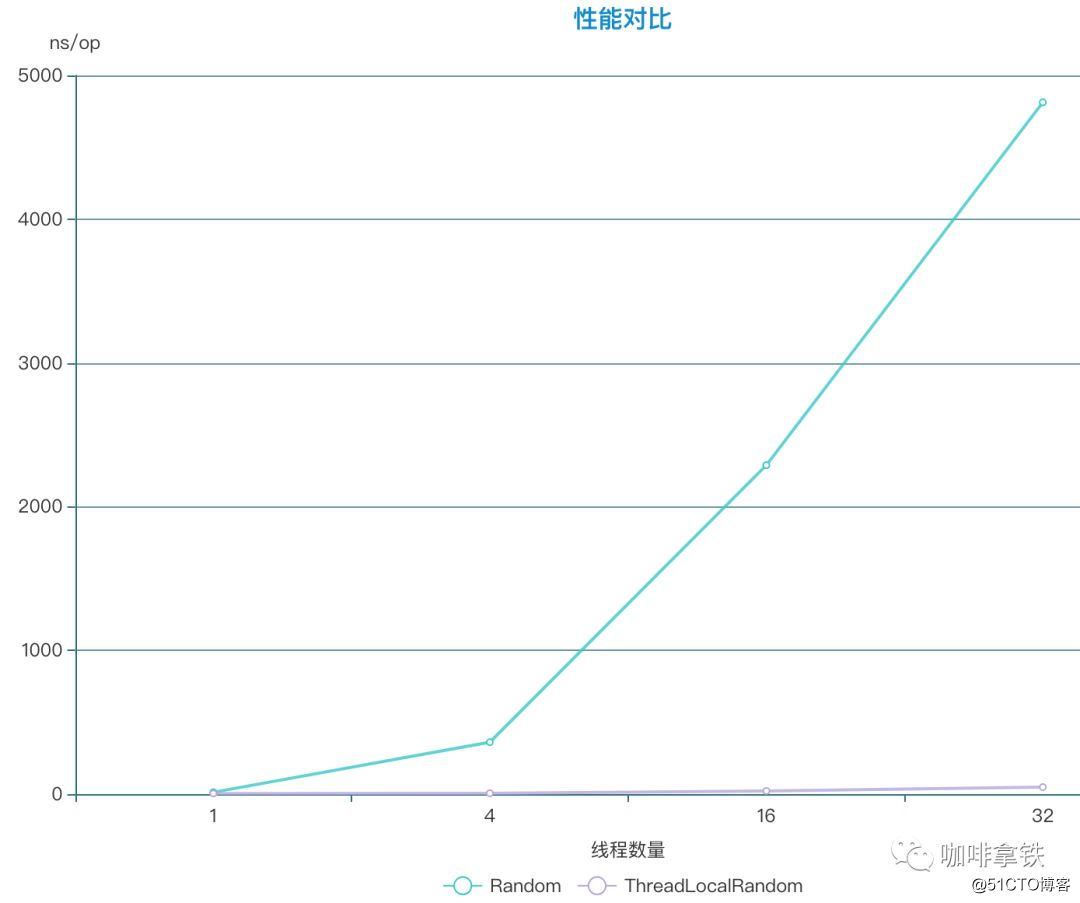
可以看见ThreadLocalRandom 基本上是完虐Random,并发程度越高差距越大。
最后
相信读完这篇文章以后,未来如果在实际应用中使用随机数你肯定会有新的选择。
最后打个广告,如果你觉得这篇文章对你有文章,可以关注我的技术公众号,最近作者收集了很多最新的学习资料视频以及面试资料,关注之后即可领取,你的关注和转发是对我最大的支持,O(∩_∩)O
往
期
精
彩
如何优雅的使用缓存?
Java并发计数器探秘
你应该知道的缓存进化史
为什么开发人员必须要了解数据库锁?揭秘Java高效随机数生成器
原文地址:https://blog.51cto.com/14980978/2544820
