基于PaddlePaddle的图片分类实战 | 深度学习基础任务教程系列

![基于PaddlePaddle的图片分类实战 | 深度学习基础任务教程系列[Python框架]](https://www.zixueka.com/wp-content/uploads/2024/03/1711733714-26eb659f5d8bccd.jpg)
图像相比文字能够提供更加生动、容易理解及更具艺术感的信息,图像分类是根据图像的语义信息将不同类别图像区分开来,是图像检测、图像分割、物体跟踪、行为分析等其他高层视觉任务的基础。图像分类在安防、交通、互联网、医学等领域有着广泛的应用。
一般来说,图像分类通过手工提取特征或特征学习方法对整个图像进行全部描述,然后使用分类器判别物体类别,因此如何提取图像的特征至关重要。基于深度学习的图像分类方法,可以通过有监督或无监督的方式学习层次化的特征描述,从而取代了手工设计或选择图像特征的工作。深度学习模型中的卷积神经网络(Convolution Neural Network, CNN) 直接利用图像像素信息作为输入,最大程度上保留了输入图像的所有信息,通过卷积操作进行特征的提取和高层抽象,模型输出直接是图像识别的结果。这种基于"输入-输出"直接端到端的学习方法取得了非常好的效果。
本教程主要介绍图像分类的深度学习模型,以及如何使用PaddlePaddle在CIFAR10数据集上快速实现CNN模型。
项目地址:http://paddlepaddle.org/documentation/docs/zh/1.3/beginners_guide/basics/image_classification/index.html
基于ImageNet数据集训练的更多图像分类模型,及对应的预训练模型、finetune操作详情请参照Github:https://github.com/PaddlePaddle/models/blob/develop/PaddleCV/image_classification/README_cn.md
效果展示
图像分类包括通用图像分类、细粒度图像分类等。图1展示了通用图像分类效果,即模型可以正确识别图像上的主要物体。

图1. 通用图像分类展示
图2展示了细粒度图像分类-花卉识别的效果,要求模型可以正确识别花的类别。

图2. 细粒度图像分类展示
一个好的模型既要对不同类别识别正确,同时也应该能够对不同视角、光照、背景、变形或部分遮挡的图像正确识别(这里我们统一称作图像扰动)。图3展示了一些图像的扰动,较好的模型会像聪明的人类一样能够正确识别。

图3. 扰动图片展示[7]
模型概览
CNN:传统CNN包含卷积层、全连接层等组件,并采用softmax多类别分类器和多类交叉熵损失函数,一个典型的卷积神经网络如图4所示,我们先介绍用来构造CNN的常见组件。
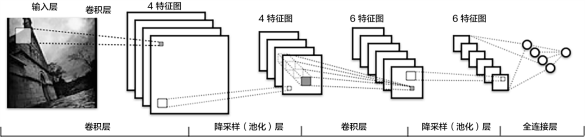
图4. CNN网络示例[5]
• 卷积层(convolution layer): 执行卷积操作提取底层到高层的特征,发掘出图片局部关联性质和空间不变性质。
• 池化层(pooling layer): 执行降采样操作。通过取卷积输出特征图中局部区块的最大值(max-pooling)或者均值(avg-pooling)。降采样也是图像处理中常见的一种操作,可以过滤掉一些不重要的高频信息。
• 全连接层(fully-connected layer,或者fc layer): 输入层到隐藏层的神经元是全部连接的。
• 非线性变化: 卷积层、全连接层后面一般都会接非线性变化函数,例如Sigmoid、Tanh、ReLu等来增强网络的表达能力,在CNN里最常使用的为ReLu激活函数。
• Dropout [1] : 在模型训练阶段随机让一些隐层节点权重不工作,提高网络的泛化能力,一定程度上防止过拟合。
接下来我们主要介绍VGG,ResNet网络结构。
VGG:牛津大学VGG(Visual Geometry Group)组在2014年ILSVRC提出的模型被称作VGG模型 [2] 。该模型相比以往模型进一步加宽和加深了网络结构,它的核心是五组卷积操作,每两组之间做Max-Pooling空间降维。同一组内采用多次连续的3X3卷积,卷积核的数目由较浅组的64增多到最深组的512,同一组内的卷积核数目是一样的。卷积之后接两层全连接层,之后是分类层。由于每组内卷积层的不同,有11、13、16、19层这几种模型,下图展示一个16层的网络结构。VGG模型结构相对简洁,提出之后也有很多文章基于此模型进行研究,如在ImageNet上首次公开超过人眼识别的模型[4]就是借鉴VGG模型的结构。
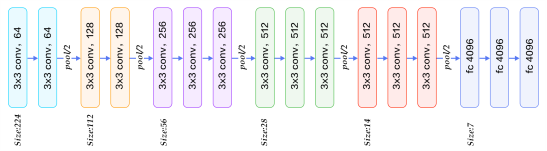
图5. 基于ImageNet的VGG16模型
ResNet:ResNet(Residual Network) [3] 是2015年ImageNet图像分类、图像物体定位和图像物体检测比赛的冠军。针对随着网络训练加深导致准确度下降的问题,ResNet提出了残差学习方法来减轻训练深层网络的困难。在已有设计思路(BN, 小卷积核,全卷积网络)的基础上,引入了残差模块。每个残差模块包含两条路径,其中一条路径是输入特征的直连通路,另一条路径对该特征做两到三次卷积操作得到该特征的残差,最后再将两条路径上的特征相加。
残差模块如图7所示,左边是基本模块连接方式,由两个输出通道数相同的3×3卷积组成。右边是瓶颈模块(Bottleneck)连接方式,之所以称为瓶颈,是因为上面的1×1卷积用来降维(图示例即256->64),下面的1×1卷积用来升维(图示例即64->256),这样中间3×3卷积的输入和输出通道数都较小(图示例即64->64)。
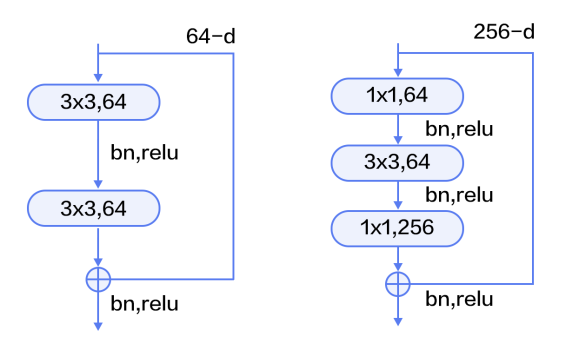
图7. 残差模块
数据准备
由于ImageNet数据集较大,下载和训练较慢,为了方便大家学习,我们使用CIFAR10数据集。CIFAR10数据集包含60,000张32×32的彩色图片,10个类别,每个类包含6,000张。其中50,000张图片作为训练集,10000张作为测试集。图11从每个类别中随机抽取了10张图片,展示了所有的类别。

图11. CIFAR10数据集[6]
Paddle API提供了自动加载cifar数据集模块 paddle.dataset.cifar。
通过输入python train.py,就可以开始训练模型了,以下小节将详细介绍train.py的相关内容。
模型结构
Paddle 初始化
让我们从导入 Paddle Fluid API 和辅助模块开始。

本教程中我们提供了VGG和ResNet两个模型的配置。
VGG
首先介绍VGG模型结构,由于CIFAR10图片大小和数量相比ImageNet数据小很多,因此这里的模型针对CIFAR10数据做了一定的适配。卷积部分引入了BN和Dropout操作。 VGG核心模块的输入是数据层,vgg_bn_drop 定义了16层VGG结构,每层卷积后面引入BN层和Dropout层,详细的定义如下:

首先定义了一组卷积网络,即conv_block。卷积核大小为3×3,池化窗口大小为2×2,窗口滑动大小为2,groups决定每组VGG模块是几次连续的卷积操作,dropouts指定Dropout操作的概率。所使用的img_conv_group是在paddle.fluit.net中预定义的模块,由若干组 Conv->BN->ReLu->Dropout 和 一组 Pooling 组成。
五组卷积操作,即 5个conv_block。 第一、二组采用两次连续的卷积操作。第三、四、五组采用三次连续的卷积操作。每组最后一个卷积后面Dropout概率为0,即不使用Dropout操作。
最后接两层512维的全连接。
在这里,VGG网络首先提取高层特征,随后在全连接层中将其映射到和类别维度大小一致的向量上,最后通过Softmax方法计算图片划为每个类别的概率。
ResNet
ResNet模型的第1、3、4步和VGG模型相同,这里不再介绍。主要介绍第2步即CIFAR10数据集上ResNet核心模块。
先介绍resnet_cifar10中的一些基本函数,再介绍网络连接过程。
• conv_bn_layer : 带BN的卷积层。
• shortcut : 残差模块的"直连"路径,"直连"实际分两种形式:残差模块输入和输出特征通道数不等时,采用1×1卷积的升维操作;残差模块输入和输出通道相等时,采用直连操作。
• basicblock : 一个基础残差模块,即图9左边所示,由两组3×3卷积组成的路径和一条"直连"路径组成。
• layer_warp : 一组残差模块,由若干个残差模块堆积而成。每组中第一个残差模块滑动窗口大小与其他可以不同,以用来减少特征图在垂直和水平方向的大小。

resnet_cifar10 的连接结构主要有以下几个过程。
底层输入连接一层 conv_bn_layer,即带BN的卷积层。
然后连接3组残差模块即下面配置3组 layer_warp ,每组采用图 10 左边残差模块组成。
最后对网络做均值池化并返回该层。
注意:除第一层卷积层和最后一层全连接层之外,要求三组 layer_warp 总的含参层数能够被6整除,即 resnet_cifar10 的 depth 要满足

Infererence配置
网络输入定义为 data_layer (数据层),在图像分类中即为图像像素信息。CIFRAR10是RGB 3通道32×32大小的彩色图,因此输入数据大小为3072(3x32x32)。

Train 配置
然后我们需要设置训练程序 train_network。它首先从推理程序中进行预测。 在训练期间,它将从预测中计算 avg_cost。 在有监督训练中需要输入图像对应的类别信息,同样通过fluid.layers.data来定义。训练中采用多类交叉熵作为损失函数,并作为网络的输出,预测阶段定义网络的输出为分类器得到的概率信息。
注意: 训练程序应该返回一个数组,第一个返回参数必须是 avg_cost。训练器使用它来计算梯度。

Optimizer 配置
在下面的 Adam optimizer,learning_rate 是学习率,与网络的训练收敛速度有关系。
def optimizer_program():
return fluid.optimizer.Adam(learning_rate=0.001)
训练模型
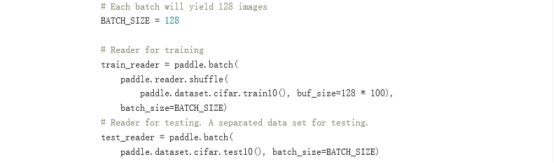
Data Feeders 配置
cifar.train10() 每次产生一条样本,在完成shuffle和batch之后,作为训练的输入。
Trainer 程序的实现
我们需要为训练过程制定一个main_program, 同样的,还需要为测试程序配置一个test_program。定义训练的 place ,并使用先前定义的优化器。

训练主循环以及过程输出
在接下来的主训练循环中,我们将通过输出来来观察训练过程,或进行测试等。

训练
通过trainer_loop函数训练, 这里我们只进行了2个Epoch, 一般我们在实际应用上会执行上百个以上Epoch
注意: CPU,每个 Epoch 将花费大约15~20分钟。这部分可能需要一段时间。请随意修改代码,在GPU上运行测试,以提高训练速度。
train_loop()
一轮训练log示例如下所示,经过1个pass, 训练集上平均 Accuracy 为0.59 ,测试集上平均 Accuracy 为0.6 。

图13是训练的分类错误率曲线图,运行到第200个pass后基本收敛,最终得到测试集上分类错误率为8.54%。
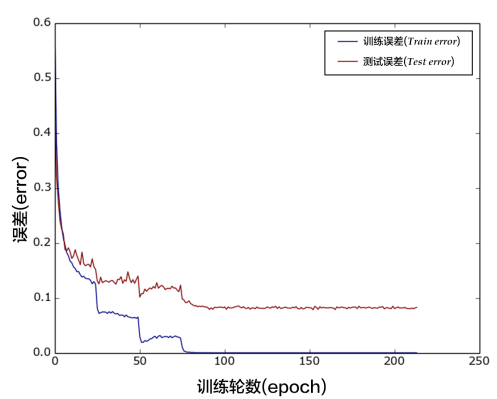
图13. CIFAR10数据集上VGG模型的分类错误率
应用模型
可以使用训练好的模型对图片进行分类,下面程序展示了如何加载已经训练好的网络和参数进行推断。
生成预测输入数据
dog.png 是一张小狗的图片. 我们将它转换成 numpy 数组以满足feeder的格式.
Inferencer 配置和预测
与训练过程类似,inferencer需要构建相应的过程。我们从params_dirname 加载网络和经过训练的参数。 我们可以简单地插入前面定义的推理程序。 现在我们准备做预测。


总结
传统图像分类方法由多个阶段构成,框架较为复杂,而端到端的CNN模型结构可一步到位,而且大幅度提升了分类准确率。本文我们首先介绍VGG、GoogleNet、ResNet三个经典的模型;然后基于CIFAR10数据集,介绍如何使用PaddlePaddle配置和训练CNN模型,尤其是VGG和ResNet模型;最后介绍如何使用PaddlePaddle的API接口对图片进行预测和特征提取。对于其他数据集比如ImageNet,配置和训练流程是同样的,请参照Github https://github.com/PaddlePaddle/models/blob/develop/PaddleCV/image_classification/README_cn.md。
参考文献
[1] G.E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R.R. Salakhutdinov. Improving neural networks by preventing co-adaptation of feature detectors. arXiv preprint arXiv:1207.0580, 2012.
[2] K. Chatfield, K. Simonyan, A. Vedaldi, A. Zisserman. Return of the Devil in the Details: Delving Deep into Convolutional Nets. BMVC, 2014。
[3] K. He, X. Zhang, S. Ren, J. Sun. Deep Residual Learning for Image Recognition. CVPR 2016.
[4] He, K., Zhang, X., Ren, S., and Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. ArXiv e-prints, February 2015.
[5] http://deeplearning.net/tutorial/lenet.html
[6] https://www.cs.toronto.edu/~kriz/cifar.html
[7] http://cs231n.github.io/classification/
来源:PY学习网:原文地址:https://www.py.cn/article.html
