1.2.1 最简单的String类型是怎么存储的 数据存储-数据类型之String


参考自https://www.cnblogs.com/kismetv/p/8654978.html
所有的key、及string型的数据都用SDS结构
1. 一个完整的string数据
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */ (如4.0版本占24比特,2.6版本占22比特)
int refcount;
void *ptr;
} robj;
tip
查看值的属性
debug object key`
1.1 type
- REDIS_STRING 字符串对象
1.2 encoding
1.2.1 long
如果符合数字条件(它判断长度是否小于等于20,并且尝试转化成整型),将直接存储为数字
从源码看直接将value作为引用
o->encoding = OBJ_ENCODING_INT;
o->ptr = (void*) value;
1.2.2 embstr
保存长度小于44字节的字符串(redis3.2版本之前是39字节,之后是44字节)
- 特点
embstr 编码的存储方式为 将 RedisObject 对象头和 SDS 对象连续存在一起,使用 malloc 方法一次分配内存
1.2.3 raw
保存长度大于44字节的字符串(redis3.2版本之前是39字节,之后是44字节)。
-特点
而 raw 它需要两次 malloc 分配内存,两个对象头在内存地址上一般是不连续的。
图示如下
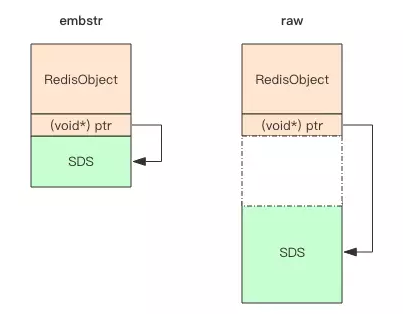
1.3 ptr
- 指向对应的数据 数字或者SDS结构
2. SDS(Simple Dynamic String)
2.1 结构
- 3.0
struct sdshdr {
int len;
int free;
char buf[];
};
-
buf数组的长度=free+len+1(其中1表示字符串结尾的空字符)
-
sds结构的长度 free所占长度+len所占长度+ buf数组的长度=4+4+free+len+1=free+len+9。
-
3.2以后
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
2.2 这种结构有什么好处
2.2.1 获取字符串长度:SDS是O(1),C字符串是O(n)
2.2.2 缓冲区溢出:
使用C字符串的API时,如果字符串长度增加(如strcat操作)而忘记重新分配内存,很容易造成缓冲区的溢出;而SDS由于记录了长度,相应的API在可能造成缓冲区溢出时会自动重新分配内存,杜绝了缓冲区溢出。
2.2.3 修改字符串时内存的重分配
对于C字符串,如果要修改字符串,必须要重新分配内存(先释放再申请),因为如果没有重新分配,字符串长度增大时会造成内存缓冲区溢出,字符串长度减小时会造成内存泄露。而对于SDS,由于可以记录len和free,因此解除了字符串长度和空间数组长度之间的关联,可以在此基础上进行优化:空间预分配策略(即分配内存时比实际需要的多)使得字符串长度增大时重新分配内存的概率大大减小;惰性空间释放策略使得字符串长度减小时重新分配内存的概率大大减小。
1. 预分配
如果对 SDS 修改后,如果 len 小于 1MB 那 len = 2 * len + 1byte。 这个 1 是用于保存空字节。
如果 SDS 修改后 len 大于 1MB 那么 len = 1MB + len + 1byte。
2.惰性释放
如果缩短 SDS 的字符串长度,redis并不是马上减少 SDS 所占内存。只是增加 free 的长度。同时向外提供 API 。真正需要释放的时候,才去重新缩小 SDS 所占的内存
2.2.4 存取二进制数据
SDS可以,C字符串不可以。因为C字符串以空字符作为字符串结束的标识,而对于一些二进制文件(如图片等),内容可能包括空字符串,因此C字符串无法正确存取;而SDS以字符串长度len来作为字符串结束标识,因此没有这个问题。
2.2.5 其他
此外,由于SDS中的buf仍然使用了C字符串(即以’’结尾),因此SDS可以使用C字符串库中的部分函数;但是需要注意的是,只有当SDS用来存储文本数据时才可以这样使用,在存储二进制数据时则不行(’’不一定是结尾)。
2.3 emstr/raw的选择(什么时候选择raw、什么时候选择emstr)
2.3.1 一切的前提:
内存分配器jemalloc分配的内存如果超出了64个字节就认为是一个大字符串,就会用到raw编码。
2.3.2 开始计算
redisObject大小 16Byte
- 固定大小(具体见1.1 redis所有数据如何存储的 之 内存模型)
sds 大小
3.2 之前
struct SDS {
unsigned int capacity; // 4byte
unsigned int len; // 4byte
byte[] content; // 内联数组,长度为 capacity
}
大小为8字节
计算结果:64-16-8-1(最后一位)=39字节
3.2之后
struct SDS {
int8 capacity; // 1byte
int8 len; // 1byte
int8 flags; // 1byte
byte[] content; // 内联数组,长度为 capacity
}
缩短为3字节
计算结果:64-16-3-1(最后一位)=44字节
2.3.3 总结
所以,redis 3.2版本之后embstr最大能容纳的字符串长度是44,之前是39。长度变化的原因是SDS中内存的优化。
#3. 结论
Redis在存储对象时,一律使用SDS代替C字符串。例如set hello world命令,hello和world都是以SDS的形式存储的。而sadd myset member1 member2 member3命令,不论是键(”myset”),还是集合中的元素(”member1”、 ”member2”和”member3”),都是以SDS的形式存储。除了存储对象,SDS还用于存储各种缓冲区。
只有在字符串不会改变的情况下,如打印日志时,才会使用C字符串。
