Python数据分析:基于Pandas数据清洗
针对数据统计分析来讲,数据信息是无可置疑的核心内容。但并非是全部的数据信息都是有价值的,绝大部分数据信息是良莠不齐的,基本概念层次不清的,量级有所不同的,这就给后期的数据统计分析和数据挖掘造成 了很大的不便,甚至是造成不正确的理论依据。因此很有必要对数据信息开展预处理。
说到python与数据分析,那肯定少不了pandas的身影。
一、数据清洗是什么
数据清洗是指发现并纠正数据文件中可识别的错误的最后一道程序,包括检查数据一致性,处理无效值和缺失值等。与问卷审核不同,录入后的数据清理一般是由计算机而不是人工完成。
数据清洗从名字上也看的出就是把“脏”的“洗掉”,指发现并纠正数据文件中可识别的错误的最后一道程序,包括检查数据一致性,处理无效值和缺失值等。因为数据仓库中的数据是面向某一主题的数据的集合,这些数据从多个业务系统中抽取而来而且包含历史数据,这样就避免不了有的数据是错误数据、有的数据相互之间有冲突,这些错误的或有冲突的数据显然是我们不想要的,称为“脏数据”。我们要按照一定的规则把“脏数据”“洗掉”,这就是数据清洗。而数据清洗的任务是过滤那些不符合要求的数据,将过滤的结果交给业务主管部门,确认是否过滤掉还是由业务单位修正之后再进行抽取。不符合要求的数据主要是有不完整的数据、错误的数据、重复的数据三大类。数据清洗是与问卷审核不同,录入后的数据清理一般是由计算机而不是人工完成。
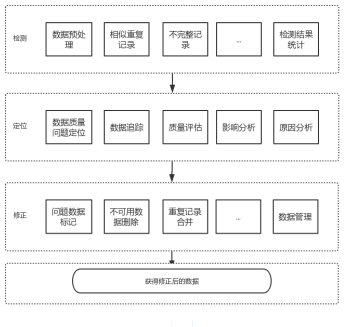
二、Python pandas数据清洗流程
1.导入方法read_excel
# 导入数据
import pandas as pda
import matplotlib.pylab as pyl
a = pda.read_excel("D:迅雷下载工具表格练习.xls") # 路径使用双反斜杠,否则会报错
print(len(a)) # 数据框的长度,是按行统计的
123456
2.发现缺失值
先打开excel表,查看下有多少缺失值,缺失值是指值为0或空统计发现有10个缺失值,同理其他列也有部分缺失值然后着手把0值置空,保证所有的缺失值都是统一形式,方便处理
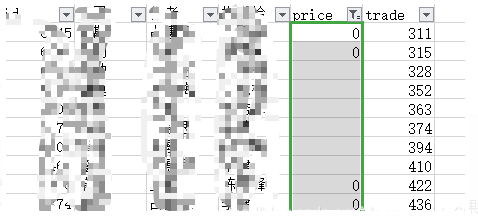
b = ["price", "trade"] for i in b: a[i][(a[i] == 0)] = None # a["price"] == 0 判断语句,返回True或False ,对列表的每一个值进行判断,如果有0,该处值置为none,然后进行判断直至完成 1234
3.缺失值处理
遍历所有的空值,统一赋值
x = 0 for j in b: for k in range(len(a)): if (a[j].isnull())[k]: a[j][k] = 36 x += 1 print(x)
三、异常数据处理
异常数据指数据库或数据仓库中未满足一般规律的数据信息对象,又叫作孤立点。异常的数据信息可由执行程序出现失误形成,也可能会因设施设备内部故障造成的。异常数据信息可能是删去的噪声,也可能是带有重要信息的数据单元。异常的数据信息的监测具体有根据统计学、根据距离和根据偏离3类方法。采取数据信息审时的办法能够实现异常的数据信息的智能化监测,该办法也叫作数据质量挖掘(DOQM)。DQM具体由2步组成:第1步,采取数理统计办法对数据分布展开概化描述,自动获得数据信息的总体分布特征;第2步针对特定的数据质量问题展开挖掘以发现数据信息异常的。
来源:PY学习网:原文地址:https://www.py.cn/article.html