学会这招,小姐姐看你的眼神将不一样

![学会这招,小姐姐看你的眼神将不一样[Python常见问题]](https://www.zixueka.com/wp-content/uploads/2023/10/1696934296-ab1e8f67f844829.jpg)
前言
今天某小丽同学来找我,有个实验需要用到轻松筹的数据进行一个分析。可是没有足够的数据,如何办是好?
乐于助人的我,当然不会置之不理~
(ps.毕竟是小姐姐嘛,拒绝了不好,对叭)
于是乎,我抄起家伙,说干就干。
一、爬虫分析
通过简单的分析,可以发现轻松筹提供了一个接口,可以返回某个项目的相关数据,具体如下: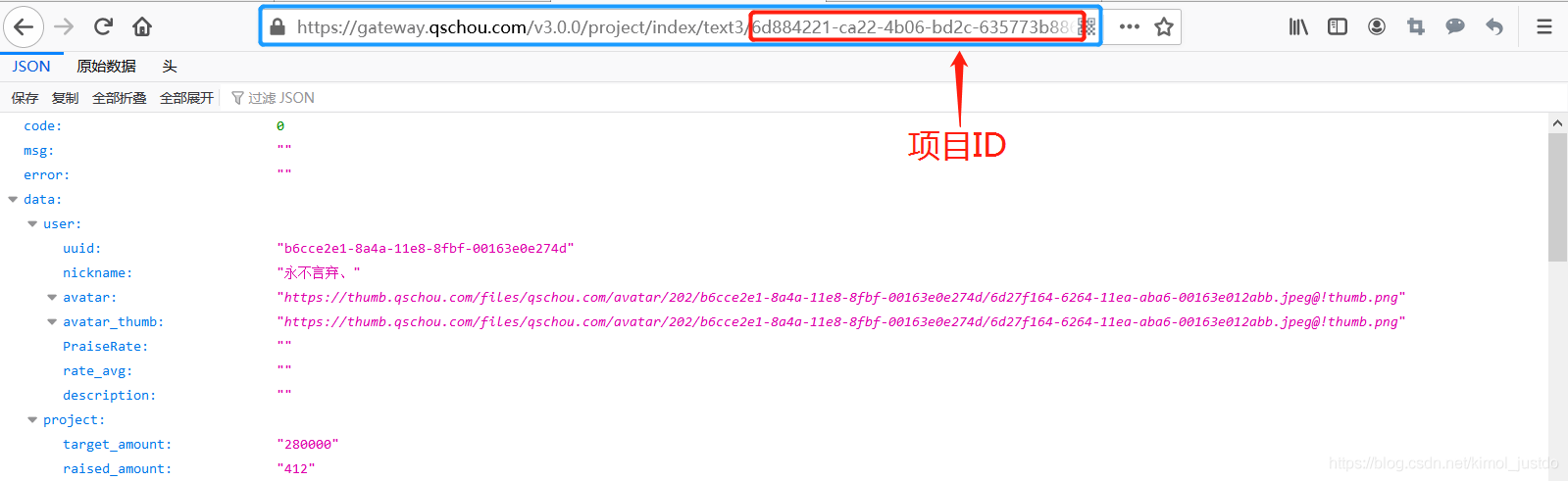
地址如下,xxxxxx表示项目的UUID:
https://gateway.qschou.com/v3.0.0/project/index/text3/xxxxxx
- 1
也就是说,我们只要有UUID,那么就可以通过requests发送请求很容易就能得到数据。这还不简单,我们对UUID进行遍历不就行了嘛?
然而,UUID的长度为32位,要是想遍历的话,等明年去叭…
解决问题(小声说:“获得小姐姐的青睐”)的关键就是想办法找到项目的UUID。
二、爬取项目ID
在官网搜寻了一番,并没有发现哪里有UUID。于是,我们只能另辟蹊径。最后,我决定从百度贴吧入手,搜索相关的帖子,并把帖子中的项目链接中的UUID提取出来。
1.抓取帖子的URL
遍历整个“轻松筹吧”,抓取每个帖子的URL:
url_tieba = "https://tieba.baidu.com/f?kw=轻松筹&ie=utf-8&pn=%d" # 贴吧页面,pn=0,50,100...
p_href = "href="/p/(.*?)""
hrefs = []
for i in range(1): # 爬取的页数
try:
pn = i*50
res = requests.get(url_tieba%pn)
html = res.text
list_herf = re.findall(p_href,html)
for h in list_herf:
hrefs.append("https://tieba.baidu.com/p/"+h)
print("第%d页获取成功"%(i+1))
except:
pass
with open("tiezi_url.txt","w") as f:
for h in hrefs:
f.write(h+"
")
2.提取帖子中的UUID
要获取每个帖子里面的项目UUID,主要有两种方式:
(1)从帖子中的链接中提取
首先定义匹配链接的正则表达式:
p_projuuid = "https://m2.qschou.com.*?projuuid=(.*?)&"
- 1
对帖子进行匹配:
for h in hrefs:
try:
res = requests.get(h)
html = res.text
list_projuuid = re.findall(p_projuuid,html) # 判断帖子里是否有直接的链接
if len(list_projuuid) != 0:
for p in list_projuuid:
if p not in projuuids and len(p) == 36:
projuuids.append(p)
print("%s 提取到projuuid:%s"%(h,p))
else: # 提取帖子中的图片获取二维码
list_img = re.findall(p_img,html)
if len(list_img) == 0:
print("%s 无法提取到projuuid"%h)
else:
for i in list_img:
txt_list = get_ewm(i)
if len(txt_list) != 0:
barcodeData = txt_list[0].data.decode("utf-8")
for p in re.findall("projuuid=(.*)",barcodeData):
if p not in projuuids and len(p) == 36:
projuuids.append(p)
print("%s 提取到projuuid:%s"%(h,p))
except:
pass
(2)从帖子中的二维码中提取
首先,我们得匹配帖子中的所有图片,正则如下:
p_img = "class="BDE_Image" src="(.*?)""
- 1
然后对其中的每张图片,进行二维码读取,如果包含项目连接则将其中的UUID提取出来:
for h in hrefs:
try:
res = requests.get(h)
html = res.text
list_projuuid = re.findall(p_projuuid,html) # 判断帖子里是否有直接的链接
if len(list_projuuid) != 0:
for p in list_projuuid:
if p not in projuuids and len(p) == 36:
projuuids.append(p)
print("%s 提取到projuuid:%s"%(h,p))
else: # 提取帖子中的图片获取二维码
list_img = re.findall(p_img,html)
if len(list_img) == 0:
print("%s 无法提取到projuuid"%h)
else:
for i in list_img:
txt_list = get_ewm(i)
if len(txt_list) != 0:
barcodeData = txt_list[0].data.decode("utf-8")
for p in re.findall("projuuid=(.*)",barcodeData):
if p not in projuuids and len(p) == 36:
projuuids.append(p)
print("%s 提取到projuuid:%s"%(h,p))
except:
pass
其中,读取二维码的函数如下:
def get_ewm(img_adds):
# 读取二维码的内容: img_adds:二维码地址(可以是网址也可是本地地址)
if os.path.isfile(img_adds):
# 从本地加载二维码图片
img = Image.open(img_adds)
else:
# 从网络下载并加载二维码图片
rq_img = requests.get(img_adds).content
img = Image.open(BytesIO(rq_img))
txt_list = pyzbar.decode(img)
#barcodeData = txt_list[0].data.decode("utf-8")
return txt_list
注意:这里需要用到pyzbar库,通过pip安装即可:
pip install pyzbar
- 1
3.完整代码
import re
import os
import requests
from PIL import Image
from io import BytesIO
from pyzbar import pyzbar
def get_ewm(img_adds):
# 读取二维码的内容: img_adds:二维码地址(可以是网址也可是本地地址)
if os.path.isfile(img_adds):
# 从本地加载二维码图片
img = Image.open(img_adds)
else:
# 从网络下载并加载二维码图片
rq_img = requests.get(img_adds).content
img = Image.open(BytesIO(rq_img))
txt_list = pyzbar.decode(img)
#barcodeData = txt_list[0].data.decode("utf-8")
return txt_list
if __name__ == "__main__":
# 获取每个帖子的编号
url_tieba = "https://tieba.baidu.com/f?kw=轻松筹&ie=utf-8&pn=%d" # 贴吧页面,pn=0,50,100...
p_href = "href="/p/(.*?)""
hrefs = []
for i in range(1): # 爬取的页数
try:
pn = i*50
res = requests.get(url_tieba%pn)
html = res.text
list_herf = re.findall(p_href,html)
for h in list_herf:
hrefs.append("https://tieba.baidu.com/p/"+h)
print("第%d页获取成功"%(i+1))
except:
pass
with open("tiezi_url.txt","w") as f:
for h in hrefs:
f.write(h+"
")
# 爬取每个帖子中的轻松筹链接
projuuids = []
p_projuuid = "https://m2.qschou.com.*?projuuid=(.*?)&"
p_img = "class="BDE_Image" src="(.*?)""
for h in hrefs:
try:
res = requests.get(h)
html = res.text
list_projuuid = re.findall(p_projuuid,html) # 判断帖子里是否有直接的链接
if len(list_projuuid) != 0:
for p in list_projuuid:
if p not in projuuids and len(p) == 36:
projuuids.append(p)
print("%s 提取到projuuid:%s"%(h,p))
else: # 提取帖子中的图片获取二维码
list_img = re.findall(p_img,html)
if len(list_img) == 0:
print("%s 无法提取到projuuid"%h)
else:
for i in list_img:
txt_list = get_ewm(i)
if len(txt_list) != 0:
barcodeData = txt_list[0].data.decode("utf-8")
for p in re.findall("projuuid=(.*)",barcodeData):
if p not in projuuids and len(p) == 36:
projuuids.append(p)
