dataframe的一些用法

![dataframe的一些用法[Python基础]](https://www.zixueka.com/wp-content/uploads/2023/10/1696831540-d9bf6f6bb2df883.jpg)
pandas中Dataframe的一些用法
pandas读取excel文件
- pd.read_excel 前提是安装xlrd库
dataframe,numpy,list之间的互相转换
- dataframe转numpy :dataframe对象.values
- dataframe转list:dataframe对象.values.tolist()
- list转numpy:np.array(list对象)
- list转dataframe:pd.DataFrame(list对象)
- numpy转list:numpy对象.tolist()
- numpy转dataframe:pd.DataFrame(numpy对象)
dataframe 按行遍历,按列遍历
-
按行遍历:
常用df.iterrows()
import pandas as pd demo_list = [[1,2], [3,4]] #用list构建dataframe demo_df = pd.DataFrame(demo_list) print(demo_df)

#接上
for row in demo_df.iterrows():
print(type(row))
print(row[0])
print(row[1])

可以看到每个row的类型是tuple元组类型,元组长度为2,元组第0个元素为index,第1个元素为横向的series。**值得注意的是,在遍历过程中如果取每一行的某个值,通过对row[1]进行切片即可。 **
-
按列遍历
经常使用df.columns获取列名然后访问
#接上 print(demo_df.columns) for column in demo_df.columns: print(demo_df[column])

dataframe之使用iloc切片
- 先构建dataframe
import numpy as np
import pandas as pd
##list构建5x5的dataframe,由于dataframe没有reshape,因此需要借助numpy
demo_list = [i for i in range(25)]
demo_np = np.array(demo_list).reshape(5,5)
demo_df = pd.DataFrame(demo_list)
print(demo_df)
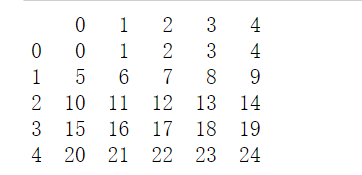
- iloc[start:end ,start :end ]表示按行列取出dataframe的值。其中逗号前面表示行,逗号后面表示列。冒号左侧表示开始,冒号右侧表示结束(遵循左闭右开原则)。例如,demo_df.iloc[2:4,1:3]表示切片第二行到第三行 第一列到第二列数据。 切片返回的数据类型还是dataframe。
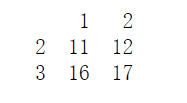
- iloc[start: end :step,start:end :step]是在上一个切片的基础上加上了步长。表示从start到end每step步取一次值。
dataframe 中缺失值的处理
-
均值填充
通常使用fillna()
##获取存在缺失值的列名列表 null_columns=list(file_df.columns[file_df.isnull().sum() > 0]) for column in null_columns : #计算每一列的均值 mean_val = file_df[column].mean() #使用fillna进行均值填充 file_df[column].fillna(mean_val, inplace=True)
