如何保存python程序所生产的数据?


保存python程序生产数据的方法:
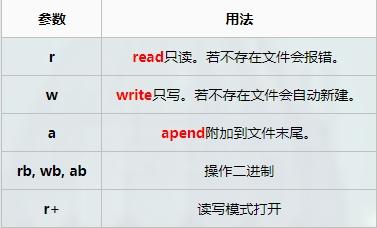
open函数保存
使用with open()新建对象
写入数据(这里使用的是爬取豆瓣读书中一本书的豆瓣短评作为例子)
import requests
from lxml import etree
#发送Request请求
url = 'https://book.douban.com/subject/1054917/comments/'
head = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.94 Safari/537.36'}
#解析HTML
r = requests.get(url, headers=head)
s = etree.HTML(r.text)
comments = s.xpath('//div[@class="comment"]/p/text()')
#print(str(comments))#在写代码的时候可以将读取的内容打印一下
#保存数据open函数
with open('D:/PythonWorkSpace/TestData/pinglun.txt','w',encoding='utf-8') as f:#使用with open()新建对象f
for i in comments:
print(i)
f.write(i+'
')#写入数据,文件保存在上面指定的目录,加
为了换行更方便阅读
这里指的注意的是: open函数的打开模式
pandas包保存
使用pandas保存数据到CSV和Excel:
#导入包import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(10,4))#创建随机值
#print(df.head(2))#查看数据框的头部数据,默认不写为前5行,小于5行时全部显示;也可以自定义查看几行
print(df.tail())##查看数据框的尾部数据,默认不写为倒数5行,小于5行时全部显示;也可以自定义查看倒数几行
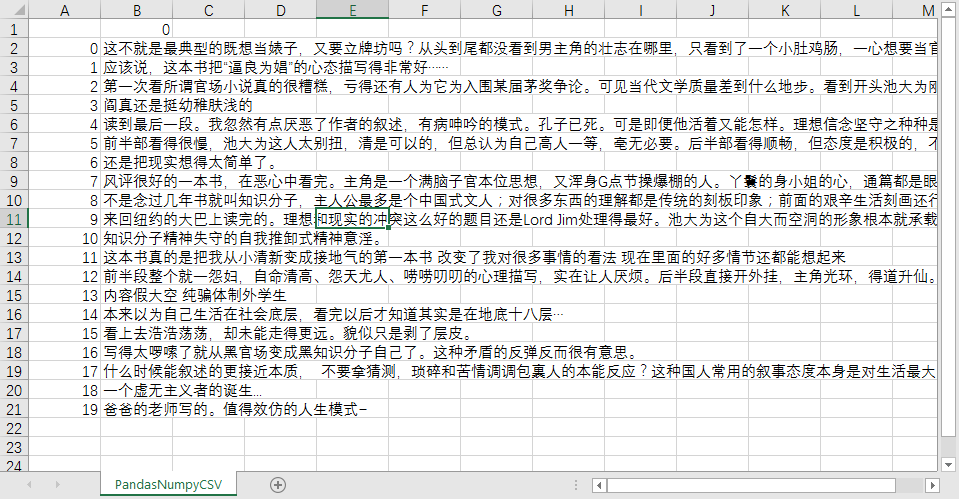
df.to_csv('D:/PythonWorkSpace/TestData/PandasNumpy.csv')#存储到CSV中
#df.to_excel('D:/PythonWorkSpace/TestData/PandasNumpy.xlsx')#存储到Excel中(需要提前导入库 pip install openpyxl)
实例中保存豆瓣读书的短评代码如下:
import requests
from lxml import etree
#发送Request请求
url = 'https://book.douban.com/subject/1054917/comments/'
head = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.94 Safari/537.36'}
#解析HTML
r = requests.get(url, headers=head)
s = etree.HTML(r.text)
comments = s.xpath('//div[@class="comment"]/p/text()')
#print(str(comments))#在写代码的时候可以将读取的内容打印一下
'''
#保存数据open函数
with open('D:/PythonWorkSpace/TestData/pinglun.txt','w',encoding='utf-8') as f:#使用with open()新建对象f
for i in comments:
print(i)
f.write(i+'
')#写入数据,文件保存在上面指定的目录,加
为了换行更方便阅读
'''
#保存数据pandas函数 到CSV 和Excel
import pandas as pd
df = pd.DataFrame(comments)
#print(df.head())#head()默认为前5行
df.to_csv('D:/PythonWorkSpace/TestData/PandasNumpyCSV.csv')
#df.to_excel('D:/PythonWorkSpace/TestData/PandasNumpyEx.xlsx')
更多Python知识请关注云海天Python教程栏目。
来源:PY学习网:原文地址:https://www.py.cn/article.html
