面试高频算法详解-LRU

![面试高频算法详解-LRU
[编程语言教程]](https://www.zixueka.com/wp-content/uploads/2024/01/1706715300-a1adb6a058add4d.jpg)
以后将开通新的栏目《面试高频算法详解》,为大家介绍一些比较常考的稍微复杂一点的算法题,有兴趣的可以点赞关注加转发呀~

图源:pexels
01
题目介绍
题目描述:
leetcode 146 LRU缓存机制中等难度
运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制。它应该支持以下操作:获取数据 get 和写入数据 put 。
获取数据 get(key) – 如果密钥 (key) 存在于缓存中,则获取密钥的值(总是正数),否则返回 -1。
写入数据 put(key, value) – 如果密钥不存在,则写入其数据值。当缓存容量达到上限时,它应该在写入新数据之前删除最近最少使用的数据值,从而为新的数据值留出空间。
要求: O(1) 时间复杂度完成这两种操作
02
题目分析
概念
LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
重点
1 最近被访问的数据,其优先级最高;
2 优先级低的数据最先被清除;
时间复杂度
O(1)
03
可行方案
1 链表结构
使用链表结构保存缓存数据。
每当执行put操作时,遍历链表判断该数据是否为新数据:
若为新数据,则在链表头部新建节点并存放新数据;当链表长度超过缓存大小时,将链表尾部节点删除。
若为旧数据,则说明缓存数据命中,更新该缓存数据,并将命中的链表节点移到链表头部。
每当执行get操作时,通过遍历链表进行缓存数据的寻找:
若命中,则根据密钥(key)返回数据值(value),并将数据所在的链表节点置于链表头部;
若未命中,则说明该数据不在缓存中,返回-1。
问题:链表在使用的时候,为了确定是否命中,需要对链表结构进行遍历。时间复杂度为o(n),n为链表长度。未满足题目要求。
2 双向链表与哈希表结合
利用双向链表保存缓存数据,利用哈希表解决需要遍历寻找命中的问题。
双向链表中存放的是缓存数据;哈希表中的value值对应于双向链表中的节点地址。
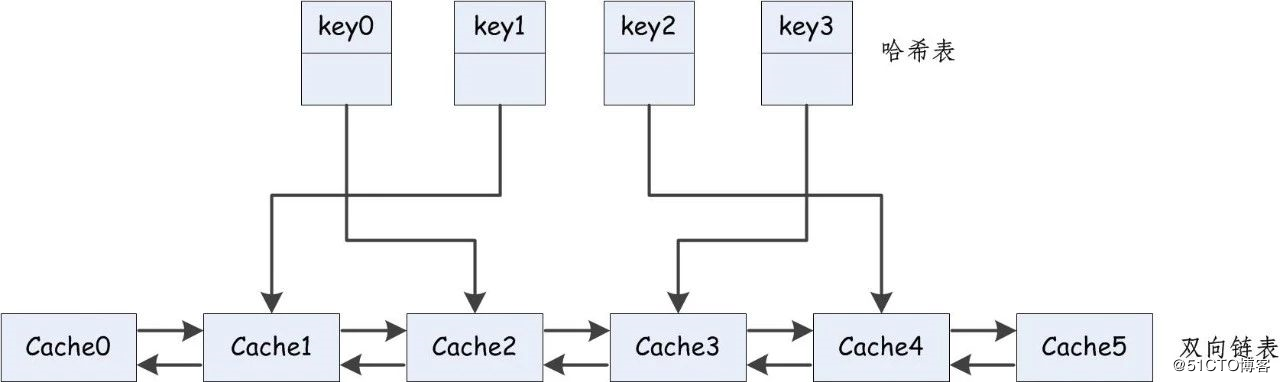
每当执行put操作时,先判断插入的键值对中的key是否存在与哈希表中:
若key已经存在,说明该数据命中缓存,则根据key对应的节点地址找到该缓存数据节点,更新该节点的数据值,并将该节点置于双向链表的头部,同时更新key所对应的节点地址。
若key不存在,说明该数据在缓存中未发生命中,则在双向链表头部创建新的节点存放新的数据,并在哈希表中添加新的key值与链表头部地址相对应。若链表长度大于缓存大小,则删除链表尾部节点以及对应的哈希表中的键值对。
每当执行get操作时,先判断插入的的键值对中的key是否存在与哈希表中:
若key已经存在,则可通过key值对应的链表中节点的地址,就可取得缓存数据;同时将该节点置于链表的头部并更新key对应的节点地址。
若对应的key不存在于哈希表中,即未发生命中,返回-1。
04
最终实现
说明
list 是C++ STL中容器,底层实现为双向循环链表,任意位置插入和删除时间复杂度0(1)。
unordered_map 同为C++ STL中容器,底层实现为哈希表。
C++代码:
熟悉其它语言的同学也可看看,理解其中算法思想。
class LRUCache {
public:
int size;
list<pair<int, int>> cache;
unordered_map<int, list<pair<int,int>>::iterator> map;
LRUCache(int capacity) {
size = capacity;
}
int get(int key) {
auto it = map.find(key);
if(it == map.end()) //判断key是否存在于哈希表中
return -1;
auto temp = *map[key];
cache.erase(map[key]); //删除命中节点
cache.push_front(temp); //在链表头部创建新的数据节点
map[key] = cache.begin(); //更新key所对应的节点地址
return temp.second;
}
void put(int key, int value) {
auto it = map.find(key);
if(it == map.end())
{
if(cache.size()==size) //若缓存已满
{
auto temp = cache.back(); //获得链表尾部节点
map.erase(temp.first); //删除尾部节点对应哈希表键值对
cache.pop_back(); //删除尾部节点
}
cache.push_front(make_pair(key,value)); //在链表头部插入新的数据节点
map[key] = cache.begin(); //更新key值对应的节点地址,指向链表头部
}
else
{
cache.erase(map[key]);
cache.push_front(make_pair(key,value));
map[key] = cache.begin();
}
}
};
/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache* obj = new LRUCache(capacity);
* int param_1 = obj->get(key);
* obj->put(key,value);
*/评析:
这种方案的实现实际上是最简单的一种LRU思想的表现,但是其利用效率不高。在某些情况下,会导致在重复位置的插入和删除,导致更新效率低下;同时由于哈希表本身的结构也会导致其插入和查询的效率不稳定。不过理解上述的实现能够对数据结构的结合和LRU算法有比较明确的了解。建议充分理解。
本文为来源业余码农,转载请联系本公众号获得授权。

推荐阅读(点击下方链接即可阅读)
建议简历写不好的同学进来瞧一瞧~
了解这些C++常用库,或许能够帮你找到合适的个人项目!
生物专业却能签约字节跳动,在大学期间他经历了什么
生物专业女生教你准备两个月签约AI独角兽
想成为BAT后台开发工程师,这些是基础!
Amazing10
承蒙厚爱。
面试高频算法详解-LRU
原文地址:https://blog.51cto.com/14888346/2514719
