总结用Python 操作 PDF 的几种方法
python教程栏目今天为大家总结用Python操作PDF的几种方法。

01
前言
大家好,有关 Python 操作 PDF 的案例之前已经写过一个?PDF批量合并,这个案例初衷只是给大家提供一个便利的脚本,并没有太多讲解原理,其中涉及的就是 PDF 处理很实用的模块 PyPDF2 ,本文就好好剖析一下这个模块,主要将涉及
- os 模块综合应用
- glob 模块综合应用
- PyPDF2 模块操作
02
基本操作
PyPDF2 导入模块的代码常常是:
from PyPDF2 import PdfFileReader, PdfFileWriter复制代码
这里导入了两个方法:
- PdfFileReader 可以理解为读取器
- PdfFileWriter 可以理解为写入器
接下来通过几个案例进一步认识这两个工具的奇妙之处,用到的示例文件是5个发票的 pdf

每个发票的 PDF 都由两页组成:
03
合并
第一个工作是将5个发票pdf合并成10页。这里读取器和写入器应该怎么配合呢?
逻辑如下:
- 读取器将所有pdf读取一遍
- 读取器将读取的内容交给写入器
- 写入器统一输出到一个新pdf
这里还有一个重要的知识点:读取器只能将读取的内容一页一页交给写入器。
因此,逻辑中第1步和第2步实际上不是彼此独立的步骤,而是读取器读取完一个pdf后,就将这个pdf全部页循环一遍,挨页交给写入器。最后等读取工作全部结束后再输出。
看一下代码可以让思路更清楚:
from PyPDF2 import PdfFileReader, PdfFileWriter
path = r'C:Usersxxxxxx'
pdf_writer = PdfFileWriter()
for i in range(1, 6):
pdf_reader = PdfFileReader(path + '/INV{}.pdf'.format(i))
for page in range(pdf_reader.getNumPages()):
pdf_writer.addPage(pdf_reader.getPage(page))
with open(path + r'合并PDFmerge.pdf', 'wb') as out:
pdf_writer.write(out)复制代码
由于全部内容都需要交给同一个写入器最后一起输出,所以写入器的初始化一定是在循环体之外的.
如果在循环体内则会变成每次访问读取一个pdf就生成一个新的写入器,这样每一个读取器交给写入器的内容就会被反复覆盖,无法实现我们的合并需求!
循环体开头的代码:
for i in range(1, 6):
pdf_reader = PdfFileReader(path + '/INV{}.pdf'.format(i))复制代码
目的就是每次循环读取一个新的 pdf 文件交给读取器进行后续操作。实际上这种写法不是很提倡,由于各 pdf 命名恰好很规则,所以可以直接人为指定数字进行循环。更好的方法是用 glob 模块:
import glob
for file in glob.glob(path + '/*.pdf'):
pdf_reader = PdfFileReader(path)复制代码
代码中 pdf_reader.getNumPages(): 能够获取读取器的页数,配合 range 就能遍历读取器的所有页。
pdf_writer.addPage(pdf_reader.getPage(page)) 能够将当前页交给写入器。
最后,用 with 新建一个 pdf 并由写入器的 pdf_writer.write(out) 方法输出即可。
04
拆分
如果明白了合并操作中读取器和写入器的配合,那么拆分就很好理解了,这里我们以拆分 INV1.pdf 为2个单独的 pdf 文档为例,同样也先来捋一捋逻辑:
- 读取器读取 PDF 文档
- 读取器一页一页交给写入器
- 写入器每获取一页就立即输出
通过这个代码逻辑我们也可以明白,写入器初始化和输出的位置一定都在读取 PDF 循环每一页的循环体内,而不是在循环体外
代码很简单:
from PyPDF2 import PdfFileReader, PdfFileWriter
path = r'C:Usersxxx'
pdf_reader = PdfFileReader(path + 'INV1.pdf')
for page in range(pdf_reader.getNumPages()):
# 遍历到每一页挨个生成写入器
pdf_writer = PdfFileWriter()
pdf_writer.addPage(pdf_reader.getPage(page))
# 写入器被添加一页后立即输出产生pdf
with open(path + 'INV1-{}.pdf'.format(page + 1), 'wb') as out:
pdf_writer.write(out)复制代码
05
水印
本次的工作是将下图作为水印添加到 INV1.pdf 中
首先是准备工作,将需要作为水印的图片插入 word 中调整合适位置后保存为PDF文件。然后就可以码代码了,需要额外用到 copy 模块,具体解释见下图:
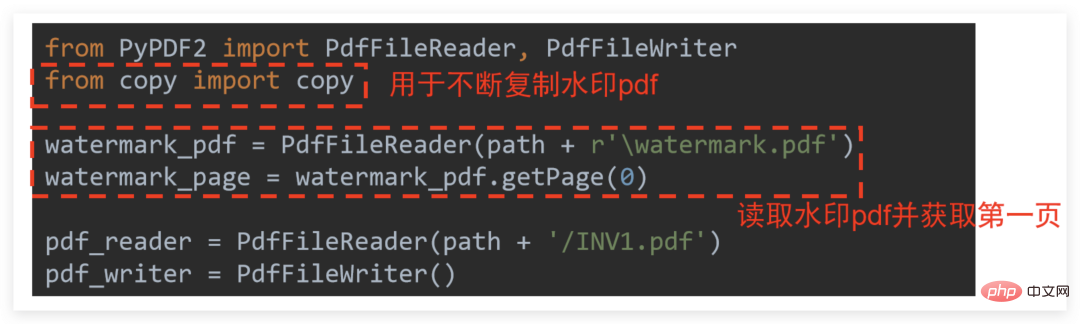
就是把读取器和写入器初始化,并且把水印 PDF 页先读取好备用,核心代码稍微比较难理解:
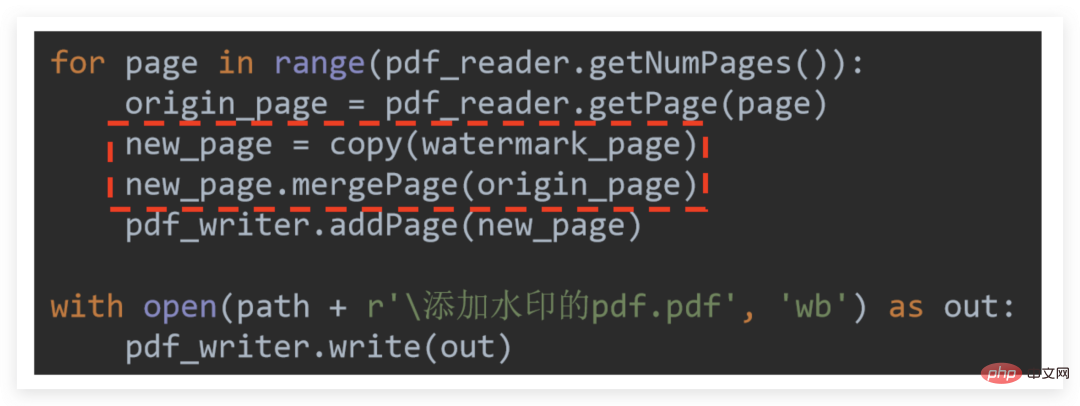
加水印本质上就是把水印 PDF 页和需要加水印的每一页都合并一遍
由于需要加水印的 PDF 可能有很多页,而水印 PDF 只有一页,因此如果直接把水印 PDF 拿来合并,可以抽象理解成加完第一页,水印 PDF 页就没有了。
因此不能直接拿来合并,而要把水印 PDF 页不断 copy 出来成新的一页备用 new_page ,再运用 .mergePage 方法完成跟每一页合并,把合并后的页交给写入器待最后统一输出!
关于 .mergePage 的使用:出现在下面的页 .mergePage (出现在上面的页),最后效果如图:
06
加密
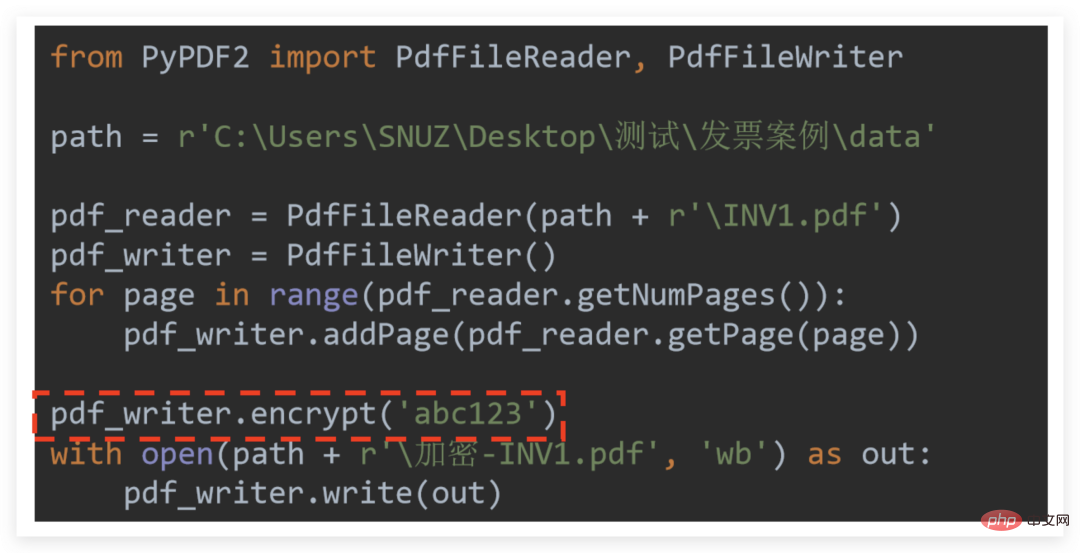
加密很简单,只需要记住:「加密是针对写入器加密」
因此只需要在相关操作完成后调用 pdf_writer.encrypt (密码)
以单个 PDF 的加密为例:
写在最后
当然除了对 PDF 的合并、拆分、加密、水印,我们还可以使用 Python 结合 Excel 和 Word 实现更多的自动化需求,这些就留给读者自己开发。Python资源分享君羊1075110200 ,内有安装包,PDF,学习视频,这里是Python学习者的聚集地,零基础,进阶,都欢迎
最后还是希望大家能够理解Python办公自动化的一个核心就是批量操作-解放双手,让复杂的工作自动化!
更多相关免费学习推荐:python教程(视频)