王者荣耀五周年,爬取102个英雄+326款皮肤,分析上线时间

![王者荣耀五周年,爬取102个英雄+326款皮肤,分析上线时间[Python常见问题]](https://www.zixueka.com/wp-content/uploads/2023/10/1696831082-cbd4f85403ff092.jpg)
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理
以下文章来源于可以叫我才哥 ,作者可以叫我才哥
1.概述
《王者荣耀》上线至今5个年头了,作为这些年国内最热门的手游(没有之一),除了带来游戏娱乐之外,我们在这五周年之际,试着从他们的官网找点乐趣,学习一下Python爬虫的一些简单基础操作。
本篇将主要介绍简单的Python爬虫,包括网页分析、数据请求、数据解析和数据保存,适用于基本不带反爬的一些网站,旨在进行学习交流,请勿用作任何商业非法用途。
网页分析其实就是打开你需要请求数据的网页,然后「F12」看下这个网页源数据长啥样(如果你会web知识会更好处理,不过我没系统学过,操作多了就熟悉一点);
数据请求我们用人见人爱的「requests」库,关于该库的更详细用法大家可以去查询该链接了解(https://requests.readthedocs.io/zh_CN/latest/);
数据解析一般视请求的数据格式而定,如果请求的数据是html格式,我将介绍「bs4」和「xpath」两种方式进行解析,若请求的数据是json格式,我将介绍json和eval两种方式进行解析;
数据保存这里分为两种情况,如果是图片类会用到「open」和「write」函数方法,若是文本类的我会用到pandas的「to_excel」保存为表单格式。
2.网页分析
我们在概述说提到请求的数据会有html格式或者json格式,两种情况下其实对应的真实请求地址是有差异的,怎么判断呢,作为初学者我的个人经验就是去试试,本章节两种尝试方案都会介绍,大家在实操中视情况而选吧!
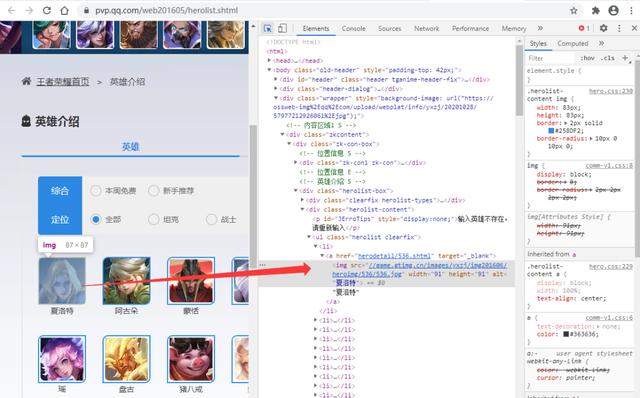
2.1.html页面源数据
以下面这张英雄列表页面为例,按住“「F12」”,然后点一下开发者模式中左上角的那个有鼠标箭头的图标,再在左侧选取你需要的数据区域,在开发者模式区域就会出现这个数据区域的数据信息,比如这里的“详情页地址”、“头像图片地址”和“名称”,我们需要的也算这些信息,所以可以直接请求该链接即可。