Zabbix使用python导出性能数据execl表-从零到无

![Zabbix使用python导出性能数据execl表-从零到无[Python基础]](https://www.zixueka.com/wp-content/uploads/2023/10/1696832125-ecbdfa9d7ac8081.jpg)
– – 时间:2020年12月5日
– – 作者:飞翔的小胖猪
前言
使用zabbix作为基础环境的监控系统时,除了通过web页面和自定义告警通知手段获取当前主机服务器运行状态,趋势数据也是很重要的,透过趋势数据可以了解服务器在某个时间范围内关键指标情况,是否长期高负载运行或长期空闲状态。在虚拟化或云平台环境下趋势数据可作为服务器资源压缩回收扩容参考数据,文章通过使用python脚本连接zabbix后端的mysql数据库,查询整理服务器运行性能数据生成execl文件。
环境
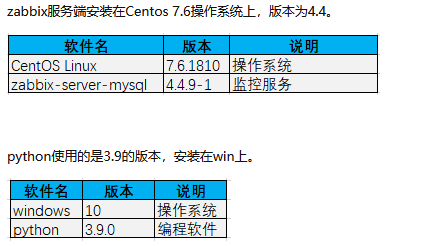
脚本说明
该脚本只试用于linux操作系统中。具体工作思路及流程如下:
1.获取到主机所在监控模板的id号(步骤可以参考我https://www.cnblogs.com/Pigs-Will-Fly/p/13954583.html这篇文章中)文章中不涉及id号查询方法。
2.获取指定监控模板下所包含的所有主机id号。
3.使用主机id号和主机名形成字典,以便后期整合数据用。
4.使用主机id号结合item指标查询出每个机器每个指标唯一的item号并生成字典。
5.使用item号查询出具体的数据。
6.整合之前的所有数据,以主机名为key生成字典。
7.写入数据到execl表中。
PS:脚本再查询主机ID时使用的是监控模板ID,而不是使用分组ID号。
脚本文件


#!/usr/bin/python3
# @Date: 2020/10/29 21:16
# @Author: lvan
# @email: yinwanit@qq.com
# -*- coding: utf-8 -*-
import pymysql
import time,datetime
import math
from decimal import *
import xlsxwriter
import xlrd
#打开数据库连接函数
def open_mysql_db(zdbhost,zdbuser,zdbpass,zdbport,zdbname):
print(".开始连接数据库...")
conn = pymysql.connect(host=zdbhost, user=zdbuser, passwd=zdbpass, port=zdbport, db=zdbname, charset="utf8")
cursor = conn.cursor()
print("--完成:连接数据库,状态OK!")
return cursor
# 指定模板ID,获取模板中包含的主机id号
def get_temp_id(db_cursor,groupid):
print("开始获取模板中包含主机ID号...")
sql = """select hostid from hosts_templates where templateid = "{0}"""".format(groupid)
db_cursor.execute(sql)
hostlist = [i for i in list("%s" %j for j in db_cursor.fetchall())]
print("--完成:主机ID号获取,状态OK!")
return hostlist
#结果为["10357", "10362", "10363", "10365"]
#通过hostid获取到主机的host名,定义一个保存主机IP地址和ID号的字典
def get_host_for_hostid(hostlist,db_cursor):
print(".开始生成主机id号和主机名对应关系...")
Ipinfo_dict = dict()
for hostid in hostlist: #每次从hostlist中取一个hostid出来,然后获取到指定的host通过字典的方式加入到IpinfoList中去。
#print("hostid:",hostid)
sql = """select host from hosts where status = 0 and hostid = {0}""".format(hostid)
ret = db_cursor.execute(sql)
if ret:
for i in db_cursor.fetchone():
Ipinfo_dict[hostid] = i
print("--完成:主机id与主机名关系生成,状态OK!")
return Ipinfo_dict
#结果{"10357": "192.168.111.131", "10362": "192.168.111.11", "10363": "192.168.111.12", "10365": "192.168.111.124"}
#获取指定id号的主机的item资源号,在trends表和trends_uint中
def get_itemid(keys,hostlist,db_cursor):
print(".开始获取ITEM号...")
Item_key_dict = dict()
Hostid_Item_dict = dict()
Item_name_list = list()
item_name_dir = dict()
for bb in ["trends","trends_uint"]:
Iteminfo_list = list()
for j in keys[bb]:
for k in hostlist:
#print("this is %s,this er %s",j,k)
sql = """select itemid from items where hostid = {0} and key_ = "{1}" """.format(k,j)
if db_cursor.execute(sql):
itemid = "".join("%s" %i for i in list(db_cursor.fetchone()))
Hostid_Item_dict[itemid] = k
Iteminfo_list.append(itemid)
item_name_dir[itemid] = j
else:
itemid = None
Item_key_dict[bb] =Iteminfo_list
print("--完成:ITEM号获取,状态OK!")
return Item_key_dict,Hostid_Item_dict,item_name_dir
#结果:输出的item_dict: {"trends": ["33875", "34302", "34367", "34497", "33882", "34309", "34374", "34504", "33878", "34305", "34370", "34500"], "trends_uint": ["33903", "34330", "34395", "34525", "33905", "34332", "34397", "34527"]}
#输出的item_host_dict: {"33875": "10357", "34302": "10362", "34367": "10363", "34497": "10365", "33882": "10357", "34309": "10362", "34374": "10363", "34504": "10365", "33878": "10357", "34305": "10362", "34370": "10363", "34500": "10365", "33903": "10357", "34330": "10362", "34395": "10363", "34525": "10365", "33905": "10357", "34332": "10362", "34397": "10363", "34527": "10365"}
#整合数据,之前得主机id,ip地址,item值名,item名整合在一起。
def format_all_data(host_id_list,id_ip_dir,Item_key_dict,Hostid_Item_dict,Item_name_dir,item_values_dir_list):
print(".开始整合数据...")
resut_info = dict()
for i in list(id_ip_dir.values()):
temp_values_dir = dict()
#print(i) #通过ip来确定,如果i和item_name_dir里面数据查出来的一致则记录数据到字典,当数据记录完毕后添加到最终字典中,并开启下一次循环,清空temp_values_dir字典
for j in list(Item_name_dir.keys()):
#print(j)
temp_ip = id_ip_dir[Hostid_Item_dict[j]]
temp_item_name = Item_name_dir[j]
temp_value = item_values_dir_list[j]
if temp_ip == i:
temp_values_dir[temp_item_name] = temp_value
resut_info[i] = temp_values_dir
print("--完成:整合数据完成,状态OK!")
return resut_info
#最终想得到的数据格式为:{ip:{{cpu:[最小,中间,最大]}},{内存:[最小,中间,最大]}}
#查询指定表中的指定指标的数据,反馈itemid和及值名字类型大小。
def get_items_valuesb(item_dict_r,db_cursor,start_time,end_time):
print(".开始查询数据...")
resultlist = {}
for table_name in ["trends","trends_uint"]:
for itemid in item_dict_r[table_name]:
sql = """select min(value_min),avg(value_avg),max(value_max) from {2} where itemid = {3} and clock >= {4} and clock <= {5}""".format(type, type, table_name, itemid, start_time, end_time)
db_cursor.execute(sql)
result = db_cursor.fetchall()
for aa,bb,cc in result:
value_list = list()
value_list.append(aa)
value_list.append(bb)
value_list.append(cc)
resultlist[itemid] = value_list
print("完成:数据查询完成,状态OK!")
return resultlist
#生成格式为{itemid:[min,avg,max]}
#写入数据到execl中
def writeexecl(format_data_r_dict,file_dir):
# 创建文件
print("开始生成execl文件...")
workbook = xlsxwriter.Workbook(file_dir)
# 创建工作薄
worksheet = workbook.add_worksheet()
print(" 创建工作薄");
# 写入标题(第一行)
i = 0
for value in ["ip地址", "CPU负载谷值", "CPU负载均值", "CPU负载峰值","根目录使用GB","根目录使用百分比GB","更目录总量GB","内存可用谷值GB","内存可用均值GB","内存可用峰值GB","内存总大小GB","CPU空闲谷","CPU空闲均","CPU空闲峰","CPU个数"]:
worksheet.write(0, i, value)
i = i + 1
# 写入内容:
j = 1
for ip_host in list(format_data_r_dict.keys()):
#这为一行
value= format_data_r_dict[ip_host]
worksheet.write(j, 0, ip_host)
worksheet.write(j, 1, value["system.cpu.load[all,avg15]"][0])
worksheet.write(j, 2, value["system.cpu.load[all,avg15]"][1])
worksheet.write(j, 3, value["system.cpu.load[all,avg15]"][2])
worksheet.write(j, 4, "{}GB".format(math.ceil(value["vfs.fs.size[/,used]"][0] / 1024 / 1024 / 1024)))
worksheet.write(j, 5, "{:.2f}%".format(value["vfs.fs.size[/,pused]"][0]))
worksheet.write(j, 6, "{}GB".format(math.ceil(value["vfs.fs.size[/,total]"][0] / 1024 / 1024 / 1024)))
worksheet.write(j, 7, "{}GB".format(math.ceil(value["vm.memory.size[available]"][0] / 1024 / 1024 / 1024)))
worksheet.write(j, 8, "{}GB".format(math.ceil(value["vm.memory.size[available]"][1] / 1024 / 1024 / 1024)))
worksheet.write(j, 9, "{}GB".format(math.ceil(value["vm.memory.size[available]"][2] / 1024 / 1024 / 1024)))
worksheet.write(j, 10, "{}GB".format(math.ceil(value["vm.memory.size[total]"][0] / 1024 / 1024 / 1024)))
worksheet.write(j, 11, "{:.2f}%".format(value["system.cpu.util[,idle]"][0]))
worksheet.write(j, 12, "{:.2f}%".format(value["system.cpu.util[,idle]"][1]))
worksheet.write(j, 13, "{:.2f}%".format(value["system.cpu.util[,idle]"][2]))
worksheet.write(j, 14, value["system.cpu.num"][0])
j = j + 1
workbook.close()
print(" 完成:execl文件生成,状态OK!路径为: ",file_dir)
if __name__ == "__main__":
# zabbix数据库信息:
zdbhost1 = "192.168.111.124"
zdbuser1 = "zabbix"
zdbpass1 = "password"
zdbport1 = 3306
zdbname1 = "zabbix"
#监控模板id号
groupid = 10001
#定义时间范围,此处填写的时时间戳。可使用https://tool.lu/timestamp/网页工具自行转换,所以失效了自行百度。
start_time = 0
end_time = 999999999999
#设置execl保存文件名
save_file_dir = "test2222.xls"
# 需要查询的key列表,trends_unit字典里面的是trends_uint里的值;trends字典里面的是trends的值
keys = {
"trends_uint": [
"vfs.fs.size[/,used]",
"vm.memory.size[available]",
"vm.memory.size[total]",
"system.cpu.num",
"vfs.fs.size[/,total]",
],
"trends": [
"system.cpu.load[all,avg15]",
"system.cpu.util[,idle]",
"system.swap.size[,pfree]",
"vfs.fs.size[/,pused]",
],
}
db_r = open_mysql_db(zdbhost1,zdbuser1,zdbpass1,zdbport1,zdbname1)
hostid_r = get_temp_id(db_r,groupid)
ee = get_host_for_hostid(hostid_r,db_r)
a,b,c=get_itemid(keys,hostid_r,db_r)
ff = get_items_valuesb(a, db_r,start_time,end_time)
ll = format_all_data(hostid_r,ee,a,b,c,ff)
writeexecl(ll,save_file_dir)
