PyThon教程实例:了解python多线程
很多人认为学习多线程的意义不大,能直接达到目的的,为什么要凑出多条道路呢?其实计算机里的程序没有一个是独立的,相关之间都所有关联,而这需要用到多线程,这就是目前大势所趋——python多线程。
大家可以根据以下Python多线程的实例应用和结合现有认知更深刻了解python多线程。
在Python 3中已经内置了_thread和threading两个模块来实现多线程。相较于_thread,threading提供的方法更多而且更常用,因此接下来我们将举例讲解threading模块的用法,首先来看下面这段代码:
import threading
import time
def say_after(what, delay):
print (what)
time.sleep(delay)
print (what)
t = threading.Thread(target = say_after, args = ('hello',3))
t.start()
1、这里我们导入了threading这个Python内置模块来实现多线程。之后定义了一个say_after(what, delay)函数,该函数包含what和delay两个参数,分别用来表示打印的内容,以及time.sleep()休眠的时间。
2、随后我们使用threading的Thread()函数为say_after(what, delay)函数创建了一个线程并将它赋值给变量t,注意Thread()里的target参数对应的是函数名称(即这里的say_after),args对应的是该say_after函数里的参数,这里等同于“what = ‘hello’”,“delay = 3”。
3、最后我们调用threading中的start()来启动我们刚刚创建的线程。
运行代码效果:

在打印出第一个hello后,程序因为time.sleep(3)休眠了三秒,三秒之后随即打印出了第二个hello。因为这时我们只运行了say_after(what, delay)这一个函数,并且只运行了一次,因此即使我们现在启用了多线程,我们也感受不了它和单线程有什么区别。接下来我们将该代码修改如下:
#coding=utf-8
import threading
import time
def say_after(what, delay):
print (what)
time.sleep(delay)
print (what)
t = threading.Thread(target = say_after, args = ('hello',3))
print (f"程序于 {time.strftime('%X')} 开始执行")
t.start()
print (f"程序于 {time.strftime('%X')} 执行结束")
这一次我们调用time.strftime()来尝试记录程序执行前和执行后的时间,看看有什么“意想不到”的结果。
运行代码效果:
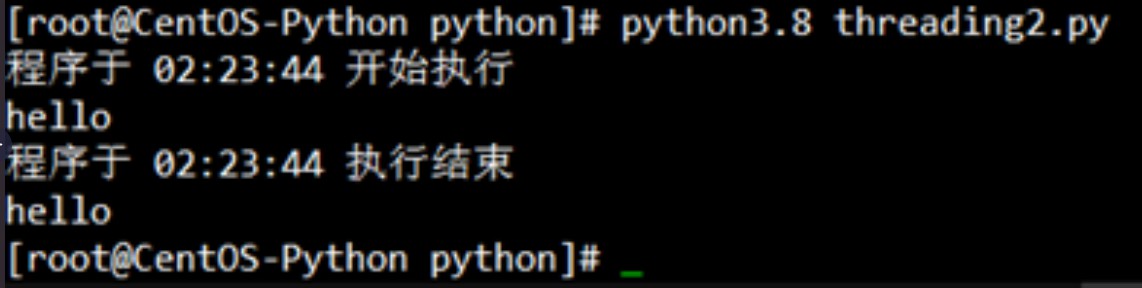
这里除了threading.Thread()为say_after()函数创建的用户线程外,“print (f"程序于 {time.strftime('%X')} 开始执行")”和“print (f"程序于 {time.strftime('%X')} 执行结束")”两个print()函数也共同占用了公用的内核线程。也就是说该脚本现在实际上是调用了两个线程:一个用户线程,一个内核线程,也就构成了一个多线程的环境。因为分属不同的线程,say_after()函数和函数之外的两个print语句是同时运行的,互不干涉。
如果想要正确捕捉say_after(what, delay)函数开始和结束时的时间,我们需要额外使用threading模块的join()方法,来看下面的代码:
#coding=utf-8
import threading
import time
def say_after(what, delay):
print (what)
time.sleep(delay)
print (what)
t = threading.Thread(target = say_after, args = ('hello',3))
print (f"程序于 {time.strftime('%X')} 开始执行")
t.start()
t.join()
print (f"程序于 {time.strftime('%X')} 执行结束")
这里我们只修改了代码的一处地方,即在t.start()下面添加了一个t.join(),join()方法的作用是强制阻塞调用它的线程,直到该线程运行完毕或者终止为止(类似于单线程同步)。因为这里调用join()方法的变量t正是我们用threading.Thread()为say_after(what, delay)创建的用户线程,因此使用内核线程的“print (f"程序于 {time.strftime('%X')} 执行结束")”必须等待该用户线程执行完毕过后才能继续执行,因此脚本在执行时的效果会让你觉得整体还是以“单线程同步”的方式运行的。
运行代码效果:
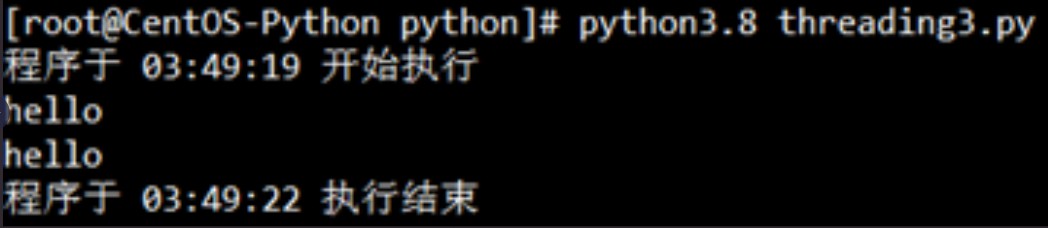
最后我们再举一例,来看看创建多个用户线程并运行,代码如下:
#coding=utf-8
import threading
import time
def say_after(what, delay):
print (what)
time.sleep(delay)
print (what)
print (f"程序于 {time.strftime('%X')} 开始执行
")
threads = []
for i in range(1,6):
t = threading.Thread(target=say_after, name="线程" + str(i), args=('hello',3))
print(t.name + '开始执行。')
t.start()
threads.append(t)
for i in threads:
i.join()
print (f"
程序于 {time.strftime('%X')} 执行结束")
这里我们使用for循环配合range(1,6)创建了5个线程,并且将它们以多线程的形式执行,也就是把say_after(what, delay)函数以多线程的形式执行了5次。每个线程作为元素加入进了threads这个空列表,然后我们再次使用for语句来遍历现在已经有了5个线程的threads列表,对其中的每个线程都调用的join()方法,确保直到它们都执行结束后,我们才执行内核线程下的“print (f"程序于 {time.strftime('%X')} 执行结束")”。
运行代码效果:
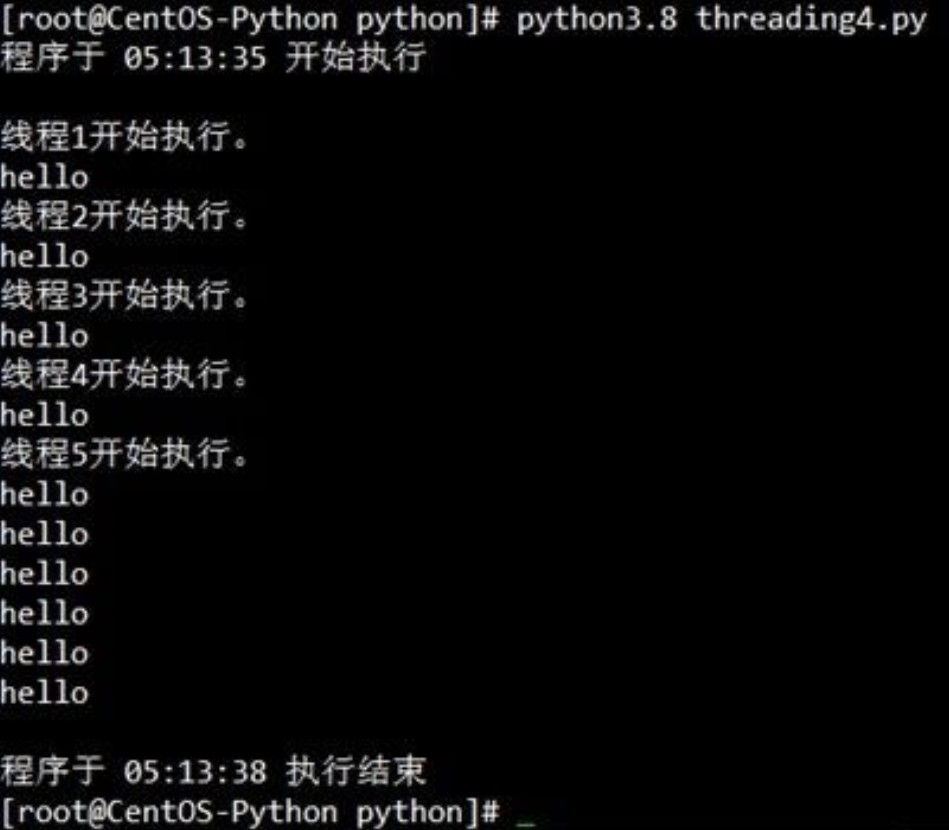
可以看到这里我们成功的使用了多线程将程序执行,如果以单线程来执行5次say_after(what,delay)函数的话,那么需要花费3×5=15秒才能跑完整个脚本,而在多线程的形式下,整个程序只花费了3秒就运行完毕。
根据以上示例,大家应该了解python多线程大势所趋的意义了吧,如需了解更多python实用知识,点击进入云海天Python教程网。
来源:PY学习网:原文地址:https://www.py.cn/article.html