Python爬取新闻网数据

![Python爬取新闻网数据[Python基础]](https://www.zixueka.com/wp-content/uploads/2023/10/1696934386-07efd0d1e19f432.jpg)
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
python免费学习资料以及群交流解答点击即可加入
基本开发环境
- Python 3.6
- Pycharm
import parsel
import requests
import re
目标网页分析
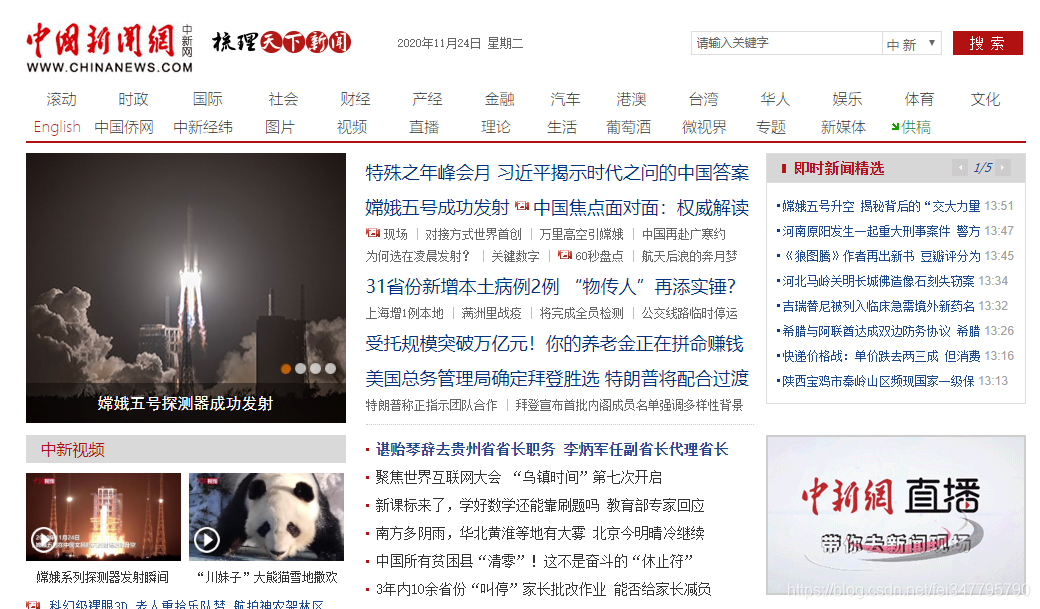
今天就爬取新闻网中的国际新闻栏目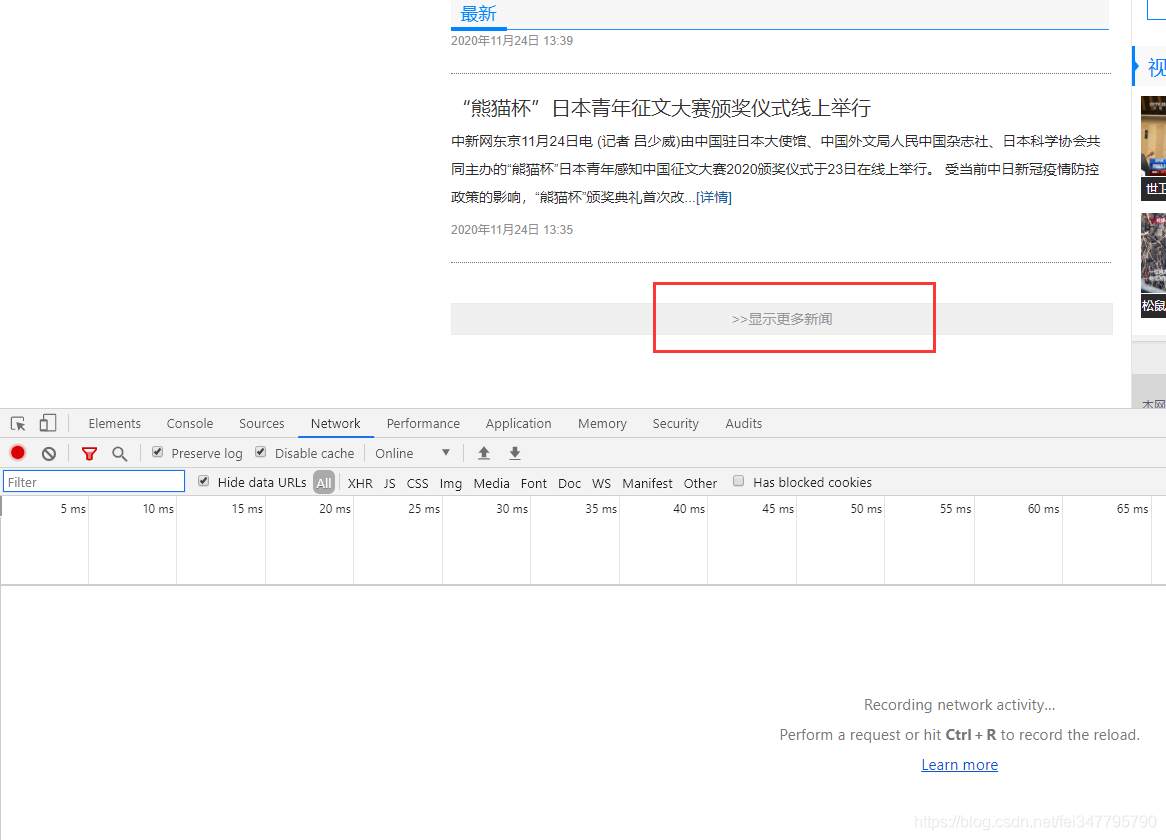
点击显示更多新闻内容
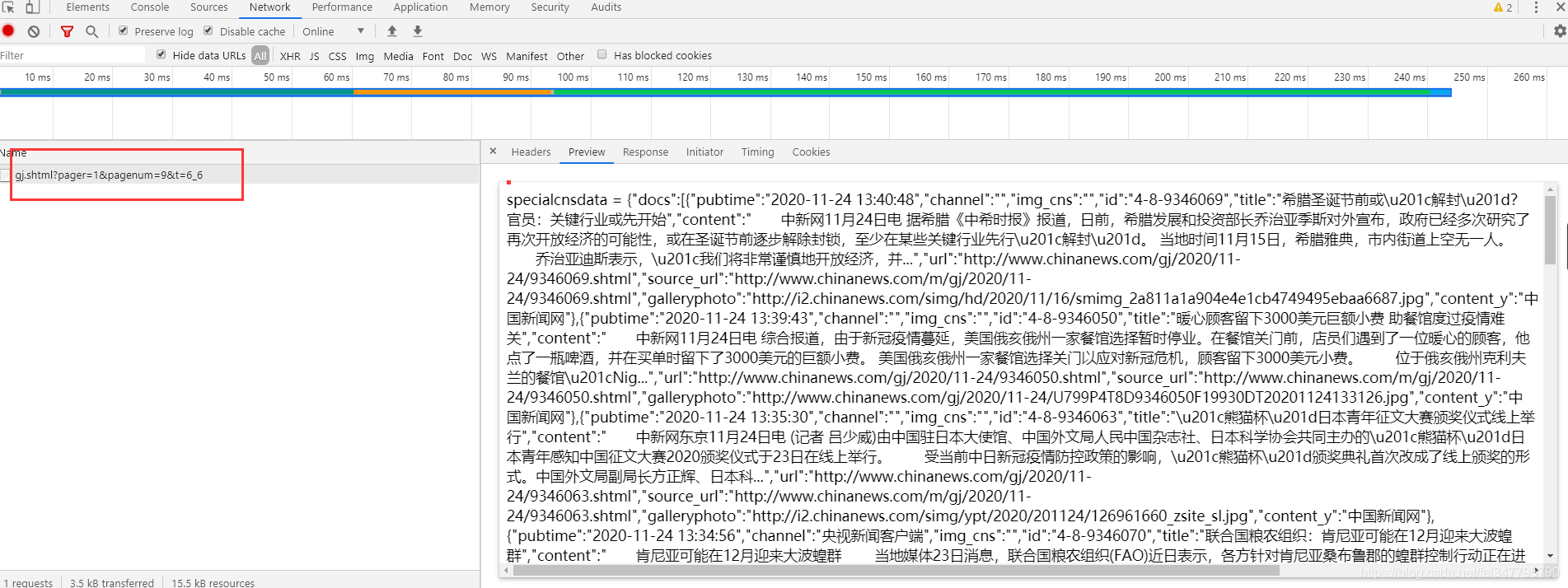
可以看到相关的数据接口,里面有新闻标题以及新闻详情的url地址
如何提取url地址
1、转成json,键值对取值;
2、用正则表达式匹配url地址;
两种方法都可以实现,看个人喜好
根据接口数据链接中的pager 变化进行翻页,其对应的就是页码。
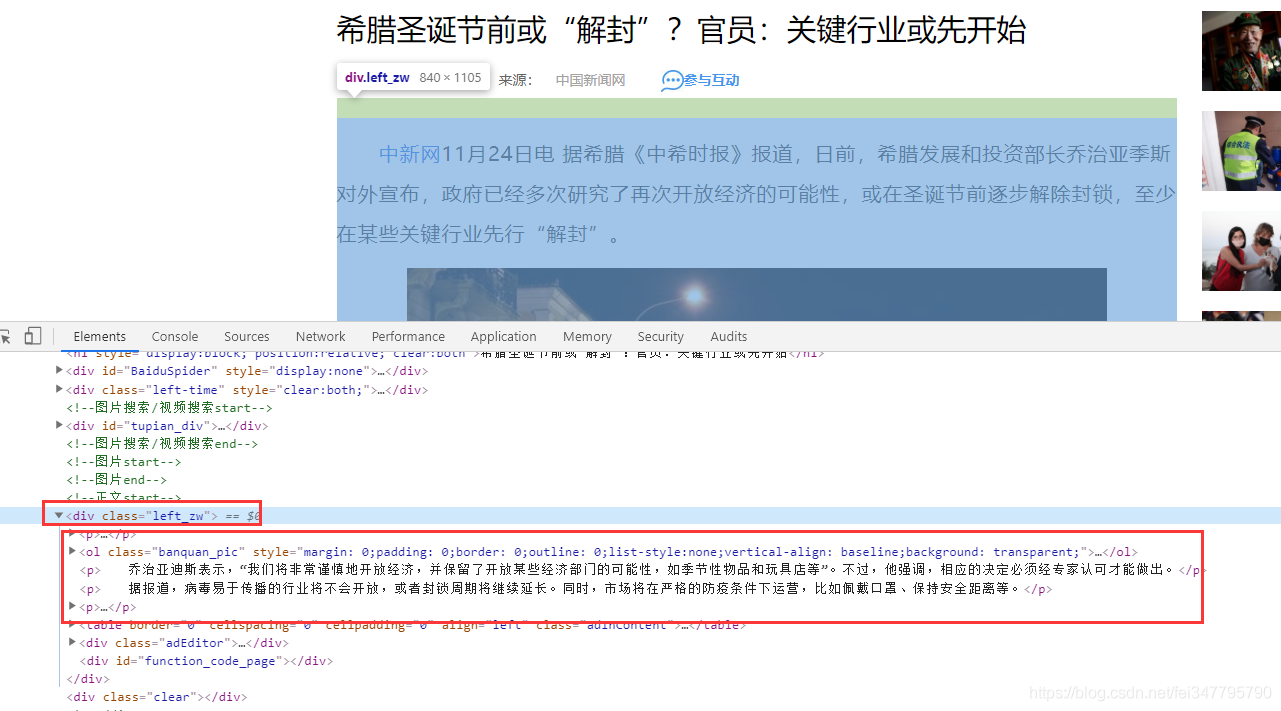
详情页可以看到新闻内容都是在 div标签里面 p 标签内,按照正常的解析网站即可获取新闻内容。
保存方式
1、你可以保存txt文本形式
2、也可以保存成PDF形式
之前也讲过关于爬取文章内容保存成 PDF ,可以点击下方链接查看相关保存方式。
Python爬取比比网中标标书并保存成PDF格式
python爬取CSDN博客文章并制作成PDF文件
本篇文章的话,就使用保存txt文本的形式吧。
整体爬取思路总结
- 在栏目列表页中,点击更多新闻内容,获取接口数据url
- 接口数据url中返回的数据内容中匹配新闻详情页url
- 使用常规解析网站操作(re、css、xpath)提取新闻内容
- 保存数据
代码实现
- 获取网页源代码
def get_html(html_url):
"""
获取网页源代码 response
:param html_url: 网页url地址
:return: 网页源代码
"""
response = requests.get(url=html_url, headers=headers)
return response
- 获取每篇新闻url地址
def get_page_url(html_data):
"""
获取每篇新闻url地址
:param html_data: response.text
:return: 每篇新闻的url地址
"""
page_url_list = re.findall(""url":"(.*?)"", html_data)
return page_url_list
- 文件保存命名不能含有特殊字符,需要对新闻标题进行处理
def file_name(name):
"""
文件命名不能携带 特殊字符
:param name: 新闻标题
:return: 无特殊字符的标题
"""
replace = re.compile(r"[/:*?"<>|]")
new_name = re.sub(replace, "_", name)
return new_name
- 保存数据
def download(content, title):
"""
with open 保存新闻内容 txt
:param content: 新闻内容
:param title: 新闻标题
:return:
"""
path = "新闻" + title + ".txt"
with open(path, mode="a", encoding="utf-8") as f:
f.write(content)
print("正在保存", title)
- 主函数
def main(url):
"""
主函数
:param url: 新闻列表页 url地址
:return:
"""
html_data = get_html(url).text # 获得接口数据response.text
lis = get_page_url(html_data) # 获得新闻url地址列表
for li in lis:
page_data = get_html(li).content.decode("utf-8", "ignore") # 新闻详情页 response.text
selector = parsel.Selector(page_data)
title = re.findall("<title>(.*?)</title>", page_data, re.S)[0] # 获取新闻标题
new_title = file_name(title)
new_data = selector.css("#cont_1_1_2 div.left_zw p::text").getall()
content = "".join(new_data)
download(content, new_title)
if __name__ == "__main__":
for page in range(1, 101):
url_1 = "https://channel.chinanews.com/cns/cjs/gj.shtml?pager={}&pagenum=9&t=5_58".format(page)
main(url_1)
运行效果图