怎么用Python爬虫爬取电影


豆瓣电影Top250应该是属于最容易抓取的静态网页类型,直接用python的urllib库发送请求,即可获得浏览器上看到的所有信息。不需要登录,也没有动态加载信息。
一、思路分析
用chrome打开豆瓣电影Top250页面, https://movie.douban.com/top250。如下图第一部电影,肖申克的救赎,电影名称、导演、主演、年份、评分、评价人数这些信息是我们需要的。我们用浏览器或者python向浏览器发送请求的时候,返回的是html代码,我们平时用浏览器浏览网页看到的这些图文并茂的规整的页面其实是html代码在经过浏览器渲染后的结果。所以我们需要找到要抓取信息在html代码中的位置。这就叫html解析,解析的工具有很多。比如:正则表达式、Beautifulsoup、Xpath、css等,这里采用xpath方法。
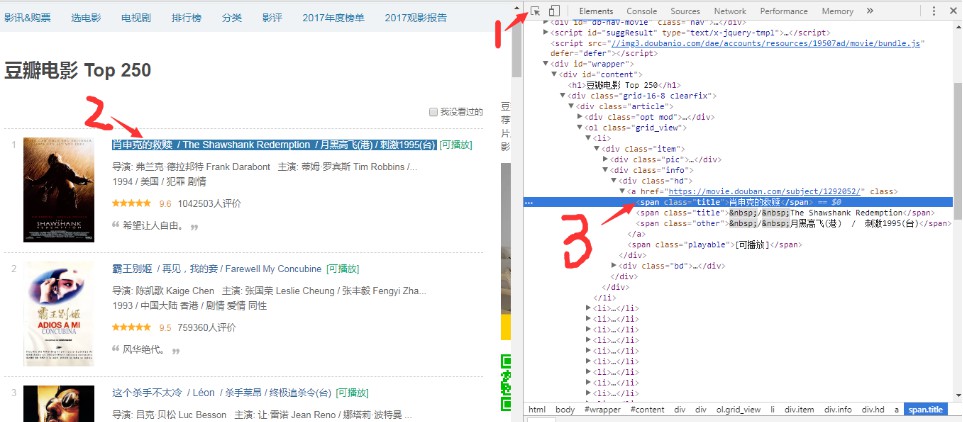
如何找到信息在html中的位置呢,首先鼠标右键检查,打开当前网页的html代码。然后先单击箭头1处的箭头,把鼠标移动到你要查找的信息上,如箭头2处的电影名:肖申克的救赎 ,右边就会显示你点击信息在html代码中的位置(箭头3)。一个网页的html代码全部打开看上去会非常的繁多,其实html代码是一层一层结构化的,非常规整的。每一对尖括号包起来的是一个标签,比如箭头3的<span> ……</span>,这就是一个span标签。span叫标签名,class="title"是标签的属性,“肖申克的救赎”是标签的内容。
相关推荐:《Python教程》
标签span在html代码中的完整路径应该是:
body/div[@id="wrapper"]/div[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[1]/a/span[1]
用xpath查找元素就是按照路径一层层找下去,[@id="wrapper"]表示查找的标签的属性,用标签加上属性,我们可以更方便的定位,不用从头找到尾。div[1]、span[1]表示要查找的是该标签下的第1个div标签,第1个span标签。找到span标签可以用方法span[1]/text()取出其中的内容,pan[1]/@class可以取出属性值。
电影封面的下载,只要找到图片的链接地址,就可以调用urllib库中的函数urllib.request.urlretrieve()直接下载。找到图片链接的方法和上面一样,把鼠标移动到封面上,右边就会显示链接的位置。
每一页网址的变化规律,一页可以显示25部电影,就是说这250部电影一共有10页。观察前几页的网址很容易发现规律:就是start后面跟的参数变化,等于(页数-1)*25,而且发现后面的filter去掉也不影响。
第一页:https://movie.douban.com/top250
第二页:https://movie.douban.com/top250?start=25&filter=
第三页:https://movie.douban.com/top250?start=50&filter=
二、代码实现
先用urllib发送请求,获得返回的源代码html。返回的html是字符串格式,需要用tree.HTML转化成xpath能处理的对象。观察html代码,每一个<li> …</li>,标签刚好对应一部电影,所以我们先定位到每一个li标签,在对每一个li标签解析获得这个电影的各个信息。
data_title —电影名称
data_info —电影信息(导演、主演、上映时间)
data_quote —电影引言
data_score —电影评分
data_num —电影评论人数
data_picurl—电影封面链接
完整代码如下:
from urllib import request
from lxml import etree
#构造函数,抓取第i页信息
def crow(i):
# 构造第i页的网址
url='https://movie.douban.com/top250?start='+str(25*i)
# 发送请求,获得返回的html代码并保存在变量html中
html=request.urlopen(url).read().decode('utf-8')
#将返回的字符串格式的html代码转换成xpath能处理的对象
html=etree.HTML(html)
#先定位到li标签,datas是一个包含25个li标签的list,就是包含25部电影信息的list
datas = html.xpath('//ol[@class="grid_view"]/li')
a=0
for data in datas:
data_title=data.xpath('div/div[2]/div[@class="hd"]/a/span[1]/text()')
data_info=data.xpath('div/div[2]/div[@class="bd"]/p[1]/text()')
data_quote=data.xpath('div/div[2]/div[@class="bd"]/p[2]/span/text()')
data_score=data.xpath('div/div[2]/div[@class="bd"]/div/span[@class="rating_num"]/text()')
data_num=data.xpath('div/div[2]/div[@class="bd"]/div/span[4]/text()')
data_picurl=data.xpath('div/div[1]/a/img/@src')
print("No: "+str(i*25+a+1))
print(data_title)
#保存电影信息到txt文件,下载封面图片
with open('douban250.txt','a',encoding='utf-8')as f:
#封面图片保存路径和文件名
picname='F:/top250/'+str(i*25+a+1)+'.jpg'
f.write("No: "+str(i*25+a+1)+'
')
f.write(data_title[0]+'
')
f.write(str(data_info[0]).strip()+'
')
f.write(str(data_info[1]).strip()+'
')
#因为发现有几部电影没有quote,所以这里加个判断,以免报错
if data_quote:
f.write(data_quote[0]+'
')
f.write(data_score[0]+'
')
f.write(data_num[0]+'
')
f.write('
'*3)
#下载封面图片到本地,路径为picname
request.urlretrieve(data_picurl[0],filename=picname)
a+=1
for i in range(10):
crow(i)
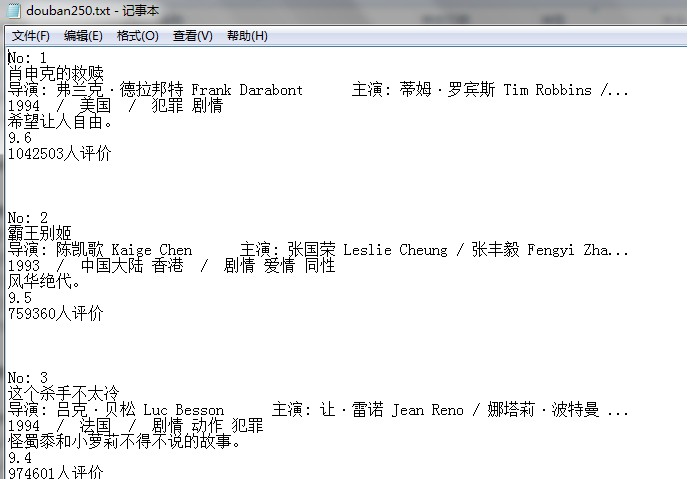
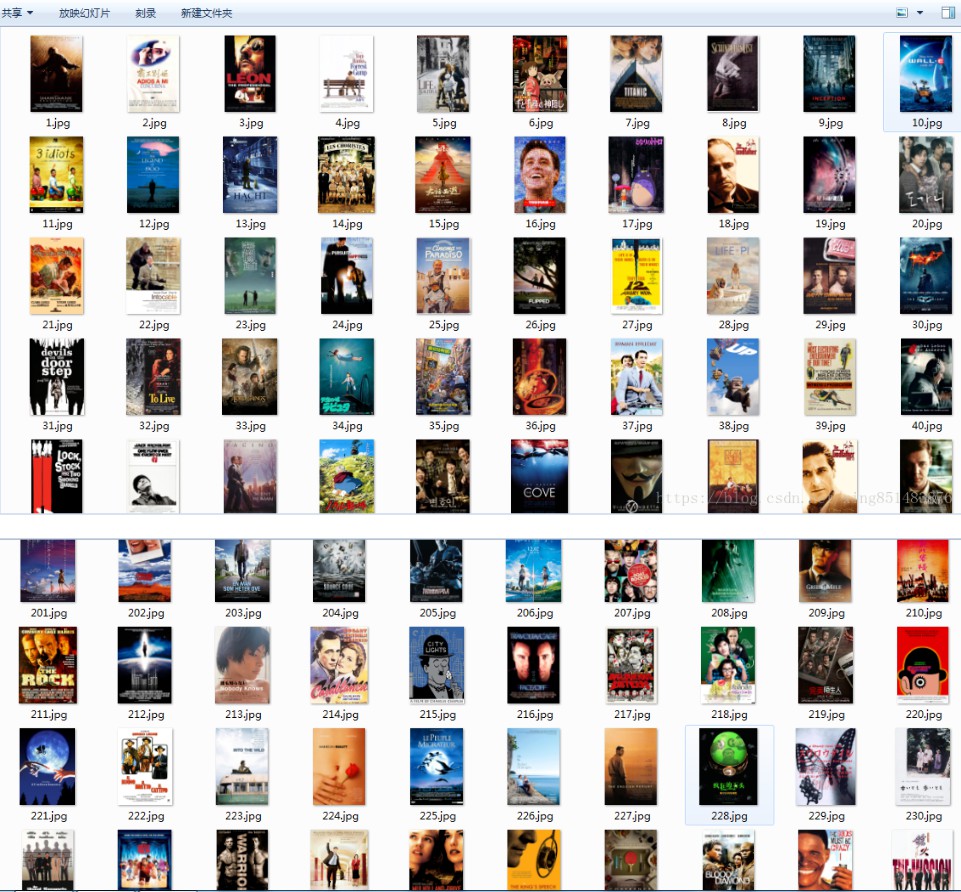
三、结果如下:
来源:PY学习网:原文地址:https://www.py.cn/article.html
