Python爬虫之urllib模拟登录及cookie的那点事 – 人丑就要多读书

在web sprider crawl过程中,许多网站都需要登录后才能访问,一般如果我们不用爬虫框架的前提下,常规用的就两个库 ,urllib库和requests库,本文将用最基础的urllib库,以模拟登录人人网为例,理清爬虫过程中登录访问和cookie的思绪。
1.终极方案,也是最简单粗暴最有效的方式。直接手动登录,提取cookie,下次访问直接在请求头携带cookie
我们知道,网站辨别用户身份和保持会话的常用方式就是cookie和session,用户登录成功,服务器返回一些特定字符串保存在本地浏览器中(cookie),浏览器下次访问会直接携带cookie,这样服务器就可以根据返回的cookie验证访问者身份。通常如果用浏览器正常访问,这部分事情浏览器会帮我们去做。但是在程序模拟登 录时候,携带cookie就需要手动携带了。话不多说,直接进入主题。
打开人人网登录界面,填入自己正确的用户名和密码,成功登陆进去。
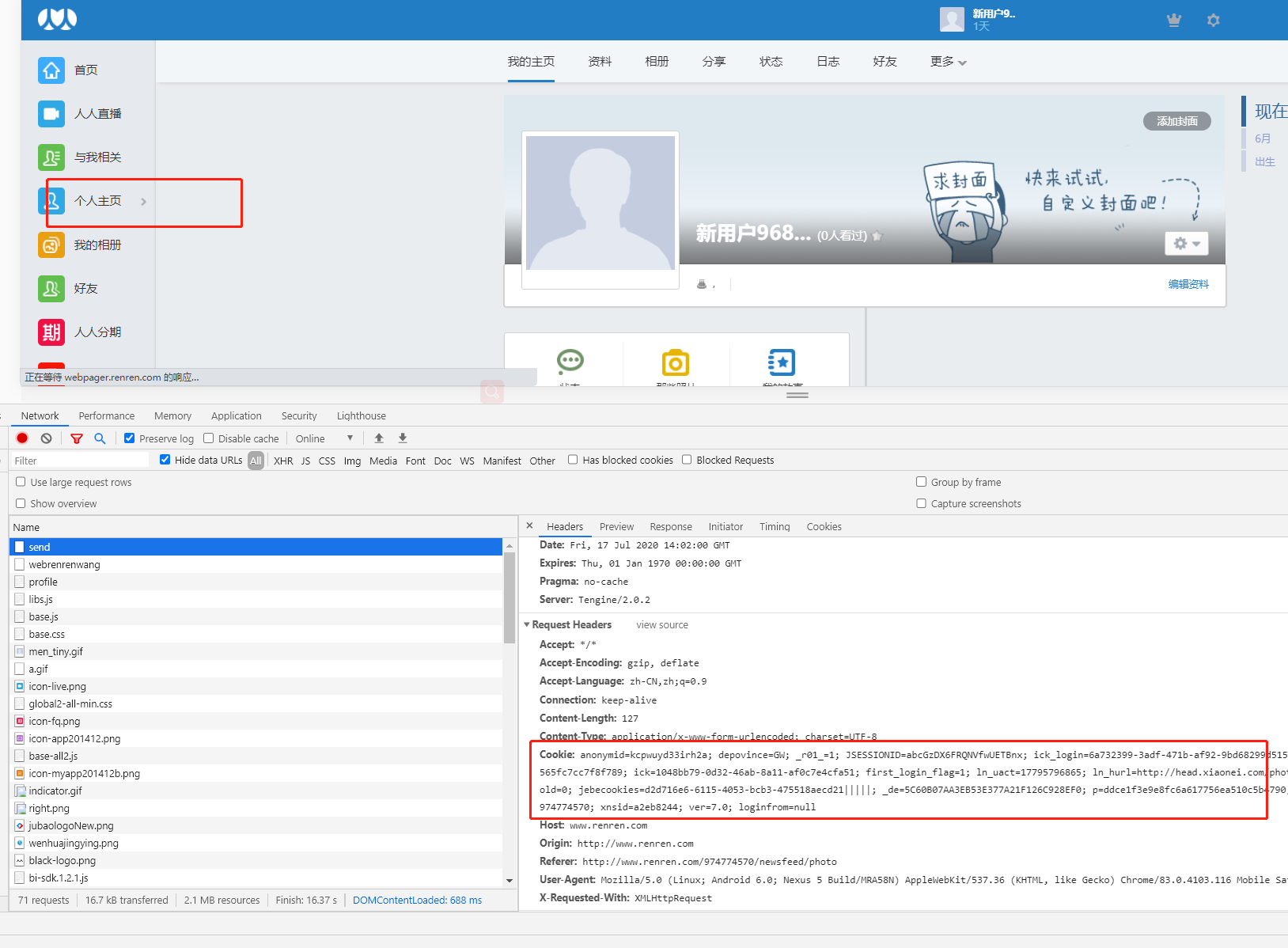
其中红色框的就是服务器给你的cookie,你的cookie就是以这样的形式在request请求头中的。直接将其复制粘贴下来,放入代码中。上程序:
"""
首先手动登录人人网,然后获取cookie
"""
from urllib.request import urlopen, Request
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
# "Accept-Encoding": "gzip, deflate", 这部分通常注释掉,因为这部分是高诉服务器,本地支持的压缩类型,因为浏览器会自动帮我们解压,但是在程序中,没办法解压,所以请求头就不携带了
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"Cookie": "anonymid=kcpawuyd33irh2a;depovince=GW;r01_=1; JSESSIONID=abcGzDX6FRQNVfwdUETBnx;ick_login=6a732399-3adf-471b-af92-9bd68299d515;
taihe_bi_sdk_uid=e4c3ee72270319312dde3088eb04c0be; taihe_bi_sdk_sefssion=6722a32d96ebbf8fd565fc7cc7f8f789;ick=1048bb79-0d32-46ab-8a11-af0c7e4cfa51;first_login_flag=1;
ln_uact=17795796865;ln_hurl=http://head.xiaonei.com/photos/0/0/men_main.gif; ga=GA1.2.2124318841.1594975538;gid=GA1.2.506855365.1594975538;
wp_fold=0;jebecookies=3833d4fe-20b3-4ecf-9efc-df9aca93641e|||||;de=5C6d0B07AA3EB53E377A21F126C928EF0; p=d3ae1effe255d4e057ef37f5682ac4850;
t=ba23da27a155cc2b84a43307e83b37a70;societyguester=ba23da27a155cc2b84a4f3307e83b37a70;id=974774570;xnsid=a3c6bde2;ver=7.0;loginfrom=null",
"Host": "www.renren.com",
"Referer": "http://www.renren.com/974774570/profile""Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Mobile Safari/537.36"
}
url = "http://www.renren.com/974774570/profile" #个人主页
request = Request(url=url, headers=headers)
response = urlopen(request)
print(response.read().decode())