Telco Customer Churn 电信用户流失预测案例 –


任务目标:
对于电信运营商来说,用户流失有很多偶然因素,不过通过对用户属性和行为的数字化描述,我们或许也能够在这些数据中,挖掘导致用户流失的“蛛丝马迹”,并且更重要的一点,如果能够实时接入这些数据,或许还能够进一步借助模型来对未来用户流失的风险进行预测,从而及时制定挽留策略,来防止用户真实流失情况发生。
机器学习建模目标:
在此背景下,实际的算法建模目标有两个,其一是对流失用户进行预测,其二则是找出影响用户流失的重要因子,来辅助运营人员来进行营销策略调整或制定用户挽留措施。
综合上述两个目标我们不难发现,我们要求模型不仅要拥有一定的预测能力,并且能够输出相应的特征重要性排名,并且最好能够具备一定的可解释性,也就是能够较为明显的阐述特征变化是如何影响标签取值变化的。据此要求,我们首先可以考虑逻辑回归模型。逻辑回归的线性方程能够提供非常好的结果可解释性,同时我们也可以通过逻辑回归中的正则化项也可以用于评估特征重要性。
- Stage 1.业务背景解读与数据探索
在拿到数据(接受任务)的第一时间,需要对数据(也就是对应业务)的基本背景进行解读。由于任何数据都诞生于某业务场景下,同时也是根据某些规则来进行的采集或者计算得出,因此如果可以,我们应当尽量去了解数据诞生的基本环境和对应的业务逻辑,尽可能准确的解读每个字段的含义,而只有在无法获取真实业务背景时,才会考虑退而求其次通过数据情况去倒推业务情况。
当然,在进行了数据业务背景解读后,接下来就需要对拿到的数据进行基本的数据探索。一般来说,数据探索包括数据分布检验、数据正确性校验、数据质量检验、训练集/测试集规律一致性检验等。当然,这里可能涉及到的操作较多,也并非所有的操作都必须在一次建模过程中全部完成。但作为教学案例,我们将在后续的内容中详细介绍每个环节的相关操作及目的。 - Stage 2.数据预处理与特征工程
在了解了建模业务背景和基本数据情况后,接下来我们就需要进行实际建模前的“数据准备”工作了,也就是数据预处理(数据清洗)与特征工程。其中,数据清洗主要聚焦于数据集数据质量提升,包括缺失值、异常值、重复值处理,以及数据字段类型调整等;而特征工程部分则更倾向于调整特征基本结构,来使数据集本身规律更容易被模型识别,如特征衍生、特殊类型字段处理(包括时序字段、文本字段等)等。
当然,很多时候我们并不刻意区分数据清洗与特征工程之间的区别,很多时候数据清洗的工作也可以看成是特征工程的一部分。同时,也有很多时候我们也不会一定要求在不同阶段执行不同操作,例如如果在数据探索时发现缺失值比例较小,则可以直接对其进行均值/众数填补,而不用等到特征工程阶段统一处理,再例如很多特征工程的方法需要结合实际建模效果来判别,所以有的时候特征衍生也会和建模过程交替进行。 - Stage 3.算法建模与模型调优
在经过一系列准备工作后,就将进入到最终建模环节了,建模过程既包括算法训练也包括参数调优。当然,很多时候建模工作不会一蹴而就,需要反复尝试各种模型、各种调参方法、以及模型融合方法。此外,很多时候我们也需要根据最终模型输出结果来进行数据预处理和特征工程相关方法调整。
数据解读与预处理:
获取数据:
在数据集主页,下载csv,放到主目录下:
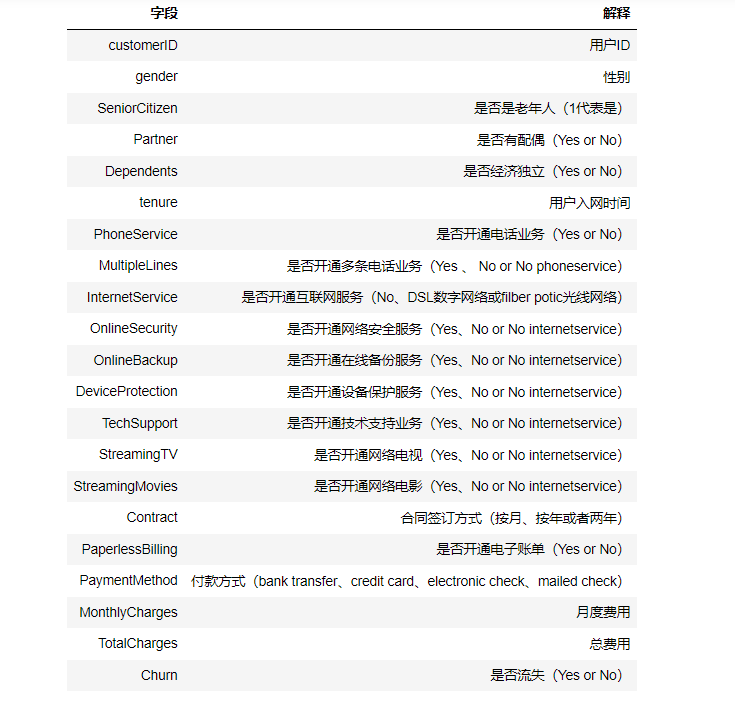
| customerID | gender | SeniorCitizen | Partner | Dependents | tenure | PhoneService | MultipleLines | InternetService | OnlineSecurity | … | DeviceProtection | TechSupport | StreamingTV | StreamingMovies | Contract | PaperlessBilling | PaymentMethod | MonthlyCharges | TotalCharges | Churn | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7590-VHVEG | Female | 0 | Yes | No | 1 | No | No phone service | DSL | No | … | No | No | No | No | Month-to-month | Yes | Electronic check | 29.85 | 29.85 | No |
| 1 | 5575-GNVDE | Male | 0 | No | No | 34 | Yes | No | DSL | Yes | … | Yes | No | No | No | One year | No | Mailed check | 56.95 | 1889.5 | No |
| 2 | 3668-QPYBK | Male | 0 | No | No | 2 | Yes | No | DSL | Yes | … | No | No | No | No | Month-to-month | Yes | Mailed check | 53.85 | 108.15 | Yes |
| 3 | 7795-CFOCW | Male | 0 | No | No | 45 | No | No phone service | DSL | Yes | … | Yes | Yes | No | No | One year | No | Bank transfer (automatic) | 42.30 | 1840.75 | No |
| 4 | 9237-HQITU | Female | 0 | No | No | 2 | Yes | No | Fiber optic | No | … | No | No | No | No | Month-to-month | Yes | Electronic check | 70.70 | 151.65 | Yes |
5 rows × 21 columns
1.由于数据集没有提供数据字典,但是可以通过字段名字知道其意义。
得到数据以后,我们首先检查数据的完整性。目前来看,我们得到的数据没有缺省值(没有None和Nan),但并不排除可能存在用别的值表示缺失值的情况,稍后我们将对其进行进一步分析。
字段类型探索:
接下来,我们应该围绕数据集的字段类型进行一些调整:(以方便后来我们的使用)
- 时序字段处理
大多数字段都属于离散型字段,并且object类型居多。由于建模分析中,无法直接使用object类型对象,所以进行类型转化。通常来说,我们会将字段划分为连续型字段和离散型字段,并且根据离散字段的具体含义来进一步区分是名义型变量还是有序变量。不过在划分连续/离散字段之前,我们发现数据集中存在一个入网时间字段,看起来像是时序字段。但是!时间标注的时序字段即不数据连续型字段或离散型字段(尽管可以将其看成是离散字段,但这样做会损失一些信息),因此我们需要重点关注入网时间字段是否是时间标注的字段:
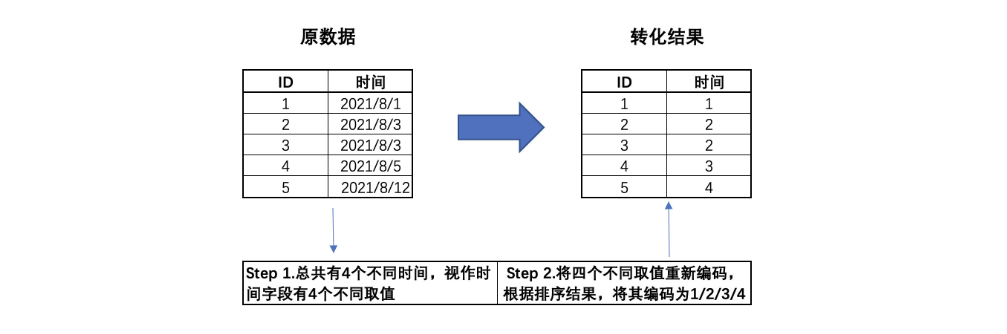
在第三季度中,这些用户的行为发生在某73天内,因此入网时间字段有73个取值。不过由于该字段是经过字典排序后的结果,因此已经损失了原始信息,即每位用户实际的入网时间。而在实际的分析过程中,我们可以转化后的入网时间字段看成是离散变量,当然也可以将其视作连续变量来进行分析,具体选择需要依据模型来决定。此处我们先将其视作离散变量,后续根据情况来进行调整。
- 连续/离散型变量标注
们需要对不同类型字段进行转化。并且在此过程中,我们需要检验是否存在采用别的值来表示缺失值的情况。就像此前所说我们通过isnull只能检验出None(Python原生对象)和np.Nan(numpy/pandas在读取数据文件时文件内部缺失对象的读取后表示形式)对象。但此外我们还需要注意数据集中是否包含采用某符号表示缺失值的情况,例如某些时候可能使用空格(其本质也是一种字符)来代替空格:
此时在进行检验时,空格的数据并不会被识别为缺失值(空格本身也是一种值)。
但根据实际情况来看,空格可能确实是代表着数据采集时数据是缺失的,因此我们仍然需要将其识别然后标记为缺失值,此时可以通过比较数据集各列的取值水平是否和既定的一致来进行检查。例如,对于上述df数据集来说,特征A和B默认情况只有Y和N两种取值,而B列由于通过空格表示了缺失值,因此用nunique查看数据集的话,B列将出现3种取值:
