经典必备之Python爬虫入门(一)


很多人都或多或少听说过 Python 爬虫,我也一直很感兴趣,所以也花了一个下午入门了一下轻量级的爬虫。为啥是轻量级的爬虫呢,因为有的网页是比较复杂的,比如需要验证码、登录验证或者需要证书才能访问,我们了解爬虫的概念和架构,只需要做一些简单的爬取工作即可,比如爬取百度百科这种纯信息展示的网页,这些都是不需要登录的静态网页。即便再复杂的爬虫网页和爬虫框架,实际上都离不开这一套基本的爬虫架构。
爬虫简介
爬虫是一段自动抓取互联网信息的程序。每个网页都有一个URL,从一个网页入口开始,通过各种URL的跳转形成一个相互指向的关系,最终可以形成一种网状结构,这就是互联网。理论上来说,一个庞大的网页项目,从入口开始,总能通过某种跳转路径到达项目系统中的任何一个网页,当我们人工的从网页上获取信息的时候,只能跟着步骤,一步一步的点击跳转,最终获取到我们希望得到的信息。
比如典型的,我昨天想领养一只猫咪,我先点开同城网站,然后找到宠物分类,再找到猫咪分类,再选择一些条目,比如是领养而不是购买,年龄在半岁以下,狸花猫等等这些特性,最后点击搜索,网页给了我具体的条目列表,我通过人工的方式,获取了我想要的信息。虽然定位精准,但不免很浪费人力时间。
而爬虫就是一个这样的自动程序,我们设定好我们需要的主题和目标,比如「猫咪」、「6个月」等标签,爬虫会从某个特定URL入手,自动的访问它所关联的URL,并且提取出我们需要的数据。可以说爬虫就是自动访问互联网,并且提取价值数据的程序。
爬虫的价值就在于此,可以获取将互联网上巨量的数据都为我所用,有了这些数据,我们就可以进行学习和分析,或者利用数据做出相关的产品。
爬取 GitHub 中一天浏览量和 star 提升数最高的项目,有了这个数据,就可以做出一个 GitHub 开源项目推荐的项目。
现在各大网站的歌曲都有版权保护,下载歌曲不太方便,可以通过歌曲名字,爬取网上所有免费下载链接,这样就可以轻易做出一个歌曲搜索下载的聚类工具。
可以说,只要有数据,没有做不到的,只有你想不到的,数据就在放在互联网上,通过爬虫我们可以让数据发挥更大的作用和价值,在大数据时代,爬虫毋庸置疑是一门一线技术。
爬虫基本架构
我们先来看一下简单的爬虫架构图

首先我们需要一个爬虫调度端来启动和停止爬虫,同时也要通过它来监视爬虫的状态,并通过它提供接口来作具体的数据应用。这个部分不属于爬虫本身。
图中阴影方框中的部分就是我们爬虫程序。因为有的页面的入口有很多,我们可以通过不同的URL调度路径来访问这个界面,那么作为一个智能的爬虫软件,当遇到我们已经爬取过的URL的时候,应该选择过滤,而不是再次爬取。URL管理器就是用来存储已经爬取URL和将要爬取URL的工具的。
从URL管理器中选择一个待爬取的URL,将其传送给网页下载器,下载器会把网页以字符串的形式下载下来,并把这个字符串交给网页解析器去解析,网页解析器一方面会把你需要获取的价值信息提取出来归还给调度器,另一方面,如果遇到该网页有新的URL待爬取,就会把这个URL传送给URL管理器。从此,这三个模块进行循环,直到该网页相关的所有URL都爬取完毕。
更加清晰的动态运行流程,可以用一个时序图来表示。大家可以对照着上面的步骤理解下。
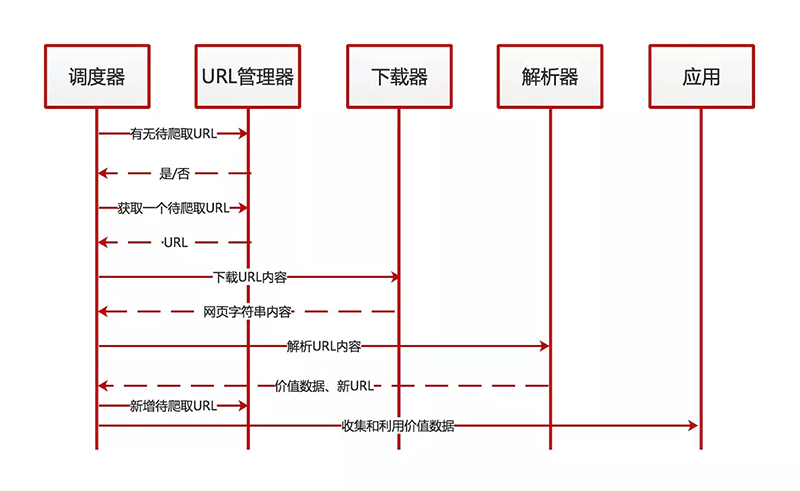
题外话,时序图是我最喜欢的一种帮助梳理逻辑的图,大家可以学习一下,在工作和学习过程中会帮助很大~
来源:PY学习网:原文地址:https://www.py.cn/article.html
