一篇文章教会你利用Python网络爬虫抓取王者荣耀图片


王者荣耀作为当下最火的游戏之一,里面的人物信息更是惟妙惟肖,但受到官网的限制,想下载一张高清的图片很难。(图片有版权)。
以彼岸桌面这个网站为例,爬取王者荣耀图片的信息。
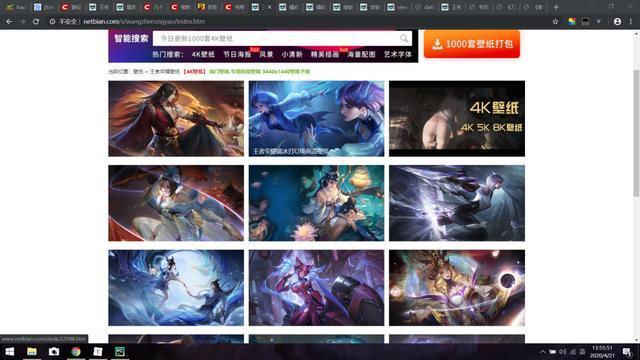
【二、项目目标】
实现将获取到的图片批量下载。
【三、涉及的库和网站】
1、网址如下:
http://www.netbian.com/s/wangzherongyao/index.htm/
2、涉及的库:requests、lxml
【四、项目分析】
首先需要解决如何对下一页的网址进行请求的问题。可以点击下一页的按钮,观察到网站的变化分别如下所示:
http://www.netbian.com/s/wangzherongyao/index_2.htm
http://www.netbian.com/s/wangzherongyao/index_3.htm
http://www.netbian.com/s/wangzherongyao/index_4.htm
观察到只有index_()变化,变化的部分用{}代替,再用for循环遍历这网址,实现多个网址请求。
http://www.netbian.com/s/wangzherongyao/index_{}.htm
【五、项目实施】
1、我们定义一个class类继承object,然后定义init方法继承self,再定义一个主函数main继承self。准备url地址和请求头headers。
import requests
from lxml import etree
import time
class ImageSpider(object):
def __init__(self):
self.firsr_url = "http://www.netbian.com/s/wangzherongyao/index.htm"
self.url = "http://www.netbian.com/s/wangzherongyao/index_{}.htm"
self.headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36"
}
def main(self):
pass
if __name__ == "__main__":
spider= ImageSpider()
spider.main()
2、对网站发生请求。
"""发送请求 获取响应"""
def get_page(self, url):
res = requests.get(url=url, headers=self.headers)
html = res.content.decode("gbk") #网络编码
return html #返回值
3、对请求到的数据进行处理
"""解析数据"""
def parse_page(self, html):
parse_html = etree.HTML(html)
image_src_list = parse_html.xpath("//div[@class="list"]/ul/li/a//@href")
for image_src in image_src_list:
fa = "http://www.netbian.com" + image_src
# print(fa)
4、在谷歌浏览器上,右键选择开发者工具或者按F12。
5、右键检查,找到图片二级的页面的链接,如下图所示。
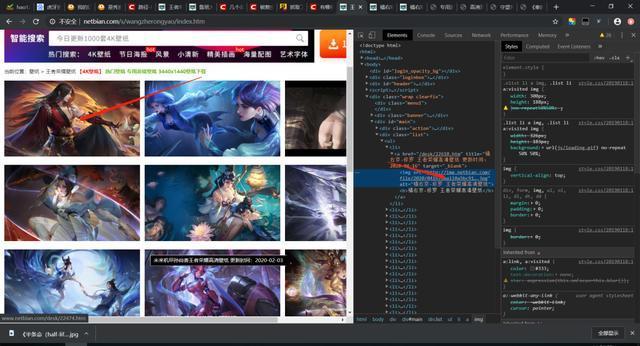
6、对二级页面发生请求,for遍历得到的网址。
bimg_url = parse_html1.xpath("//div[@class="pic-down"]/a/@href")
for i in bimg_url:
diet = "http://www.netbian.com" + i
# print(diet)
html2 = self.get_page(diet)
parse_html2 = etree.HTML(html2)
# print(parse_html2)
url2 = parse_html2.xpath("//table[@id="endimg"]//tr//td//a/img/@src")
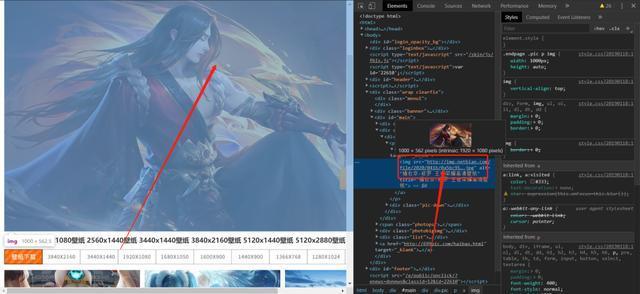
7、将获取的图片写入文档,获取图片的title值作为图片的命名。
filename = parse_html2.xpath("//table[@id="endimg"]//tr//td//a/@title")
for e in filename:
# print(e)
dirname = "./王者荣耀/" + e + ".jpg"
html2 = requests.get(url=r, headers=self.headers).content
# print(html2)
print(dirname)
with open(dirname, "wb") as f:
f.write(html2)
print("%s下载成功" % filename)
8、在main方法调用,如下所示。因为第一页的网址是没有规律的,所以这里先判断一下是不是第一页。
def main(self):
startPage = int(input("起始页:"))
endPage = int(input("终止页:"))
for page in range(startPage, endPage + 1):
if page == 1:
url = self.firsr_url
else:
url = self.url.format(page)
# print(url)
html = self.get_page(url)
print("第%s页爬取成功!!!!" % page)
# print(html)
self.parse_page(html)
【六、效果展示】
1、运行程序,在控制台输入你要爬取的页数,如下图所示。
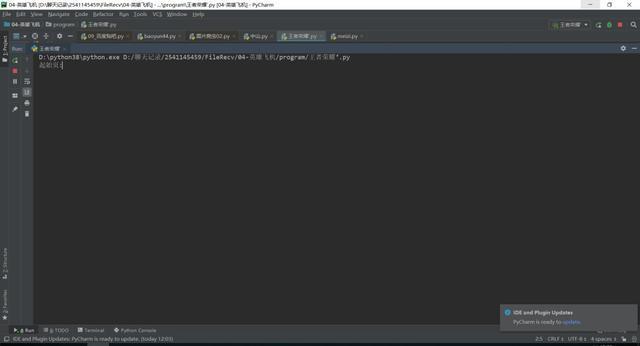
2、将下载成功的图片信息显示在控制台,如下图所示。
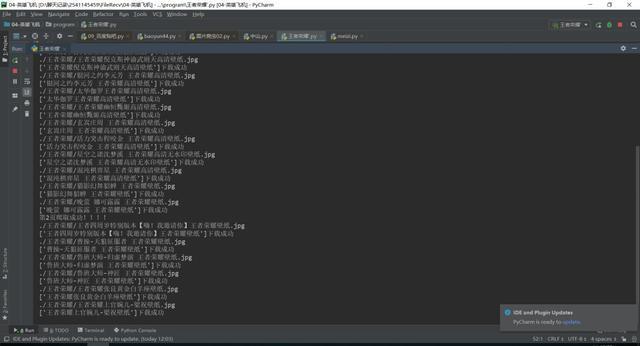
3、在本地可以看到效果图,如下图所示。

【七、总结】
1、不建议抓取太多数据,容易对服务器造成负载,浅尝辄止即可。
2、希望通过这个项目,能够帮助大家下载高清的图片。
3、本文基于Python网络爬虫,利用爬虫库,实现王者荣耀图片的抓取。实现的时候,总会有各种各样的问题,切勿眼高手低,勤动手,才可以理解的更加深刻。
4、英雄有很多,大家自行选择你喜欢的英雄做为你的桌面的壁纸吧。
5、需要本文源码的小伙伴,后台回复“王者荣耀”四个字,即可获取。
看完本文有收获?请转发分享给更多的人
IT共享之家
入群请在微信后台回复【入群】

想学习更多Python网络爬虫与数据挖掘知识,可前往专业网站:http://pdcfighting.com/
