Slava项目(1):实现近似LRU/LFU内存淘汰策略


slava是作者参与的一个github开源项目,该项目的目标是用Go语言构建一个高性能K-V云数据库。
在本文中,作者将介绍Slava中内存淘汰策略的实现。Slava中目前实现了四种内存淘汰策略,分别是maxMemoryLruAllKeys,maxMemoryLfuAllKeys,maxMemoryLruTtl和maxMemoryLfuTtl。当内存淘汰被触发时,会根据配置来调用对应的内存淘汰策略,如果是前两者那么将会根据近似LRU或LFU算法从全部的Key中挑选一部分进行淘汰,如果是后两者则只会从设置了过期时间的Key中挑选一部分进行淘汰。下面作者将以回答问题的方式来进行详细介绍。
1 为什么要使用近似算法而不是传统实现
首先来看LRU(Least recently used,最近最少使用),LRU算法的核心思想是“如果数据最近被访问过,那么将来被访问的几率也高”,所以该算法会选择最近最久没有使用的内容将其淘汰。那么如何实现LRU算法呢?想要淘汰最久没有被使用的数据,那么我们或者需要记录下每个数据的使用时间,或者是维护一个数据结构,该数据结构应该满足两个需求:
(1)通过该数据结构我们能够快速的获取我们想要的最久没有被使用的数据
(2)当我们访问某个数据的时候,需要对该数据结构进行修改并且代价要够低
1.1 传统LRU/LFU算法实现存在的问题
传统的LRU借助哈希表和双向链表来维护了一个数据结构来满足LRU算法的需求,其详细实现可以参考https://juejin.cn/post/7027062270702125093
如果我们采用传统的实现(哈希表+双向链表),那么会存在两个问题:
(1)内存占用的问题,我们需要一个Map来存储每个Key对应到链表中节点的指针,还需要一个链表来维护所有当前在内存中的数据。
(2)并发安全问题,我们每次对数据进行读或写都需要对链表进行更新操作来维护LRU的正确性,由于Slava采用的是多协程并发进行业务处理的工作方式,那么对链表的操作就需要加锁来保证并发安全。那么在高并发的场景下,协程每次读/写操作都需要获取锁来修改链表,会造成大量的阻塞,过于影响运行效率。所以,这种方法不适合Slava高并发的场景。根据上述分析我们可以知道,像传统实现那样维护一个数据结构来满足需求所带来的性能损耗是难以接受的。
而LFU的传统实现同样需要借助哈希表和链表,或是借助堆,使用传统LFU方法带来的性能损耗同样是难以接受的。
1.2 如何去记录每个数据被访问的最近时间和次数
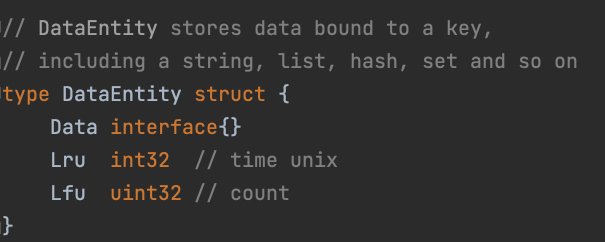
如果我们记录下每个数据最近被访问的时间或是最近被访问的次数,在需要淘汰时遍历数据找出需要淘汰的那个呢?这里首先牵扯到如何记录下每个数据被访问的时间,由于Slava内部k-v数据库对于数据对象的存储方式是将其封装为一个DataEntity对象,也就是在Slava内部数据库中每一个Key都对应了一个DataEntity对象,DataEntity结构体中Data字段被声明为接口类型,从而能够容纳各种数据。我们可以在DataEntity中新增两个字段用于记录数据被访问的最新时间和访问次数。