Python批量爬取华语天王巨星周杰伦的音乐

![Python批量爬取华语天王巨星周杰伦的音乐[Python基础]](https://www.zixueka.com/wp-content/uploads/2023/10/1696831157-d5f9bcc781a67d0.jpg)
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
python免费学习资料以及群交流解答点击即可加入
小伙伴说想听周杰伦的音乐,有什么网站是可以免费听的,然后他发现咪咕音乐可以免费听周杰伦的歌曲,既然可以免费听,那岂不是可以爬了~
基本开发环境
- Python 3.6
- Pycharm
import requests
import parsel
相关模块 pip 安装即可
目标网站分析
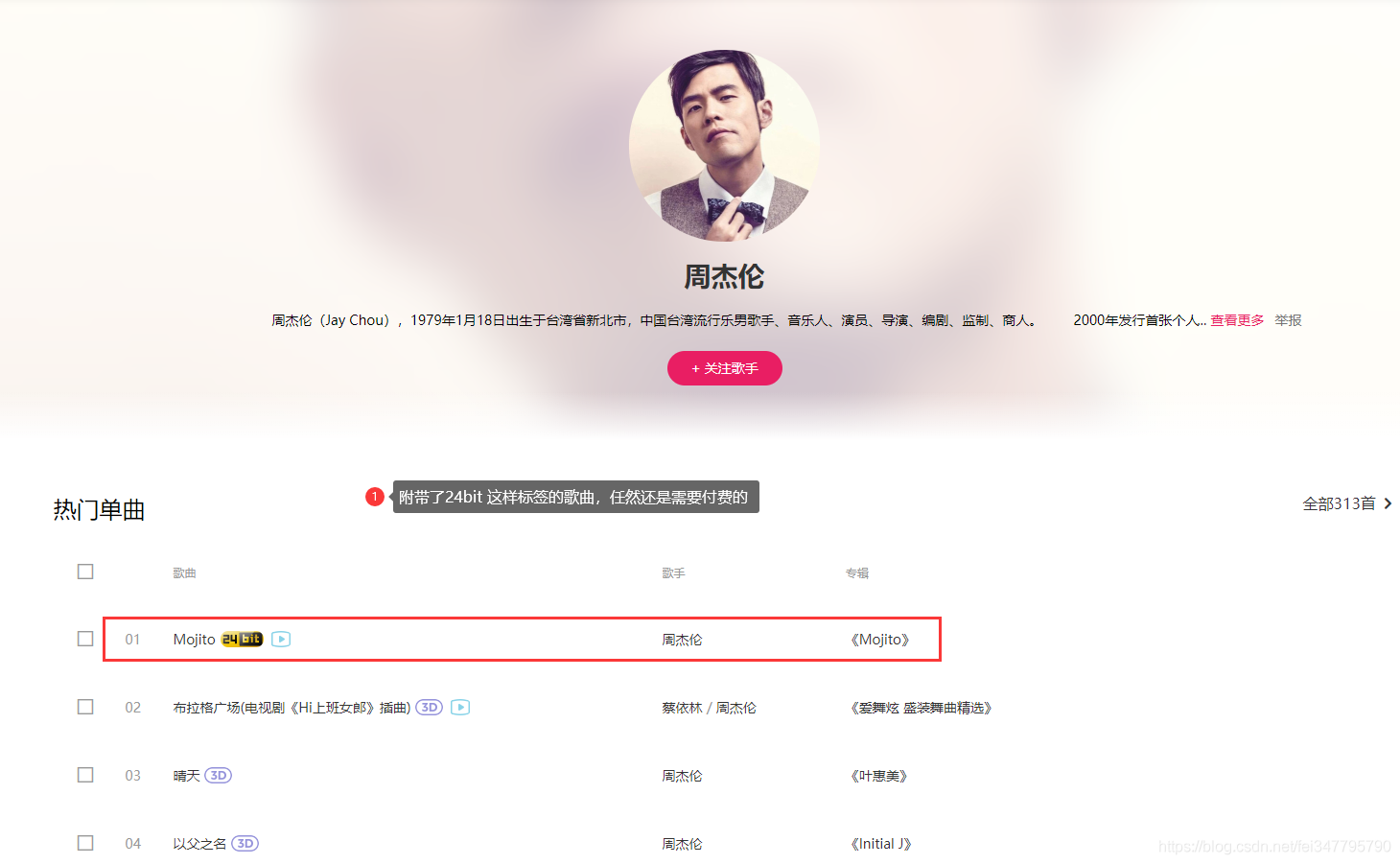
点击播放按钮,会自动跳转到音乐播放页面
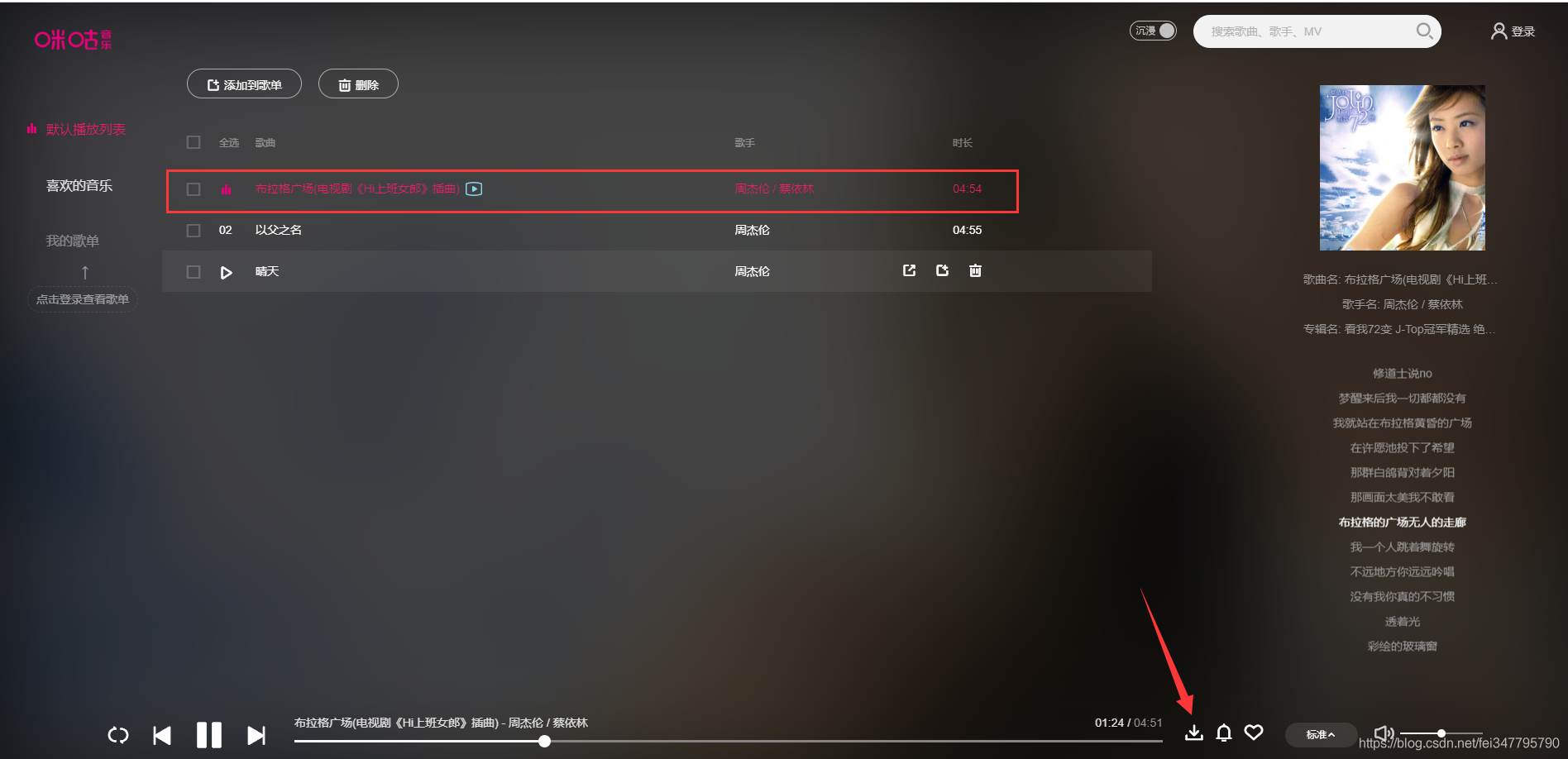
播放界面有一个下载按钮,点击下载。
是需要登陆账号
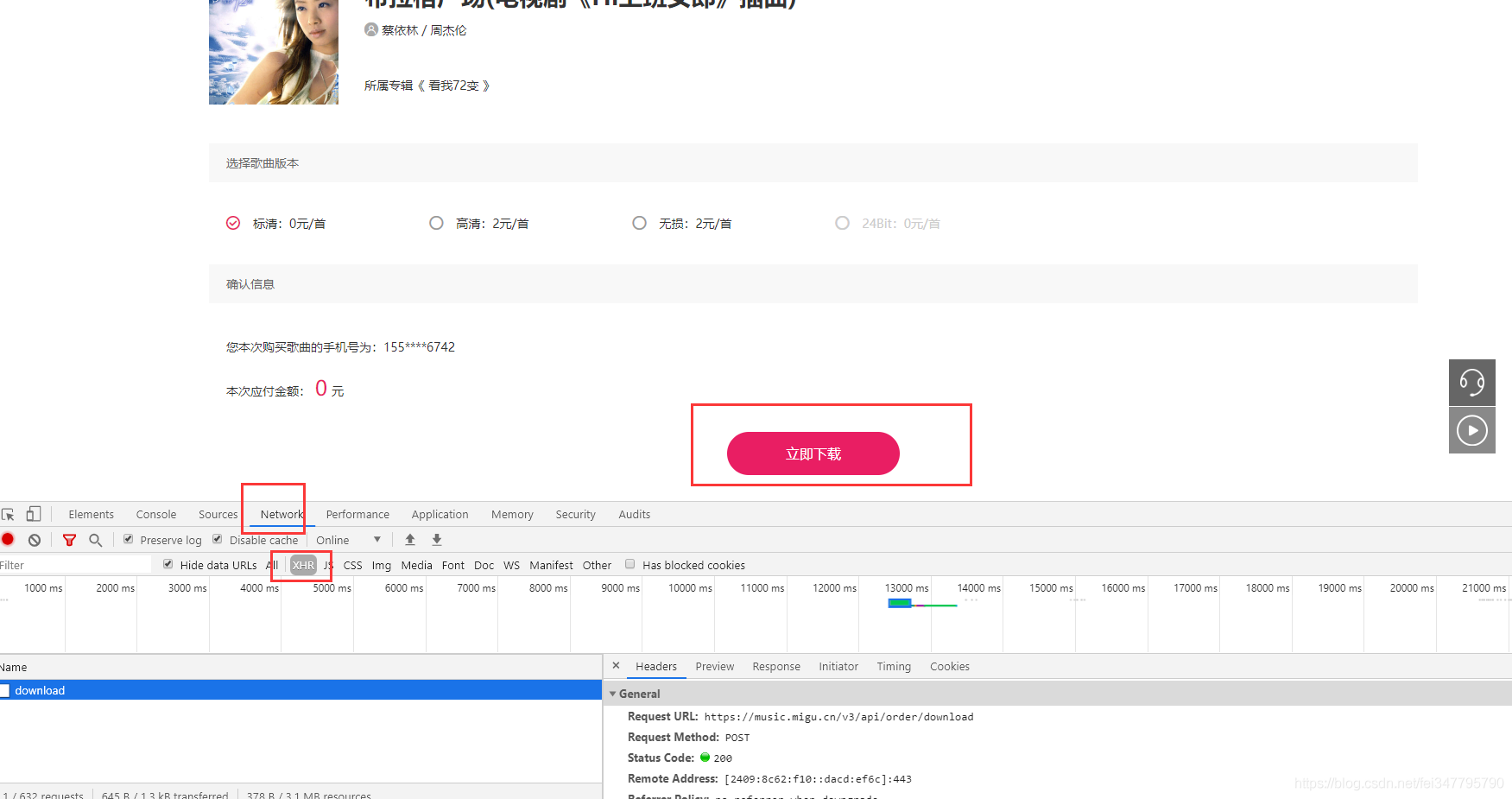
- 打开开发者工具
- 选择network
- 点击立即下载
会有一个下载的数据接口,post请求的数据接口,里面返回的数据有携带音频真实地址。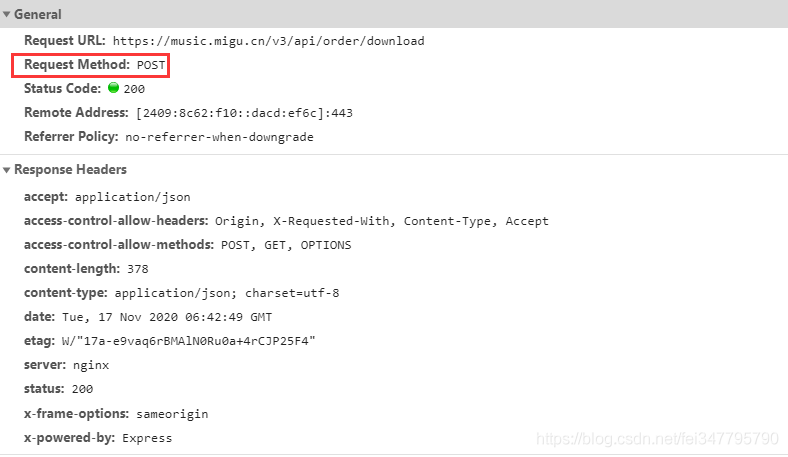


复制url地址,是会自动下载文件到本地的
既然是post请求,只需要看data参数的变化,看它需要传递那些参数
多查看几首歌曲的下载氢气,就可以发现 copyrightId 就是每首音乐的ID值,只需要获取每首歌曲的ID值,就可以下载音乐了。
所以返回到周杰伦的音乐列表页
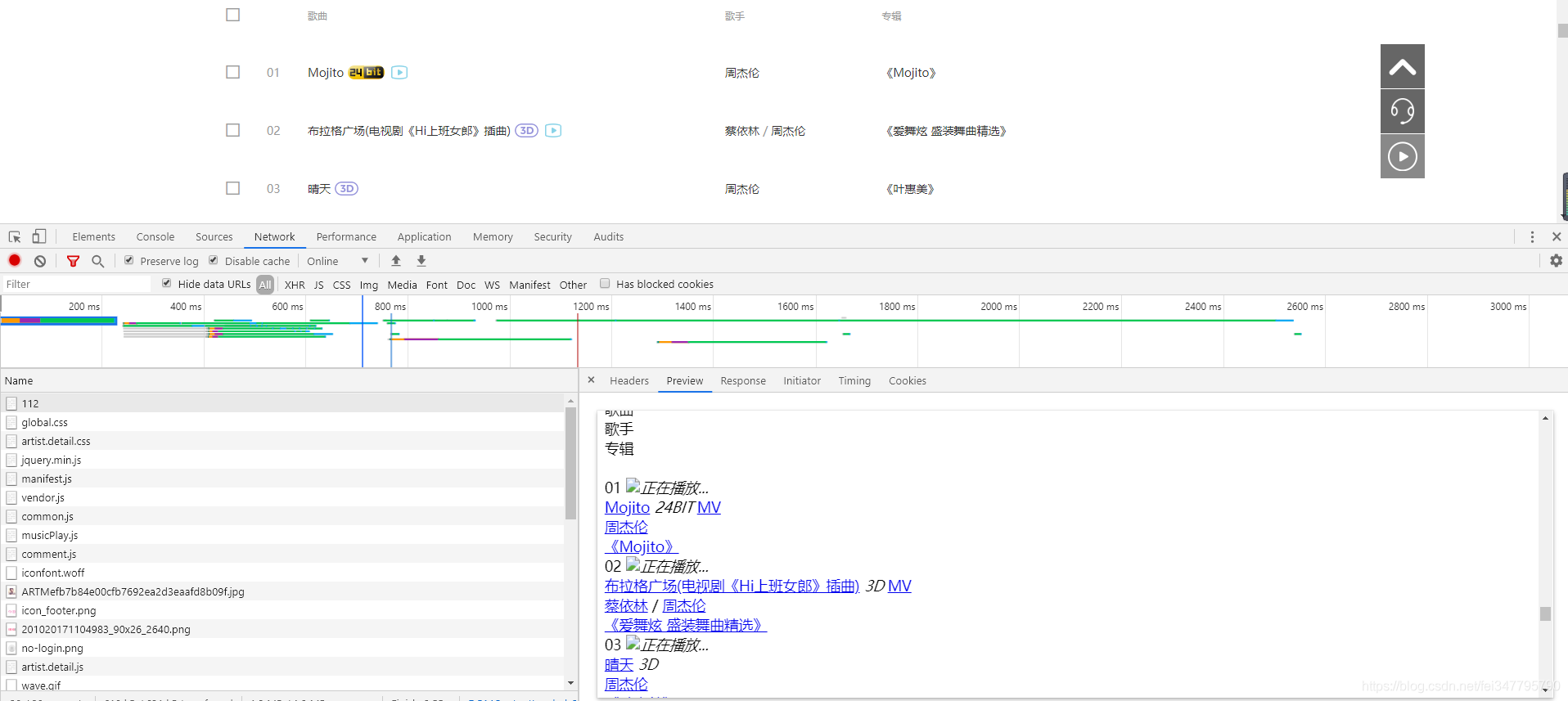
可以发现音乐列表页是静态网站,获取可以直接用过requests请求网站解析网站数据,可以获取音乐的ID值以及标题。
现在就是剩下最后一个问题了,那就是翻页,多页获取。
对于翻页爬取,只需要点击下一页,查看url地址的变化,找到其对应的变化规律即可。

page就是对应的页码,所以翻页爬取也搞定了,接下来就是写代码就好了
1、请求网页获取音乐的ID值以及标题
cookie 我就不带了,你可以自己登陆咪咕音乐之后复制开发者工具里面的
ef get_mp3_info(url):
headers = {
"cookie": "",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36"
}
response = requests.get(url=url, headers=headers)
selector = parsel.Selector(response.text)
lis = selector.css("#J_PageSonglist > div.songlist-body > div")
for li in lis:
page_url = li.css(".song-name-txt::attr(href)").get()
mp3_id = page_url.split("/")[-1]
title = li.css(".song-name-txt::attr(title)").get()
2、post请求获取音乐下载地址
这里 headers 参数可以不用写这么多,为了方便就直接复制粘贴了,因为是post请求,有一些参数是必要带的,不然得到想要的返回结果。
def get_mp3_url(mp3_id, title):
url = "https://music.migu.cn/v3/api/order/download"
headers = {
"authority": "music.migu.cn",
"method": "POST",
"path": "/v3/api/order/download",
"scheme": "https",
"accept": "*/*",
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9",
"cache-control": "no-cache",
"content-length": "42",
"content-type": "application/x-www-form-urlencoded; charset=UTF-8",
"cookie": "",
"origin": "https://music.migu.cn",
"pragma": "no-cache",
"referer": "https://music.migu.cn/v3/music/order/download/60054701923",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36",
"x-requested-with": "XMLHttpRequest",
}
data = {
"copyrightId": "{}".format(mp3_id),
"payType": "01",
"type": "1"
}
response = requests.post(url=url, data=data, headers=headers)
html_data = response.json()
mp3_url = html_data["downUrl"]
3、保存音乐至本地
保存代码还是比较简单,也是常用的 with open
def download(download_url, title):
response = requests.get(url=download_url)
path = "音乐" + title + ".mp3"
with open(path, mode="wb") as f:
f.write(response.content)
具体实现效果
有一部分的音乐任然还是需要付费的,所以当你post请求付费音乐的时间,是没有下载地址的,可以写一个判断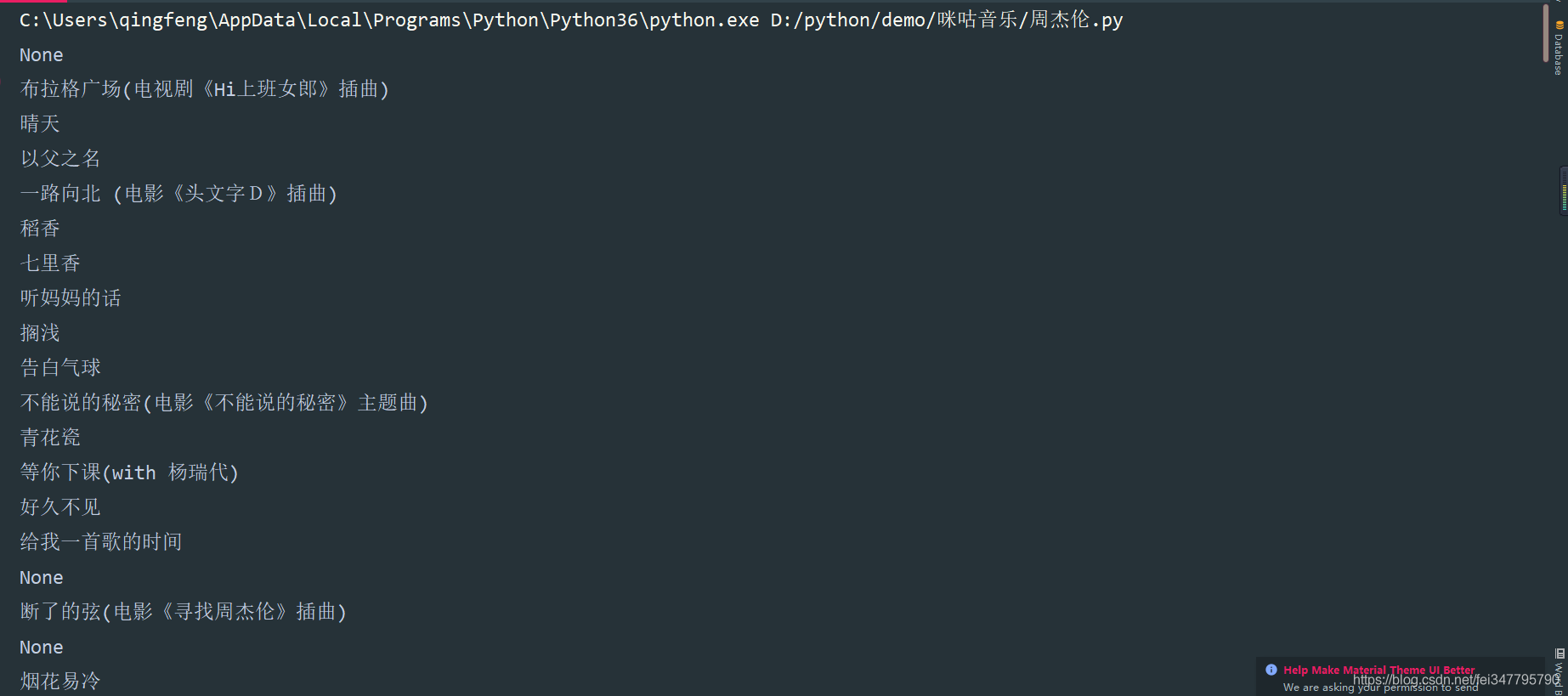
总结
代码可以优化,这只是最简易版本的爬虫代码,下载速度并不是很快,可以使用多线程爬取,速度更佳,可以自己去动手优化。
爬虫不难,主要是在于分析网站,除非涉及严重加密的网站,比如字体加密,JS数据加密,这些基本大部分网站,只需要花点心思分析网站的数据,就可以爬取了。
字体加密的网站其实也不难,主要是爬取的过程有点繁杂。加油吧
