代码优化与程序加速指南——针对数值优化和深度学习领域


背景
当需要处理规模较大、任务较复杂的优化问题或训练神经网络时,我们经常会遇到程序运行时间长或无法完成的情况。然而,这不一定是由于问题规模大或计算机硬件能力的限制。即使尝试使用更高性能的服务器或计算机,也不能保证能够有效地加速代码运行。因为高性能的硬件通常需要与为高性能计算而设计的代码相匹配。
本文旨在为程序加速提供一些代码方面的优化思路,通过优化代码结构、设计高性能计算方案,来有效加速程序运行,提高程序运行效率。需要注意的是,本文只涉及代码层面的加速方案,不包括算法、硬件等方面的优化措施。文章的撰写基于个人经验,如果有不足之处,敬请指出。
本文将介绍一些常见的代码优化技巧,例如使用向量化和并行化的方式来加速计算、减少内存的占用以及利用编译器优化代码的循环结构等。
代码优化
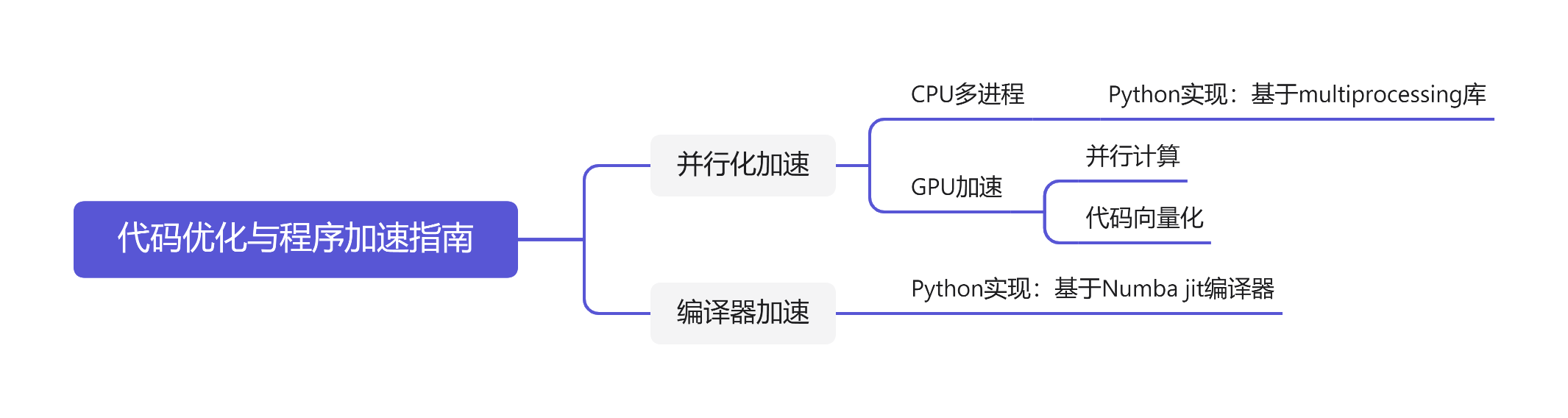
简单来说,实现程序优化的方式主要有两种思路。一种是并行化任务,编写并行化代码,以利用多核CPU或GPU的并行计算能力来加速程序运行。另一种则是利用编译器的代码优化机制,将Python、MATLAB等需要解释器执行的代码部分编译成机器代码,以实现更快的程序运行速度。
1 并行化
程序优化的另一种思路是通过并行化加速程序。并行化需要软件与硬件配合,但前提是总任务能够被分解为同时进行的子任务。并行化有两种方式,一种依靠多核CPU实现多进程操作,一种依靠GPU完成。下面我们将分别介绍这两种方式的实现方法。
1.1 CPU多进程操作
多进程操作是利用CPU多核心的特性来实现并行化计算。在多进程操作中,程序将被分解成多个子任务,每个子任务都在独立的进程中运行。这些进程可以并行地执行不同的任务,从而加速程序的运行。多进程操作可以使用Python的multi-processing库来实现。
1.1.1 多进程
当我们在电脑上运行程序时,实际上是启动了一个进程。进程是指在操作系统中运行的一个程序,它占据着系统的一些资源,如内存、CPU时间等。在传统的单进程计算模型中,所有的任务都在同一个进程中执行,如果任务需要进行复杂的计算,就会耗费大量时间,且无法利用多核CPU的优势。而多进程技术可以将任务分解为多个子任务,每个子任务在一个独立的进程中执行,从而实现并行计算,提高了计算效率。
1.1.2 多进程的Python实现
在使用multi-processing库进行多进程操作时,首先需要将任务分解成多个子任务,并将每个子任务交给不同的进程来执行。
这是multiprocessing库的代码框架
import multiprocessing
def worker(num):
"""子进程要执行的任务"""
print(f"Worker {num} is running")
return
if __name__ == "__main__":
processes = []
num_processes = 4
# 创建多个子进程
for i in range(num_processes):
p = multiprocessing.Process(target=worker, args=(i,))
processes.append(p)
p.start()
# 等待所有子进程完成
for p in processes:
p.join()
print("All workers are done")
在这个例子中,我们首先定义了一个worker函数,它是每个子进程要执行的任务。然后在主进程(if name==”main“)中,我们创建了num_processes个子进程,并将它们添加到processes列表中。接着,我们遍历processes列表,用Process类中的start()方法启动每个子进程,并等待它们完成。最后输出”All workers are done”,表示所有子进程都已经执行完毕。
这个示例代码只是一个简单的例子,实际应用中,我们可以根据具体情况编写更复杂的子进程任务函数,并使用multiprocessing库中提供的各种工具实现更复杂的多进程操作。
1.2 GPU
相比于CPU,GPU有着更多的计算核心和更高的计算能力,可以更好地支持并行化计算。因此,利用GPU进行代码优化可以大幅度提高程序的运行效率。而要在Python中使用GPU进行代码优化,则需要使用GPU编程框架,比较常见的有NVIDIA开发的CUDA框架以及OpenCL框架。
1.2.1 GPU并行计算的Python实现
其中,CUDA是由NVIDIA推出的GPU编程框架,它可以让开发者利用GPU的并行计算能力,加速各种计算密集型任务。CUDA提供了一组API,可以方便地进行GPU的编程,支持C/C++、Python、Java等多种编程语言。在使用CUDA时,需要使用CUDA工具包,其中包括CUDA驱动程序、CUDA运行时库和CUDA工具。
以下是一个简单的利用CUDA框架实现向量加法的例子:
import numpy as np
from numba import cuda
# 定义向量加法函数
@cuda.jit
def vector_add(a, b, c):
i = cuda.grid(1)
if i < len(c):
c[i] = a[i] + b[i]
# 定义主程序
if __name__ == "__main__":
# 定义向量大小
n = 100000
# 在主机上生成随机向量
a = np.random.randn(n).astype(np.float32)
b = np.random.randn(n).astype(np.float32)
c = np.zeros(n, dtype=np.float32)
# 将数据传输到GPU显存中
d_a = cuda.to_device(a)
d_b = cuda.to_device(b)
d_c = cuda.to_device(c)
# 定义线程块和线程数量
threads_per_block = 64
blocks_per_grid = (n + (threads_per_block - 1)) // threads_per_block
# 执行向量加法操作
vector_add[blocks_per_grid, threads_per_block](d_a, d_b, d_c)
# 将结果从GPU显存中传输回主机内存
d_c.copy_to_host(c)
# 打印结果
print(c)
在上述代码中,我们首先定义了一个vector_add函数,用于将两个向量相加并将结果存储在第三个向量中。然后我们生成了两个随机向量,并将其传输到GPU显存中。接着,我们定义了线程块和线程数量,并在GPU部分,我们需要注意的是代码的向量化,也就是多利用矩阵运算编写代码,而不是多重for loop的串行计算。这样可以充分利用GPU的并行计算能力,加速神经网络的训练过程。例如,可以使用cuBLAS库来实现矩阵乘法,使用cuDNN库来实现卷积操作等。执行了向量加法操作。最后,我们将结果从GPU显存中传输回主机内存,并打印出结果。
值得注意的是,由于CUDA框架需要GPU的支持,因此我们在使用CUDA框架时需要保证系统中有可用的GPU。
1.2.2利用GPU训练神经网络
当涉及到训练深度神经网络时,GPU可以发挥其优势,因为神经网络的训练往往需要进行大量的矩阵运算,这正是GPU擅长的任务。为了使用GPU进行深度神经网络的训练,需要利用一些特定的框架和库,比如TensorFlow和PyTorch。
在利用CUDA框架进行神经网络训练时,首先,需要定义一个在GPU上运行的张量(tensor)来存储神经网络的参数。然后,将数据加载到GPU内存中,并将计算任务分配到GPU核心上。
下面是一个简单的基于PyTorch和CUDA的神经网络训练代码示例:
import torch
import torch.nn as nn
import torch.optim as optim
# 定义神经网络模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 定义训练数据和标签
inputs = torch.randn(1, 3, 32, 32)
labels = torch.randn(1, 10)
# 将神经网络模型移动到GPU上
net = Net().cuda()
# 将训练数据和标签移动到GPU上
inputs = inputs.cuda()
labels = labels.cuda()
# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.SGD(net.parameters(), lr=0.01)
# 开始训练
for epoch in range(100):
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print("Epoch %d, Loss: %.4f" % (epoch+1, loss.item()))
在上面的代码中,我们通过xxx.cuda()的方法将模型、训练数据和标签都加载到GPU内存中,从而使得训练循环中涉及的运算全部在GPU上完成。
1.2.3 注意事项
值得特别注意的是,如果要利用GPU实现加速,那么一定要保证代码的向量化。简单来说,就是尽可能用矩阵运算的方式来表示数值计算过程,而不是用多重for loop的形式。
这是因为,GPU相较于CPU只是强在并行上,但是计算能力是差于CPU的,多层for循环这样的串行计算并不适合GPU。用沐神的话说,如果把CPU比作是一个大学生的话,GPU就像是一群小学生。大学生可以做微积分这样的任务,小学生只能做加减乘除。但如果把一个微积分这样的任务分解成多个加减乘除,那么一群小学生这样的GPU的优势就体现出来了。
举一个简单的例子,例如我们要设计一个这样的损失函数:
[L_ heta=-sum_{i=1}^{N}sum_{j=1}^{N_i}w_{ij}log(p(x_i^j|M))
]
