Python 中的新式类和经典类的区别?

![Python 中的新式类和经典类的区别?[Python常见问题]](https://www.zixueka.com/wp-content/uploads/2023/10/1696934269-98ff7a5050bfcc6.jpg)
1. 版本支持 / 写法差异
在Python 2.x 中
如果你至今使用的还是 Python 2.x,那么你需要了解一下,在Python 2.x中存在着两种类:经典类和新式类。
什么是经典类?
# 不继承自object
class Ming:
pass
什么是新式类?
# 显示继承object
class Ming(object):
pass
在Python 3.x 中
如果你已经摒弃了Python 2.x,而已经完全投入了Python 3.x的怀抱,那你可能不需要关心,因为在Python3.x中所有的类都是新式类(所有类都(显示/隐式)继承自object)。
有如下三种写法,它们是等价的。
class Ming:
pass
class Ming():
pass
class Ming(object):
pass
2. 使用方法 / 独特属性
经典类无法使用super()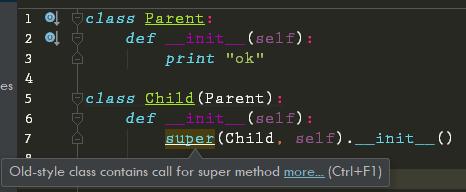
经典类的类型是 classobj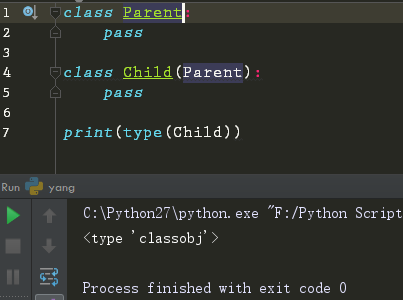
新式类的类型是 type,保持class与type的统一。
新式类增加了__slots__内置属性, 可以把实例属性的种类锁定到__slots__规定的范围之中.
新式类增加了__getattribute__方法,在获取属性时可以进入此方法。而经典类不会。
# 经典类:py2.7
class Kls01:
def __getattribute__(self, *args, **kwargs):
print("MING - 01")
# 新式类
class Kls02(object):
def __getattribute__(self, *args, **kwargs):
print("MING - 02")
kls02 = Kls02()
kls02.name
kls01 = Kls01()
kls01.name
输出如下
MING - 02
Traceback (most recent call last):
File "F:/Python Script/Tornado/yang.py", line 13, in <module>
kls01.name
AttributeError: Kls01 instance has no attribute "name"
3. MRO 查找算法的演变
经典类中
经典类,MRO采用的是深度优先算法。
为了验证,这个继承顺序。在 Python2.x 中可以借助自带模块 inspect 来检验。
import inspect
class A:pass
class B(A):pass
class C(A):pass
class D(B, C):pass
print inspect.getmro(D)
输出如下,可以看出,继承顺序是 D -> B -> A -> C
(<class __main__.D at 0x0000000005836A08>,
<class __main__.B at 0x0000000005836768>,
<class __main__.A at 0x00000000058368E8>,
<class __main__.C at 0x0000000005836AC8>)
非常好理解,但是在菱形继承时,方法的调用会出现问题。
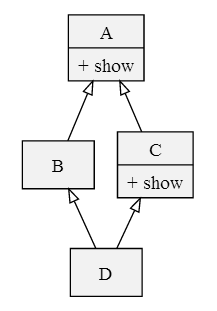
假设 d 是 D 的一个实例,那么执行 d.show()是调用 A.show() 呢 还是调用 C.show()呢?
在经典类中,由于是深度优先,所以是会选择 A.show()。但是很明显,C.show() 是 A.show() 的更具体化版本(显示了更多的信息),但我们的x.show() 没有调用它,而是调用了 A.show(),这显然是不合理的。所以这才有了后来的一步一步优化。
新式类中
为解决经典类 MRO 所存在的问题,Python 2.2 针对新式类提出了一种新的 MRO 计算方式:在定义类时就计算出该类的 MRO 并将其作为类的属性。
Python 2.2 的新式类 MRO 计算方式和经典类 MRO 的计算方式非常相似:它仍然采用从左至右的深度优先遍历,但是如果遍历中出现重复的类,只保留最后一个。重新考虑上面「菱形继承」的例子:
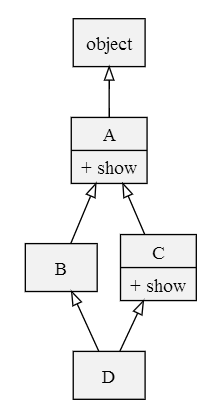
同样地,我们也来验证一下。另说明,在新式类中,除用inspect外,可以直接通过__mro__属性获取类的 MRO。
import inspect
class A(object):pass
class B(A):pass
class C(A):pass
class D(B, C):pass
# 或者通过 D.__mro__ 查找
print inspect.getmro(D)
输出如下,可以看出,继承顺序变成了 D -> B -> C -> A
(<class "__main__.D">,
<class "__main__.B">,
<class "__main__.C">,
<class "__main__.A">,
<type "object">)
这下,菱形问题解决了。
再来看一个复杂一点的例子。
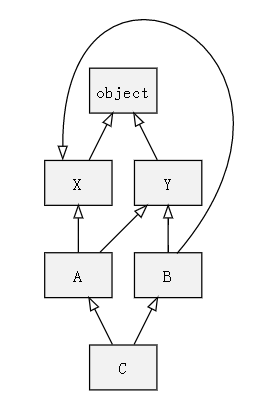
如果只依靠上面的算法,我们来一起算下,其继承关系是怎样的。
- 首先进行深度遍历:[C, A, X, object, Y, object, B, Y, object, X, object];
- 然后,只保留重复元素的最后一个:[C, A, B, Y, X, object]。
同样来验证一下。
class X(object): pass
class Y(object): pass
class A(X, Y): pass
class B(Y, X): pass
class C(A, B): pass
print(C.__mro__)
输出报错,它告诉我们 X,Y 具有二义性的继承关系(这是从Python 2.3后的 C3算法 才有的)。
Traceback (most recent call last):
File "F:/Python Script/Tornado/yang.py", line 7, in <module>
class C(A, B): pass
TypeError: Error when calling the metaclass bases
Cannot create a consistent method resolution
order (MRO) for bases X, Y
具体为什么会这样,我们来看一下。
对于 A 来说,其搜索顺序为[A, X, Y, object];
对于 B,其搜索顺序为 [B, Y, X, object];
对于 C,其搜索顺序为[C, A, B, X, Y, object]。
我们会发现,B 和 C 中 X、Y 的搜索顺序是相反的!也就是说,当 B 被继承时,它本身的行为竟然也发生了改变,这很容易导致不易察觉的错误。此外,即使把 C 搜索顺序中 X 和 Y 互换仍然不能解决问题,这时候它又会和 A 中的搜索顺序相矛盾。
对于复杂一点的继承关系,我们在写代码的时候最好做到心中有数。接下来,就教教你,如何在层层复杂的继承关系中,计算出继承顺序。
例如下面这张图。
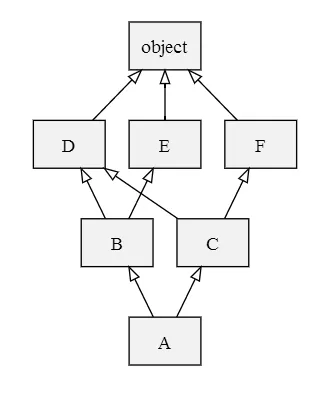
计算过程,会采用一种 merge算法。它的基本思想如下:
- 检查第一个列表的头元素(如 L[B1] 的头),记作 H。
- 若 H 未出现在其它列表的尾部,则将其输出,并将其从所有列表中删除,然后回到步骤1;否则,取出下一个列表的头部记作 H,继续该步骤。
- 重复上述步骤,直至列表为空或者不能再找出可以输出的元素。如果是前一种情况,则算法结束;如果是后一种情况,说明无法构建继承关系,Python 会抛出异常。
你可以在草稿纸上,参照上面的merge算法,写出如下过程
L[object] = [object]
L[D] = [D, object]
L[E] = [E, object]
L[F] = [F, object]
L[B] = [B, D, E, object]
L[C] = [C, D, F, object]
L[A] = [A] + merge(L[B], L[C], [B], [C])
= [A] + merge([B, D, E, object], [C, D, F, object], [B], [C])
= [A, B] + merge([D, E, object], [C, D, F, object], [C])
= [A, B, C] + merge([D, E, object], [D, F, object])
= [A, B, C, D] + merge([E, object], [F, object])
= [A, B, C, D, E] + merge([object], [F, object])
= [A, B, C, D, E, F] + merge([object], [object])
= [A, B, C, D, E, F, object]
当然,可以用代码验证类的 MRO,上面的例子可以写作:
class D(object): pass
class E(object): pass
class F(object): pass
class B(D, E): pass
class C(D, F): pass
class A(B, C): pass
A.__mro__
输出如下
(<class "__main__.A">,
<class "__main__.B">,
<class "__main__.C">,
<class "__main__.
附录:参考文章
- https://www.python.org/download/releases/2.3/mro/
- https://www.cnblogs.com/whatisfantasy/p/6046991.html
文末福利
本人原创的 《PyCharm 中文指南》一书前段时间一经发布,就火爆了整个 Python 圈,发布仅一天的时间,下载量就突破了 1000 ,并且在当天就在 Github 上就收获了数百的 star,截至目前,下载量已经破万。
这本书一共将近 200 页,内含大量的图解,制作之精良,值得每个 Python 工程师 人手一份。

为方便你下载,我将这本书上传到 百度网盘上了,你可以自行获取。
链接:https://pan.baidu.com/s/1-NzATHFtaTV1MQzek70iUQ
密码:mft3
