1.2.2 字典类型是怎么存储的 数据存储-数据类型之Dict

参考 https://www.jianshu.com/p/05bf8a945944
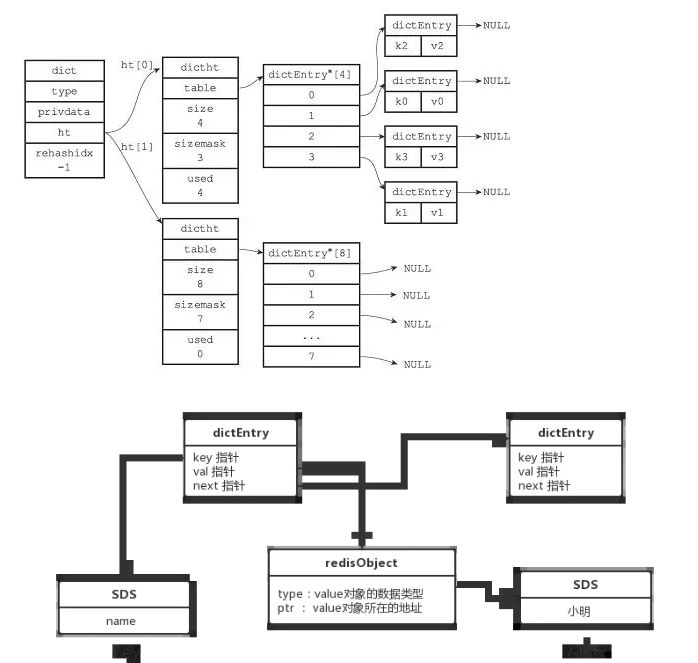
字典结构
https://github.com/antirez/redis/blob/unstable/src/dict.h
typedef struct dict {
// 特定于类型的处理函数
dictType *type;
// 类型处理函数的私有数据
void *privdata;
// 哈希表(2个)
dictht ht[2];
// 记录 rehash 进度的标志,值为-1 表示 rehash 未进行
int rehashidx;
// 当前正在运作的安全迭代器数量
int iterators;
}
dict;
typedef struct dictht {
dictEntry **table;// 二维
unsigned long size;// 第一维数组的长度
unsigned long sizemask;
unsigned long used;// hash 表中的元素个数
} dictht;
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
图示如下
基本操作
- 创建一个新字典 dictCreate O(1)
- 添加新键值对到字典 dictAdd O(1)
- 添加或更新给定键的值 dictReplace O(1)
- 在字典中查找给定键所在的节点 dictFind O(1)
- 在字典中查找给定键的值 dictFetchValue O(1)
- 从字典中随机返回一个节点 dictGetRandomKey O(1)
- 根据给定键,删除字典中的键值对 dictDelete O(1)
- 清空并释放字典 dictRelease O(N)
- 清空并重置(但不释放)字典 dictEmpty O(N)
- 缩小字典 dictResize O(N)
- 扩大字典 dictExpand O(N)
- 对字典进行给定步数的 rehash dictRehash O(N)
- 在给定毫秒内,对字典进行rehash dictRehashMilliseconds O(N)
初始化
ht0、ht1 的table初始化为null
- ht[0]->table 的空间分配将在第一次往字典添加键值对时进行;
- ht[1]->table 的空间分配将在 rehash 开始时进行;
增

1.添加新元素时table为空
1.初始化table 大小为4
#define DICT_HT_INITIAL_SIZE 4

2.添加元素

2.添加新键值对时发生碰撞
链表法解决碰撞,新元素插到前面

3.触发rehash
1. 触发条件
负载因子 ratio = used / size
- 自然 rehash : ratio >= 1 ,且变量 dict_can_resize 为true。
什么时候 dict_can_resize 会为false?
在前面介绍字典的应用时也说到过, 数据库就是字典, 数据库里的哈希类型键也是字典, 当 Redis 使用子进程对数据库执行后台持久化任务时(比如执行 BGSAVE 或 BGREWRITEAOF 时), 为了最大化地利用系统的 copy on write 机制, 程序会暂时将 dict_can_resize 设为false, 避免执行自然 rehash , 从而减少程序对内存的触碰(touch)。
当持久化任务完成之后, dict_can_resize 会重新被设为true。
- 强制 rehash : ratio 大于变量 dict_force_resize_ratio (目前版本中, dict_force_resize_ratio 的值为 5 )。
强制rehash与dict_can_resize无关
2.rehash 过程
-
初始化ht1
设置rehash标记(rehashidx =0) 创建一个比 ht[0]->table 更大的 ht[1]->table ;
ht1的大小至少为ht0的两倍

-
将 ht[0]->table 中的所有键值对迁移到 ht[1]->table ;
** 渐进式迁移,不是一次迁移,字典的 rehashidx 变量会记录 rehash 进行到 ht[0] 的哪个索引位置上** -
为什么要渐进式
– rehash的过程,会使用两个哈希表,创建了一个更大空间的ht[1],此时会造成内存陡增;
– rehash的过程,可能涉及大量KV键值对dictEntry的搬运,耗时较长; -
怎么进行渐进式
– 设置rehash状态
– 在执行add、delete、find操作时,都会判断dict是否正在rehash,如果是,就执行_dictRehashStep()函数,进行增量rehash
– 每次执行 _dictRehashStep , 会将ht[0]->table 哈希表第一个不为空的索引上的所有节点就会全部迁移到 ht[1]->table 。
也就是在某次dictAdd 添加键值对时,触发了rehash;后续add、delete、find命令在执行前都会检查,如果dict正在rehash,就先不急去执行自己的命令,先去帮忙搬运一个bucket;
搬运完一个bucket,再执行add、delete、find命令 原有处理逻辑。
rehash的单位是bucket,也就是从老哈希表dictht中找到第一个非空的下标,要把该下标整个链表搬运到新数组。
因为在 rehash 时,字典会同时使用两个哈希表,所以在这期间的所有查找dictFind、删除dictDelete等操作,除了在 ht[0] 上进行,还需要在 ht[1] 上进行。
在执行添加操作dictAdd时,新的节点会直接添加到 ht[1] 而不是 ht[0] ,这样保证 ht[0] 的节点数量在整个 rehash 过程中都只减不增。
```
- 将原有 ht[0] 的数据清空,并将 ht[1] 替换为新的 ht[0] ;
- 释放 ht[0] 的空间;
- 用 ht[1] 来代替 ht[0] ,使原来的 ht[1] 成为新的 ht[0] ;
- 创建一个新的空哈希表,并将它设置为 ht[1] ;
- 将字典的 rehashidx 属性设置为 -1 ,标识 rehash 已停止

查
- 根据hash算法计算key在数组中的坐标,然后在相应的链表中通过对比key(dictCompareKeys)确定value值
- 如果hash进行中,再在ht1中走一遍上面的逻辑
删
同查 查到了就能删
同样 字典的key变少之后
即可用节点数比已用节点数大很多的话, 那么也可以通过对哈希表进行 rehash 来收缩(shrink)字典。
过程与rehash相类似
改
同查
HASH 算法
- MurmurHash2
是种32 bit 算法:这种算法的分布率和速度都非常好;Murmur哈希算法最大的特点是碰撞率低,计算速度快。Google的Guava库包含最新的Murmur3。
具体信息请参考 MurmurHash 的主页: http://code.google.com/p/smhasher/ 。 - 基于 djb 算法实现的一个大小写无关散列算法:具体信息请参考 http://www.cse.yorku.ca/~oz/hash.html 。
算法的应用
- 命令表以及 Lua 脚本缓存都用到了算法 2 。
- 算法 1 的应用则更加广泛:数据库、集群、哈希键、阻塞操作等功能都用到了这个算法。
字典dict的主要用途有以下两个:
- 实现数据库键空间(key space);
- 用作 hash 键的底层实现之一;
- 压缩列表ziplist ;
- 字典dict;