python3爬虫应用–爬取网易云音乐(两种办法)

![python3爬虫应用--爬取网易云音乐(两种办法)[Python基础]](https://www.zixueka.com/wp-content/uploads/2023/10/1696934338-ec47e78b076e4ca.jpg)
一、需求
好久没有碰爬虫了,竟不知道从何入手。偶然看到一篇知乎的评论(https://www.zhihu.com/question/20799742/answer/99491808),一时兴起就也照葫芦画瓢般尝试做一做。本文主要是通过网页的歌名搜索,然后获取到页面上的搜索结果,最后自行选择下载搜索结果中的哪条歌曲。
二、应用
在这个过程中,有很多坑,但还好撑过去了。过程中主要用到的东西有 fiddler抓包查看日志、浏览器JS的分析、python ASE的加密、request包 的简单应用、jsonpath包的运用、python基础的列表、字典、格式化的简单运用。
三、说明
1、本文主要参考引用了以下博文,感谢大神们的思路和过程:
https://www.zhihu.com/question/36081767
https://www.cnblogs.com/nienie/p/8511999.html
https://www.zhihu.com/question/20799742/answer/99491808
https://www.cnblogs.com/mxk123/p/11832247.html(CSS选择器学习)
https://www.cnblogs.com/songzhenhua/p/10260992.html (也是CSS选择器学习)
https://www.cnblogs.com/yuluoxingkong/p/10019246.html (可以借鉴无界面话的浏览器模式)
2、本文仅供娱乐和学习,切勿用于商业用途,如有发现,概不负责!
四、正文
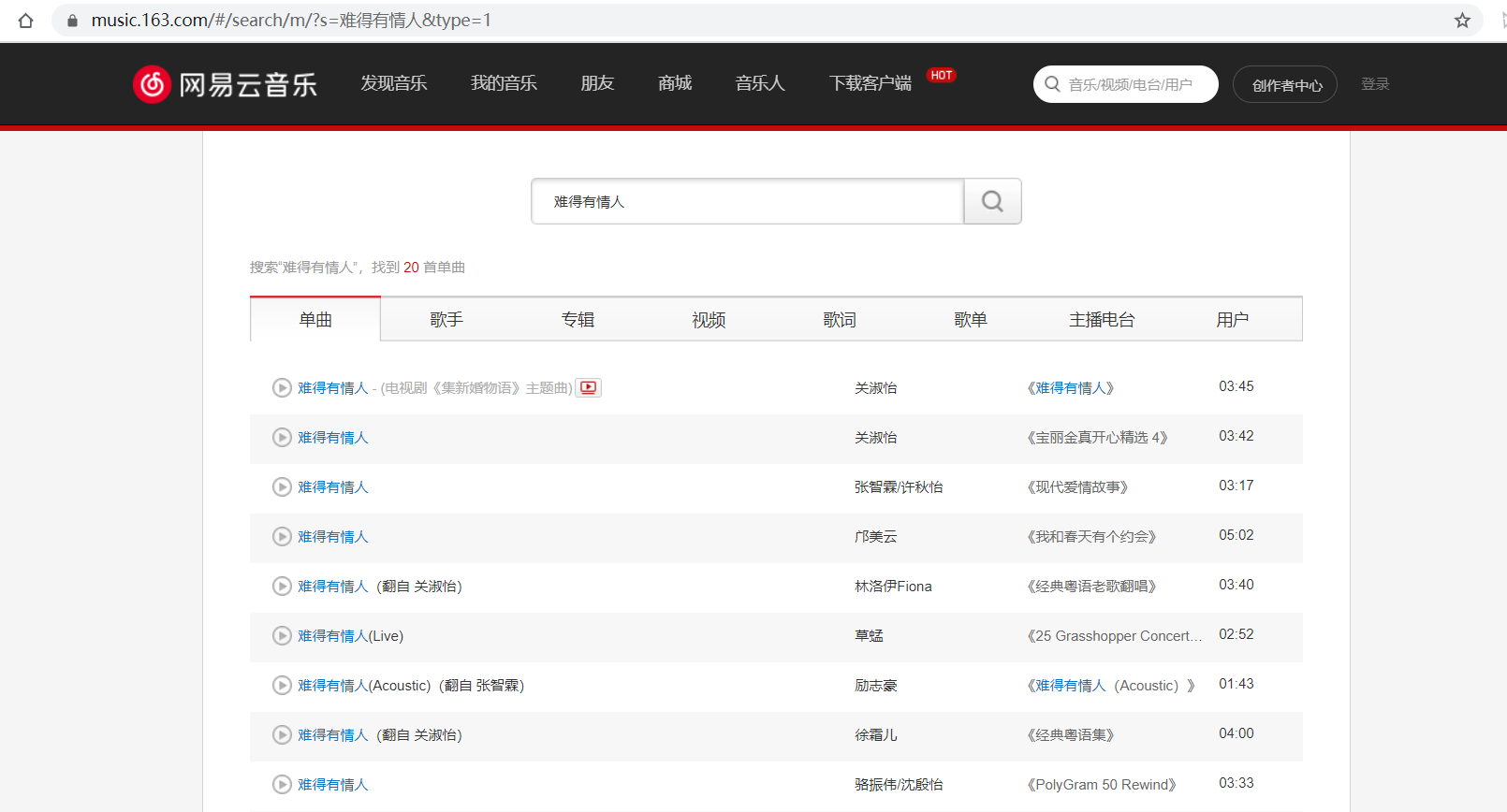
上图就是我们的目标页面,很简单的实现搜索和下载音乐的功能。
根据搜索地址(https://music.163.com/#/search/m/?s=难得有情人&type=1),本文主要的思路有:
思路一
1、使用beautifulsoup 把整个网页load下来,看HTML中是否有歌曲的ID,我们主要是用ID来进行下载,有个歌曲外链的下载地址(http://music.163.com/song/media/outer/url?id=id.mp3
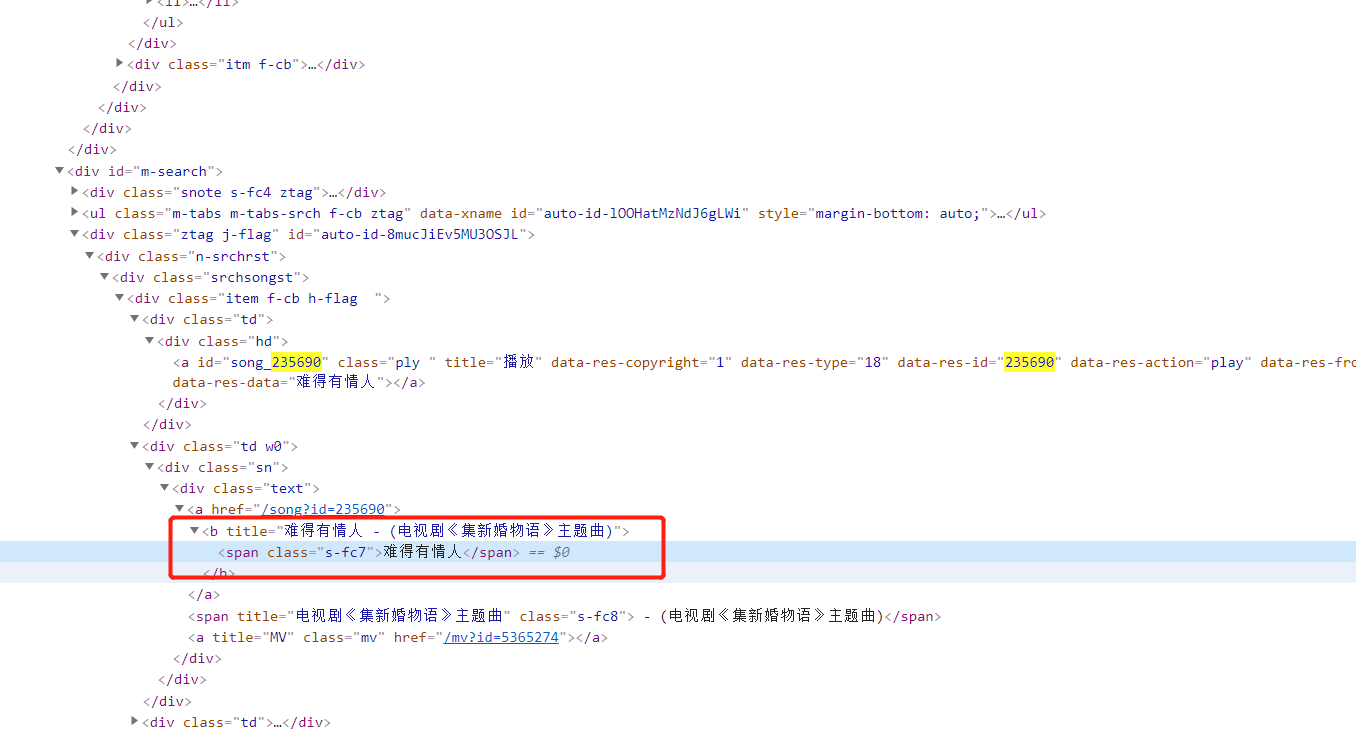
),我也不知道从哪里来的,可以根据ID来下载歌曲。现在看下网页的HTML源码,对着歌名右键——检查,可以看到歌名、歌曲的id、歌手等信息,然后使用beautifulsoup 进行获取就可以了。但是现在关键信息都放在了iframe里面,暂时不知道怎么抓取。本文就先不深入阐述,有时间再研究一下。(补:网上搜了一下可以使用webdriver来实现跨iframe抓取数据,因此也就使用该种方法了,不多说直接放代码,代码比第二种少了一些,不过速度较慢)
————————————补上思路一的代码,效果和思路二是一样的—————————————-
import requests # 用于获取网页内容的模块
from bs4 import BeautifulSoup # 用于解析网页源代码的模块
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
def handle_hmtl(search_name):
chrome_options = Options()
chrome_options.add_argument("--headless")
driver = webdriver.Chrome("chromedriver", chrome_options=chrome_options)
link = "https://music.163.com/#/search/m/?s=" + search_name + "&type=1" # 要搜索的链接
driver.get(link)
iframe_elemnt = driver.find_element_by_id("g_iframe") # 因为直接获取不到iframe的内容,因此使用web_driver
driver.switch_to.frame(iframe_elemnt) # 关键步骤,跳转到iframe里面,就可以获取HTML内容
soup = BeautifulSoup(driver.page_source, "html.parser") # 通过 BeautifulSoup 模块解析网页,具体请参考官方文档。
L = [] # 存储结果的列表
nu = 0
for value in soup.select(
"div[class="srchsongst"] div[class^="item f-cb h-flag"]"): # 获取到关键class:srchsongst下面的所有元素,结果是一个列表,使用的是CSS的方式
D = {"num": "null", "name": "null", "id": "null", "singer": "null", "song_sheet": "null"} # 初始化字典
D["num"] = nu # 用来计算num
D["name"] = value.b.attrs["title"] # 歌名
D["id"] = value.a.attrs["data-res-id"] # 歌曲ID
D["singer"] = "/".join([i.string for i in value.select("a[href^="/artist?i"]")]) # 歌唱者
D["song_sheet"] = value.select("a[class^="s-fc3"]")[0].attrs["title"] # 专辑
L.append(D)
nu += 1
return L
def load_song(num, result):
"""
result 是一个列表
num 是一个str
"""
if isinstance(int(num), int):
num = int(num)
if num >= 0 and num <= len(result):
song_id = result[num]["id"]
song_down_link = "http://music.163.com/song/media/outer/url?id=" + result[num]["id"] + ".mp3" # 根据歌曲的 ID 号拼接出下载的链接。歌曲直链获取的方法参考文前的注释部分。
print("歌曲正在下载...")
response = requests.get(song_down_link, headers=headers).content # 亲测必须要加 headers 信息,不然获取不了。
f = open(result[num]["name"] + ".mp3", "wb") # 以二进制的形式写入文件中
f.write(response)
f.close()
print("下载完成.
")
else:
print("你输入的数字不在歌曲列表范围,请重新输入")
else:
print("请输入正确的歌曲序号")
if __name__ == "__main__":
headers={ # 伪造浏览器头部,不然获取不到网易云音乐的页面源代码。
"User-Agent":"Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.80 Safari/537.36",
"Referer":"http://93.174.95.27",
}
search_name = input("请输入你想要在网易云音乐中搜索的单曲:")
result = handle_hmtl(search_name)
print("%3s %-35s %-20s %-20s " % ("序号", " 歌名", "歌手", "专辑"))
for i in range(len(result)):
print("%3s %-35s %-20s %-20s " % (
result[i]["num"], result[i]["name"], result[i]["singer"], result[i]["song_sheet"]))
num = input("请输入你想要下载歌曲的序号/please input the num you want to download:")
load_song(num, result) # 下载歌曲
