gRPC介绍(以Java为例)


1.简介
1.1 gRPC的起源
RPC是Remote Procedure Call的简称,中文叫远程过程调用。用于解决分布式系统中服务之间的调用问题。通俗地讲,就是开发者能够像调用本地方法一样调用远程的服务。所以,RPC的作用主要体现在这两个方面:
-
屏蔽远程调用跟本地调用的区别,让我们感觉就是调用项目内的方法;
-
隐藏底层网络通信的复杂性,让我们更专注于业务逻辑的开发。
长期以来,谷歌有一个名为 Stubby 的通用 RPC 框架,用来连接成千上万的微服务,这些微服务跨多个数据中心并且使用完全不同的技术来构建。
Stubby 的核心 RPC 层每秒能处理数百亿次的互联网请求。Stubby有许多很棒的特性,但无法标准化为业界通用的框架,这是因为它与谷歌内部的基础设施耦合得过于紧密。
2015 年,谷歌发布了开源 RPC 框架 gRPC,这个 RPC 基础设施具有标准化、可通用和跨平台的特点,旨在提供类似 Stubby 的可扩展性、性能和功能,但它主要面向社区。
在此之后,gRPC 的受欢迎程度陡增,很多大型公司大规模采用了gRPC,如 Netflix、Square、Lyft、Docker、CoreOS 和思科。接着,gRPC 加入了云原生计算基金会(Cloud Native Computing Foundation,CNCF),这是最受欢迎的开源软件基金会之一,它致力于让云原生计算具备通用性和可持续性。gRPC 从 CNCF 生态系统项目中获得了巨大的发展动力。
1.2 gRPC的定义
gRPC官网地址:https://grpc.io
gRPC 是由Google开发的一个语言中立、高性能、通用的开源RPC框架,基于ProtoBuf(Protocol Buffers) 序列化协议开发,且支持众多开发语言。面向服务端和移动端,基于 HTTP/2 设计。
在每个 gRPC 发布版本中,字母 g 的含义都不同。比如 1.1 版本的 g 代表 good(优秀),1.2版本的 g 代表 green(绿色)。具体可以参考https://github.com/grpc/grpc/blob/master/doc/g_stands_for.md

gRPC框架是围绕定义服务的思想,显式定义了可以被远程调用的方法,包括入参和出参的信息等。gRPC服务端负责这些方法的具体实现,而客户端拥有这些方法的一个存根(stub),这样就可以远程调用到服务端的方法。

2.Quick Start
接下来,我们通过一个小例子,来感受一下gRPC的开发过程。
2.1 开发步骤
在开发 gRPC 应用程序时,先要定义服务接口,其中应包含如下信息:消费者消费服务的方式、消费者能够远程调用的方法以及调用这些方法所使用的参数和消息格式等。在服务定义中所使用的语言叫作接口定义语言(interface definition language,IDL)。gRPC 使用 Protocol Buffer 作为 IDL 来定义服务接口。
借助服务定义,可以生成服务器端代码,也就是服务器端骨架(skeleton) ,它通过提供低层级的通信抽象简化了服务器端的逻辑。同时,还可以生成客户端代码,也就是客户端存根(stub),它使用抽象简化了客户端的通信,为不同的编程语言隐藏了低层级的通信。就像调用本地函数那样,客户端能够远程调用我们在服务接口定义中所指定的方法。底层的 gRPC 框架处理所有的复杂工作,通常包括确保严格的服务契约、数据序列化、网络通信、认证、访问控制、可观察性等。
2.2 定义Protocol Buffer
Protocol Buffer(简称Protobuf) 是语言中立、平台无关、实现结构化数据序列化的可扩展机制。它就像JSON, 但比JSON体积更小,传输更快,具体可查阅其官网:https://developers.google.cn/protocol-buffers/docs/overview
Protobuf在 gRPC 的框架中主要有三个作用:定义数据结构、定义服务接口,通过序列化和反序列化方式提升传输效率。
Protobuf文件的后缀是.proto,定义以下服务:
syntax = "proto3"; // 表示使用的protobuf版本是proto3。还有一个版本是proto2,建议使用最新版本。
import "google/protobuf/wrappers.proto";// 引入包装类型,没有默认值。下面会讲
option java_multiple_files = true; // 如果是false,则只生成一个java文件。反之生成多个。
option java_package = "com.khlin.grpc.proto"; // 类的包名
option java_outer_classname = "UserProto"; // 想要生成的类的名字
option objc_class_prefix = "khlin"; // 设置Objective-C类前缀,该前缀位于此.proto中所有Objective-C生成的类和枚举之前。似乎Java没用上。
package user; // protobuf消息类型的包类,同样是为了防止命名冲突。
// 定义一个服务
service UserService{
// 简单模式
rpc getUserInfo(UserRequest) returns (UserResponse);
// 客户端流
rpc batchGetUserInfo(stream UserRequest) returns (google.protobuf.StringValue);
// 服务端流
rpc getUserInfoStream(UserRequest) returns (stream UserResponse);
// 双向流
rpc biGetUserInfo(stream UserRequest) returns (stream UserResponse);
}
// 定义一个入参类型
message UserRequest{
string id = 1;
}
// 定义一个出参类型
message UserResponse{
string id = 1;
int32 phoneNumber = 2; // 电话号码
string email = 3; // 邮箱地址
int32 serialNumber = 4; // 序列号
}
下面简单介绍一下数据类型相关知识。
1.序号
每一个字段被赋予了一个唯一的序号,从1开始。Protobuf是通过二进制数据的方式传输,所以需要知道每个位置存储的是什么字段,并且建议一旦定义好就不要修改,防止引起兼容性问题。
2.字段约束
每一个字段可以是以下一种约束:
singular proto3中的默认约束,最广泛的约束
repeated 类比集合类型
map 类比Map类型
已经舍弃的约束:
optional proto3中舍弃,在proto2当中表示该字段可为空
required proto3中舍弃,在proto2当中表示该字段不能为空
3.数据类型
| .proto Type | Notes | Java/Kotlin Type |
|---|---|---|
| double | double | |
| float | float | |
| int32 | 使用变长编码方式,不适用于负数。负数使用sint32。 | int |
| int64 | 使用变长编码方式,不适用于负数。负数使用sint64。 | long |
| uint32 | 使用变长编码方式 | int |
| uint64 | 使用变长编码方式 | long |
| sint32 | 使用变长编码。有符号的整型值。它们比普通的int32能更有效地编码负数。 | int |
| sint64 | 使用变长编码。有符号的整型值。它们比普通的int64能更有效地编码负数。 | long |
| fixed32 | 固定4字节 | int[2] |
| fixed64 | Always eight bytes. More efficient than uint64 if values are often greater than 256. | long[2] |
| sfixed32 | Always four bytes. | int |
| sfixed64 | 固定8字节 | long |
| bool | boolean | |
| string | 字符串必须始终包含UTF-8编码或7位ASCII文本,且长度不能超过232。 | String |
| bytes | 可以包含不超过232的任意字节序列。 | ByteString |
具体语法查阅其官网:https://developers.google.cn/protocol-buffers/docs/proto3?hl=zh-cn
4.默认值
对于singular约束的字段,如果没有赋值,会赋上默认值。大部分与Java语法相同,需要注意的是string类型,它会默认赋上空字符串。可以引入 wrappers.proto,使用包装类型。
| 类型 | 默认值 |
|---|---|
| string | 空字符串 |
| bytes | 空byte数组 |
| bool | false |
| 数值类型 | 0 |
| enums | 定义的枚举第一个元素(默认必须为0) |
| 定义的message类型 | 不赋值 |
| repeated * | 空列表 |
这是我们定义的响应模型,可见它最终生成的string类型字段是有默认值的。
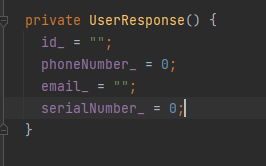
2.3 生成存根
可以通过官方提供的编译器,将Protobuf文件转成相应的Java代码。
1.获取工具
获取protoc软件。用于处理proto文件的工具软件,对proto文件生成消息对象和序列化及反序列化的Java实体类。下载地址:https://repo1.maven.org/maven2/com/google/protobuf/protoc/3.12.0/
获取protoc-gen-grpc-java插件。用于处理rpc定义的插件,生成针对rpc定义的Java接口。下载地址:https://repo1.maven.org/maven2/io/grpc/protoc-gen-grpc-java/1.32.1/
获取wrapper.proto。因为项目中用到了包装类型,所以需要下载这个文件,如果没使用到,则不需要。下载地址:https://github.com/protocolbuffers/protobuf/blob/main/src/google/protobuf/wrappers.proto
2.执行命令
将上面获取到的工具和User.proto文件放到同一个目录里面,新建一个java文件夹用于存放输出,具体的结构如下:
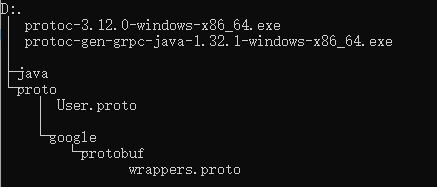
CMD进入该目录,执行以下命令
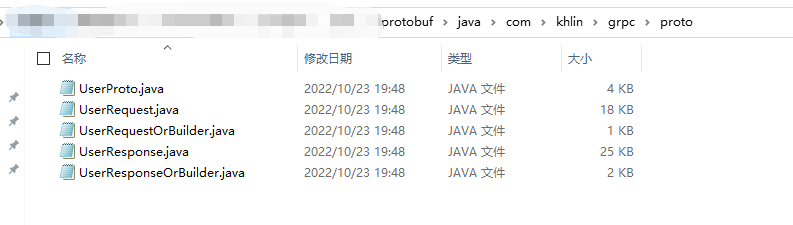
protoc-3.12.0-windows-x86_64.exe –java_out=java –proto_path=proto proto/User.proto
可以看到在这个目录底下已经生成了相应的类。
再执行以下命令生成gRPC接口
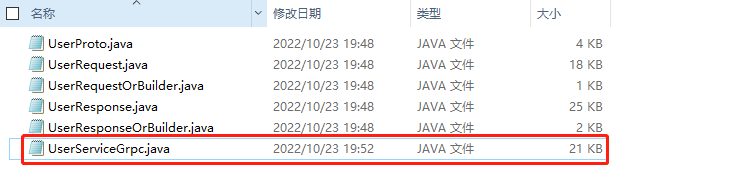
protoc-3.12.0-windows-x86_64.exe –plugin=protoc-gen-grpc-java=protoc-gen-grpc-java-1.32.1-windows-x86_64.exe –grpc-java_out=java –proto_path=proto proto/User.proto
可以看到增加了一个类。
生成存根还可以通过Maven插件的方式,更为高效简单。在后面介绍。
2.4 构建服务端
1. 创建Maven工程
命名为grpc-server,并引用依赖
<dependencies>
<dependency>
<groupId>io.grpc</groupId>
<artifactId>grpc-netty-shaded</artifactId>
<version>1.14.0</version>
</dependency>
<dependency>
<groupId>io.grpc</groupId>
<artifactId>grpc-protobuf</artifactId>
<version>1.14.0</version>
</dependency>
<dependency>
<groupId>io.grpc</groupId>
<artifactId>grpc-stub</artifactId>
<version>1.14.0</version>
</dependency>
</dependencies>
引入插件,就可以实现上面说的使用Maven插件生成Java类。
<build>
<extensions>
<extension>
<groupId>kr.motd.maven</groupId>
<artifactId>os-maven-plugin</artifactId>
<version>1.5.0.Final</version>
</extension>
</extensions>
<plugins>
<plugin>
<groupId>org.xolstice.maven.plugins</groupId>
<artifactId>protobuf-maven-plugin</artifactId>
<version>0.5.1</version>
<configuration>
<protocArtifact>com.google.protobuf:protoc:3.5.1-1:exe:${os.detected.classifier}</protocArtifact>
<pluginId>grpc-java</pluginId>
<pluginArtifact>io.grpc:protoc-gen-grpc-java:1.14.0:exe:${os.detected.classifier}</pluginArtifact>
</configuration>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>compile-custom</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
</plugins>
</build>
2. Maven插件的方式生成存根
和java目录平级的目录下,创建一个proto文件夹,并把User.proto放进去,如下图
通过Maven插件的compile和compile-custom,分别生成消息对象和接口。

在target中就会自动生成了对应的文件,将它们移动到对应的源目录底下即可。

3. 实现接口
具体可查阅附件工程。
public class UserService extends UserServiceGrpc.UserServiceImplBase {
/**
* 简单模式(Unary RPCs)
*
* @param request
* @param responseObserver
*/
@Override
public void getUserInfo(UserRequest request, StreamObserver<UserResponse> responseObserver) {
System.out.println("Received message:" + request.getId());
UserResponse userResponse = createResponse(request, 1);
responseObserver.onNext(userResponse);
responseObserver.onCompleted();
}
}
4. 服务启动
通过ServiceBuilder类,监听一个端口,并把具体的接口加上。
package com.khlin.grpc.proto.service;
import io.grpc.Server;
import io.grpc.ServerBuilder;
import java.io.IOException;
import java.util.Objects;
public class UserServer {
private static final int PORT = 5001;
public static void main(String[] args) throws IOException, InterruptedException {
//
Server server = ServerBuilder.forPort(PORT).addService(new UserService()).build().start();
System.out.println("Server started, listening on " + PORT);
Runtime.getRuntime()
.addShutdownHook(
new Thread(
() -> {
System.err.println("Shutting down gRPC server since JVM is shutting down.");
if (Objects.nonNull(server)) {
server.shutdown();
}
System.err.println("Server shut down.");
}));
server.awaitTermination();
}
}
2.5 构建客户端
1. 创建Maven工程
命名为grpc-client,引入同样的依赖。
2. 引入存根
把上面生成的存根放到源代码目录下即可。
3. 服务启动
创建一个ManagedChannel对象,连接服务端地址。
stub对象调用的getUserInfo方法,就是之前服务定义的同一个接口,这就实现了在远程调用接口如同本地调用一样的效果。
package org.example;
import com.khlin.grpc.proto.UserRequest;
import com.khlin.grpc.proto.UserResponse;
import com.khlin.grpc.proto.UserServiceGrpc;
import io.grpc.ManagedChannel;
import io.grpc.ManagedChannelBuilder;
import io.grpc.StatusRuntimeException;
import java.util.Scanner;
/**
* Hello world!
*/
public class App {
private static final String QUIT = "q";
public static void main(String[] args) {
ManagedChannel channel = ManagedChannelBuilder.forAddress("localhost", 5001).usePlaintext().build();
Scanner scanner = new Scanner(System.in);
try {
// 一元
getUserInfo(channel, scanner);
} finally {
scanner.close(); // 关闭资源
}
}
/**
* 一元模式
*
* @param channel
* @param scanner
*/
private static void getUserInfo(ManagedChannel channel, Scanner scanner) {
UserServiceGrpc.UserServiceBlockingStub stub = UserServiceGrpc.newBlockingStub(channel);
String userId = null;
do {
System.out.print("Please input user id: ");
userId = scanner.next(); // 等待输入值
UserRequest request = UserRequest.newBuilder().setId(userId).build();
UserResponse response;
try {
response = stub.getUserInfo(request);
System.out.println("Message from gRPC-Server. Phone number: " + response.getPhoneNumber() + ", email: " + response.getEmail());
} catch (StatusRuntimeException e) {
e.printStackTrace();
}
} while (!QUIT.equals(userId)); // 如果输入的值不版是#就继续输入
}
我们可以运行Demo感受一下。
3.底层原理
3.1 gRPC通信原理
要了解gRPC的通信原理,首先回顾一下RPC框架是怎么工作的。在 RPC 的系统中,服务器端会实现一组可以远程调用的方法。客户端会生成一个存根,该存根为服务器端的方法提供抽象。这样一来,客户端应用程序可以直接调用存根方法,进而调用服务器端应用程序的远程方法。
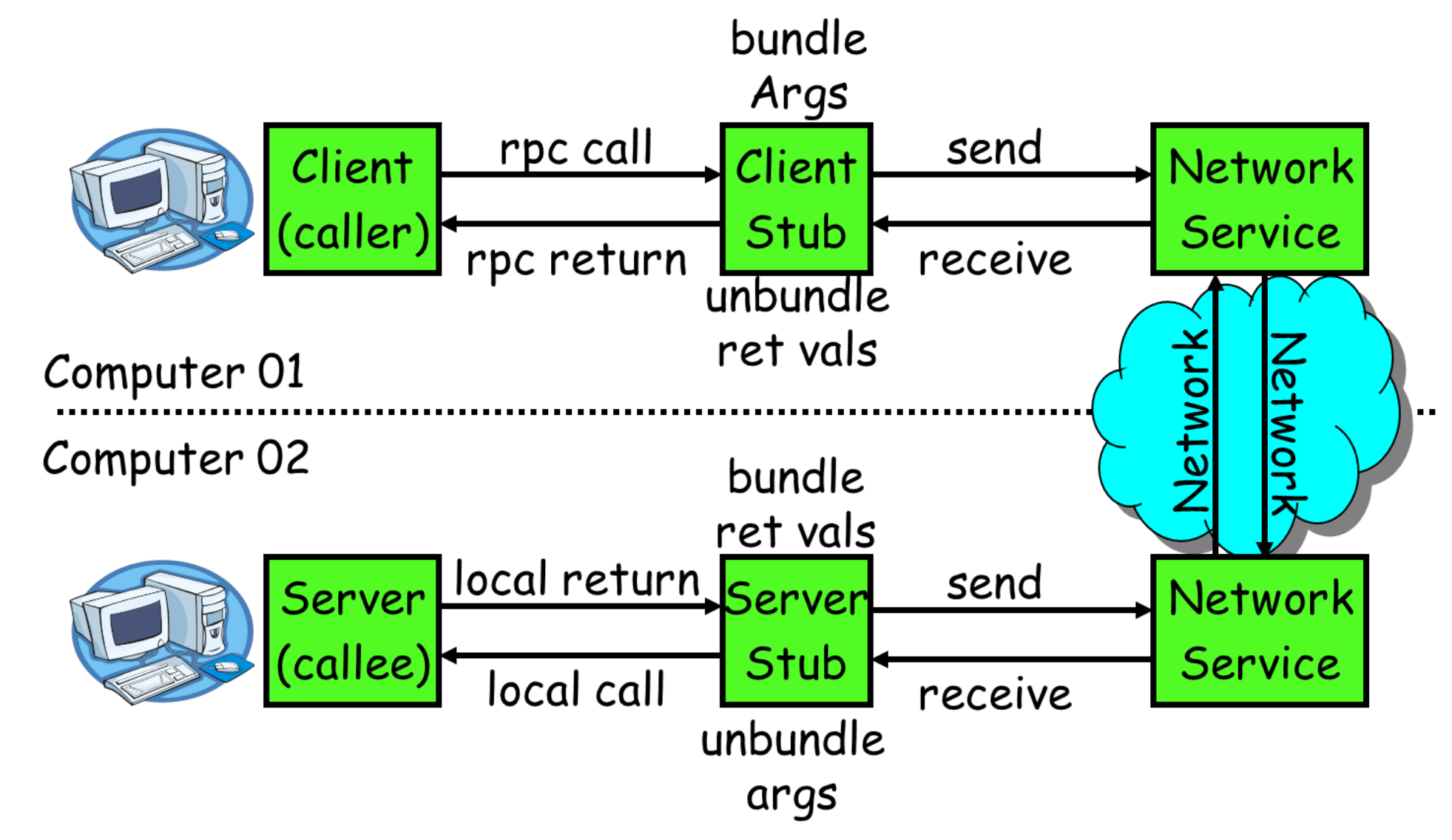
gRPC 构建在两个快速、高效的协议之上,也就是 protocol buffers 和HTTP/2。protocol buffers 是一个语言中立、平台无关的数据序列化协议,并且提供了可扩展的机制来实现结构化数据的序列化。当序列化完成之后,该协议会生成二进制载荷,这种载荷会比常见的 JSON 载荷更小,并且是强类型的。序列化之后的二进制载荷会通过名为 HTTP/2 的二进制传输协议进行发送。
HTTP/2 是互联网协议 HTTP 的第 2 个主版本。HTTP/2 是完全多路复用的,这意味着 HTTP/2 可以在 TCP 连接上并行发送多个数据请求。这样一来,使用 HTTP/2 编写的应用程序更快、更简洁、更稳健。
以上诸多因素使 gRPC 成为高性能的 RPC 框架。
具体到Demo里面的方法,一次调用的流程大体如下:

下面,我们将介绍一下,这两个协议是如何工作的。
3.2 HTTP/2简介
HTTP/2 (原名HTTP/2.0)即超文本传输协议 2.0,是下一代HTTP协议。RFC 7540 定义了 HTTP/2 的协议规范和细节, RFC 7541定义了头部压缩。
1. HTTP/1的问题
TCP连接数限制
因为并发的原因一个TCP连接在同一时刻可能发送一个http请求。所以为了更快的响应前端请求,浏览器会建立多个tcp连接,但是第一tcp连接数量是有限制的。现在的浏览器针对同一域名一般最多只能创建6~8个请求;第二创建tcp连接需要三次握手,增加耗时、cpu资源、增加网络拥堵的可能性。所以,缺点明显。
线头阻塞 (Head Of Line Blocking) 问题
每个 TCP 连接同时只能处理一个请求 – 响应,浏览器按 FIFO 原则处理请求,如果上一个响应没返回,后续请求 – 响应都会受阻。为了解决此问题,出现了 管线化 – pipelining 技术,但是管线化存在诸多问题,比如第一个响应慢还是会阻塞后续响应、服务器为了按序返回相应需要缓存多个响应占用更多资源、浏览器中途断连重试服务器可能得重新处理多个请求、还有必须客户端 – 代理 – 服务器都支持管线化。
Header 内容多
每次请求 Header不会变化太多,没有相应的压缩传输优化方案。特别是想cookie这种比较长的字段
2. HTTP/2特性
首先需要了解几个概念。
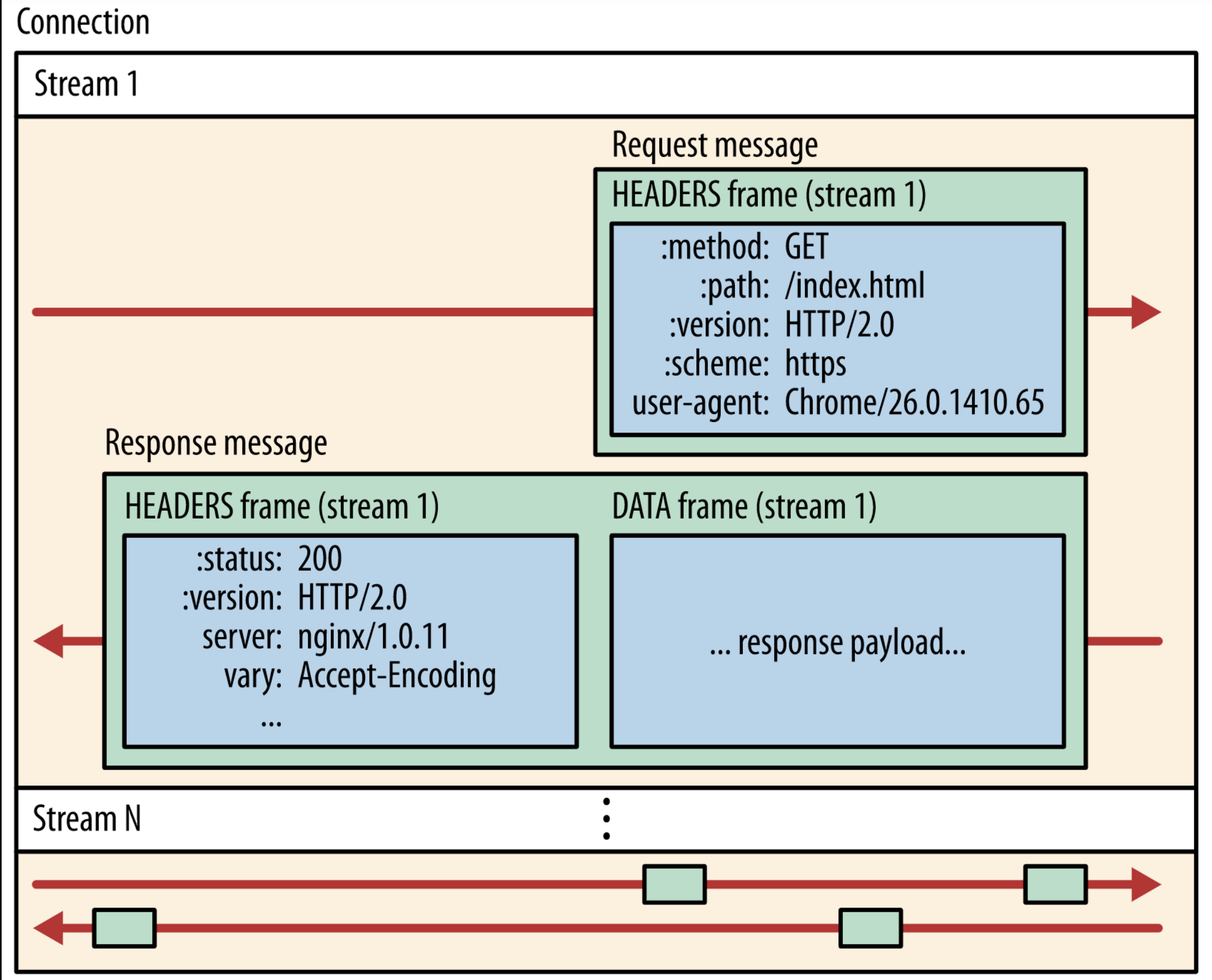
- 数据流: 已建立的连接内的双向字节流,可以承载一条或多条消息。
- 消息: 与逻辑请求或响应消息对应的完整的一系列帧。
- 帧: HTTP/2 通信的最小单位,每个帧都包含帧头,至少也会标识出当前帧所属的数据流。
这些概念的关系总结如下:
- 所有通信都在一个 TCP 连接上完成,此连接可以承载任意数量的双向数据流。
- 每个数据流都有一个唯一的标识符和可选的优先级信息,用于承载双向消息。
- 每条消息都是一条逻辑 HTTP 消息(例如请求或响应),包含一个或多个帧。
- 帧是最小的通信单位,承载着特定类型的数据,例如 HTTP 标头、消息负载等等。 来自不同数据流的帧可以交错发送,然后再根据每个帧头的数据流标识符重新组装。
和HTTP/1的对比
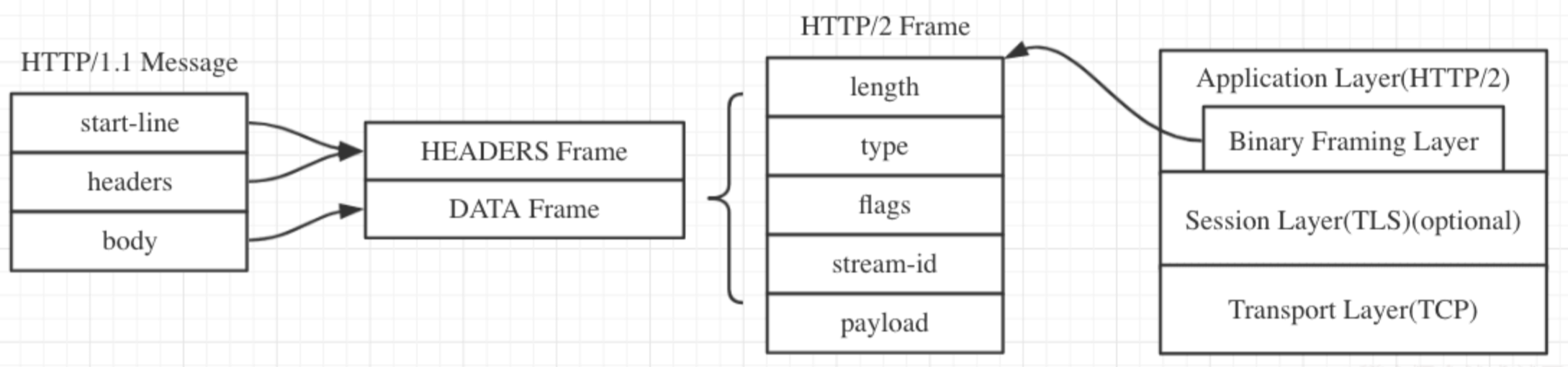
多路复用 Multiplexing
在一个 TCP 连接上,我们可以向对方不断发送帧,每帧的 stream identifier 的标明这一帧属于哪个流,然后在对方接收时,根据 stream identifier 拼接每个流的所有帧组成一整块数据。
把 HTTP/1.1 每个请求都当作一个流,那么多个请求变成多个流,请求响应数据分成多个帧,不同流中的帧交错地发送给对方,这就是 HTTP/2 中的多路复用。
流的概念实现了单连接上多请求 – 响应并行,解决了线头阻塞的问题,减少了 TCP 连接数量和 TCP 连接慢启动造成的问题
所以 http2 对于同一域名只需要创建一个连接,而不是像 http/1.1 那样创建多个连接:
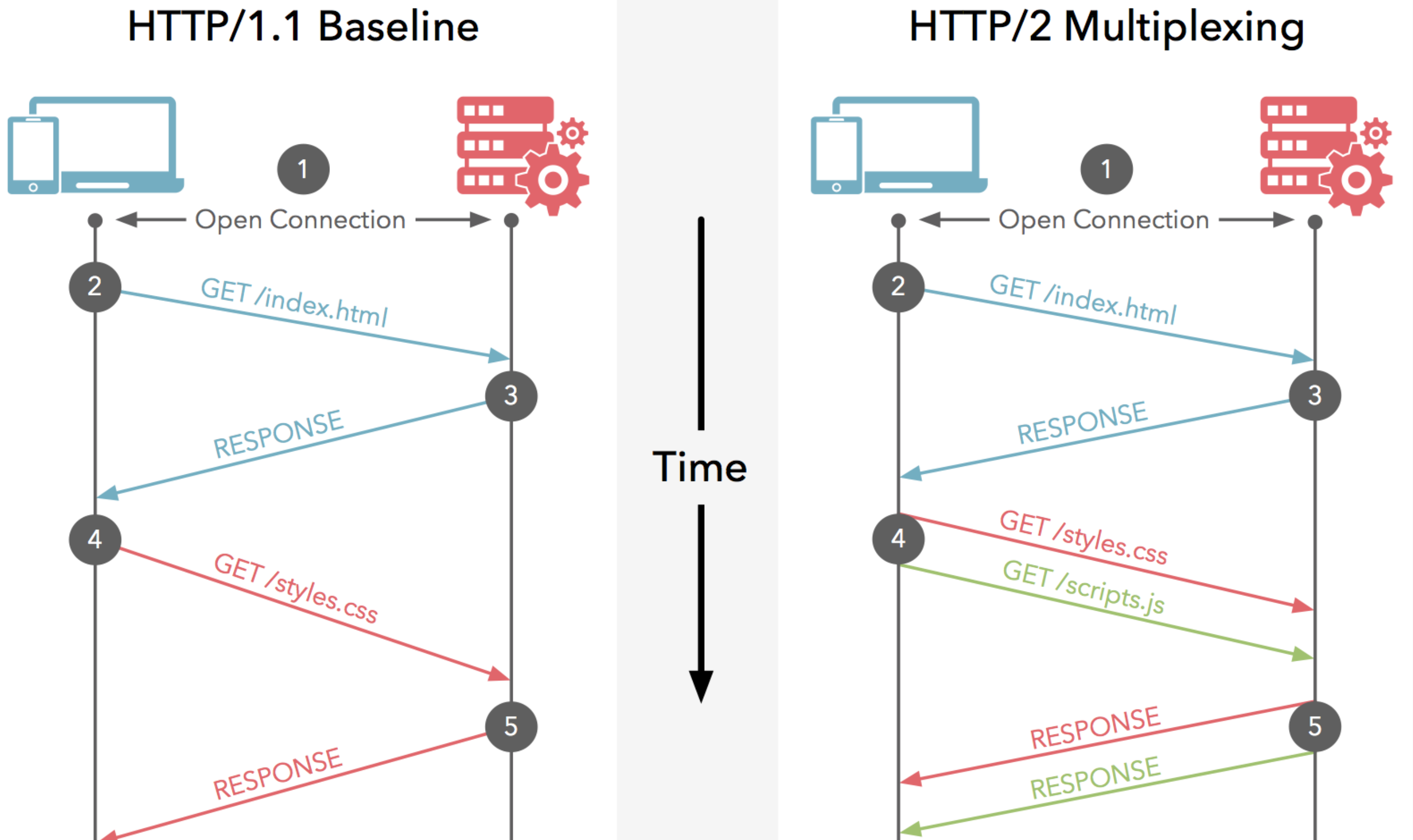
头部压缩
头部压缩采用HPACK算法,需要在支持 HTTP/2 的浏览器和服务端之间:
- 维护一份相同的静态字典(Static Table),包含常见的头部名称,以及特别常见的头部名称与值的组合;
- 维护一份相同的动态字典(Dynamic Table),可以动态地添加内容;
- 支持基于静态哈夫曼码表的哈夫曼编码(Huffman Coding);
静态字典的作用有两个:1)对于完全匹配的头部键值对,例如 :method: GET,可以直接使用一个字符表示;2)对于头部名称可以匹配的键值对,例如 cookie: xxxxxxx,可以将名称使用一个字符表示。
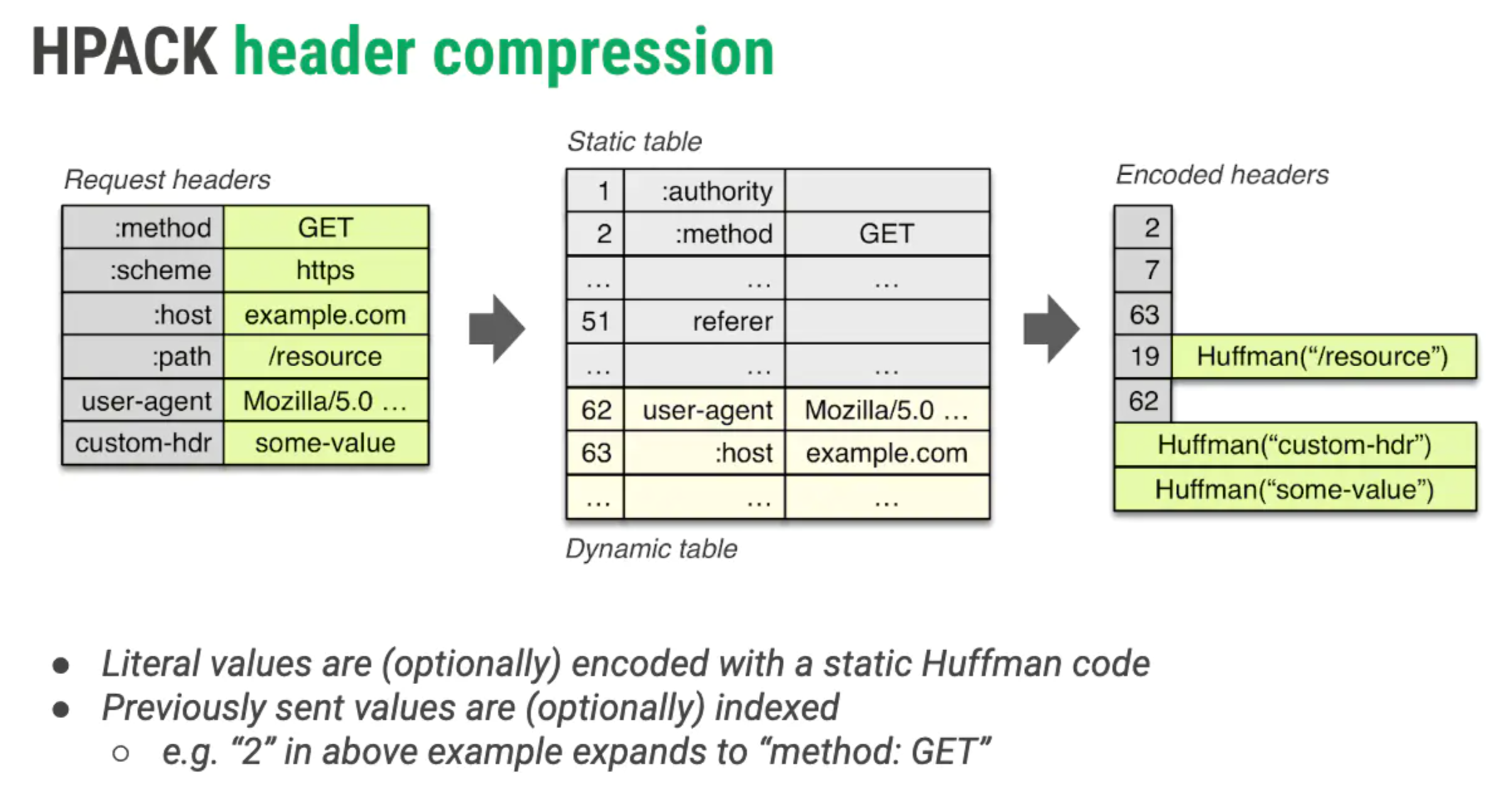
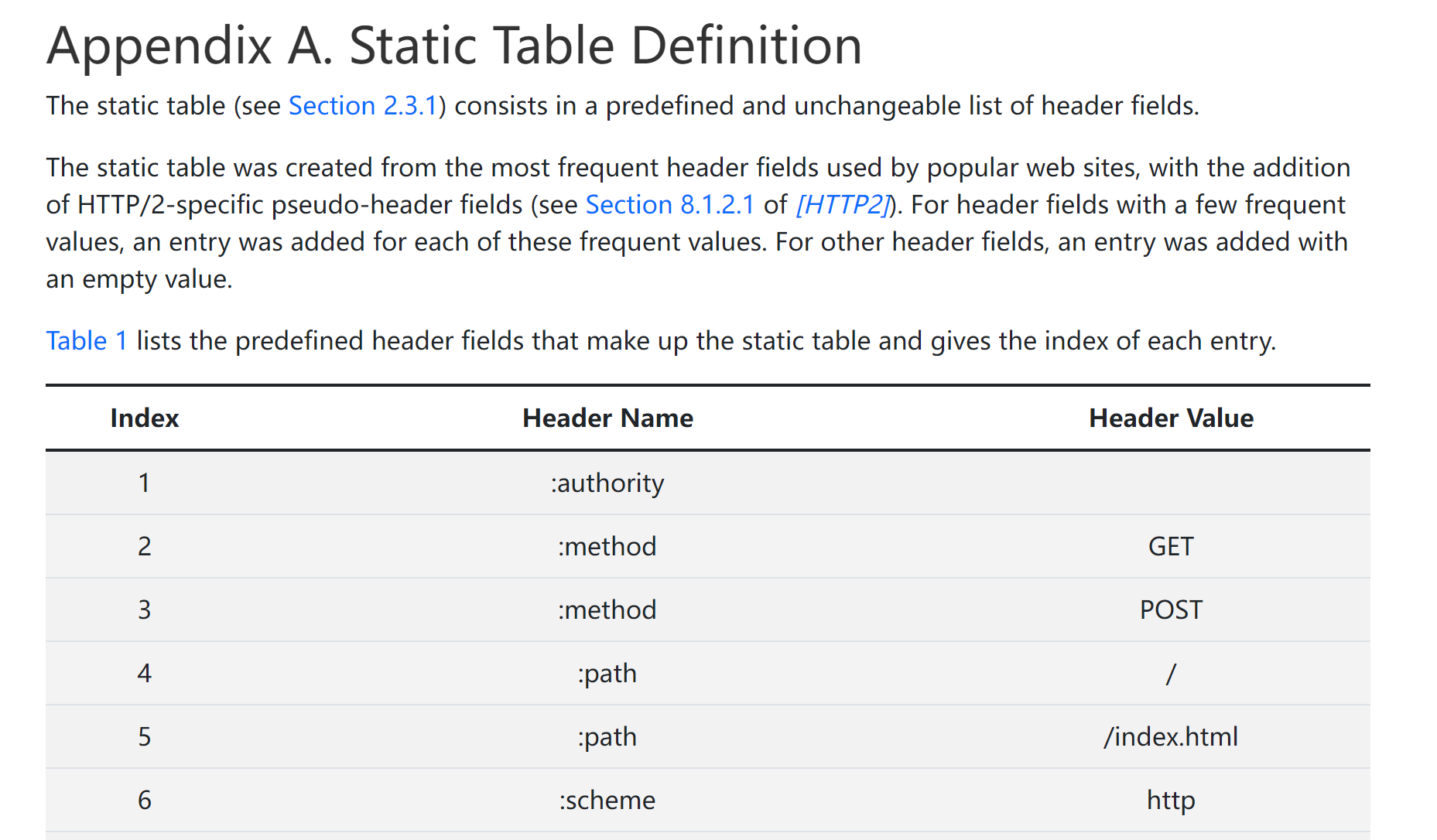
具体的静态表定义可以参考RFC7541规范 https://httpwg.org/specs/rfc7541.html#static.table.definition。
3.3 ProtoBuf编码原理
proto消息类型文件一般以 .proto 结尾,可以在一个 .proto 文件中定义一个或多个消息类型。
1. TLV
protobuf高效的秘密在于它的编码格式,它采用了 TLV(tag-length-value) 编码格式。每个字段都有唯一的 tag 值,它是字段的唯一标识。length 表示 value 数据的长度,length 不是必须的,对于固定长度的 value,是没有 length 的。value 是数据本身的内容,通过解析t和l,就能明确字段值的长度,如何解析等信息;

对于tag值,它有field_number和wire_type两部分组成。
field_number就是在前面的message中我们给每个字段的编号。以Demo为例,UserResponse模型中,id字段的field_number就是1,phoneNumber就是2。
wire_type表示类型,是固定长度还是变长的。wire_type当前有0到5一共6个值,所以用3个bit就可以表示这6个值。tag结构如下图。
它的格式是field_number<<3 | wire_type

wire_type值如下表, 其中3和4已经废弃,我们只需要关心剩下的4种。对于Varint编码数据,不需要存储字节长度length.这种情况下,TLV编码格式退化成TV编码。对于64-bit和32-bit也不需要length,因为type值已经表明了长度是8字节还是4字节。
我们重点关注0和2两种编码方式。

2. Varint
Varint顾名思义就可变的int,是一种变长的编码方式。值越小的数字,使用越少的字节表示,通过减少表示数字的字节数从而进行数据压缩。对于int32类型的数字,一般需要4个字节表示,但是采用Varint编码,对于小于128的int32类型的数字,用1个字节来表示。对于很大的数字可能需要5个字节来表示,但是在大多数情况下,消息中一般不会有很大的数字,所以采用Varint编码可以用更少的字节数来表示数字。
Varint是变长编码,那它是怎么区分出各个字段的呢?也就是怎么识别出这个数字是1个字节还是2个字节的呢?Varint通过每个字节的最高位来标识当前字节是否是当前整数的最后一个字节,称为最高有效位(most significant bit, msb)。msb 为 1 时,代表着后面还有数据;msb 为 0 时代表着当前字节是当前整数的最后一个字节。字节剩余的低7位都用来表示数字。虽然这样每个字节会浪费掉1bit空间,也就是1/8=12.5%的浪费,但是如果有很多数字不用固定的4字节,还是能节省不少空间。
下面通过一个例子来详细学习编码方法,我们在Demo里面返回了一个电话号码,固定为180,就以它为例讲解。
需要说明的是,Protobuf采用的是小端模式(Little-endian),是指数据的高字节位 保存在 内存的高地址中,而数据的低字节位 保存在 内存的低地址中。这种存储模式将地址的高低位和数据位有效地结合起来,高地址部分权值高,低地址部分权值低,和我们的逻辑方法一致。简言之,低位字节在前,高位字节在后。

可以看到,仅需要2个字节就可以表达180,比固定4字节节省了2个字节。当然,由于牺牲了1个位,如果数值大于2^28,那么就需要5个字节,反而多了一个字节。因此需要评估是否会大概率出现这种情况。
在这个例子中,电话号码field_number是2,wire_type是0,所以根据field_number<<3 | wire_type,该字段最后变成00010000 10110100 00000001(后面会验证)
负数的编码需要通过ZigZag编码,较为复杂,感兴趣的同学可以查阅:https://www.cnblogs.com/en-heng/p/5570609.html
3. Length-delimited
这种类型是典型的TLV格式,T和上面的一样,L采用varint的编码方式,V是具体的值。
验证一下L采用varint编码方式,假设传入的id大于128(保证有多个字节),输入130个a.
根据上面varint的分析,不难得出L编码是:10000010 00000001。
V采用UTF-8编码,a对应的值是97,转换成二进制为01100001,所以一共是130个01100001。
T根据field_number<<3 | wire_type,其中field_number是1,wire_type是2,即00001010.
因此,该字段最后变成00001010 10000010 00000001 130个01100001 (后面会验证)
3.4 通信内容抓包
接下来,我们使用Wireshark对上面提到的例子进行网络抓包,直观地感受和验证一下我们的分析是否正确。
由于HTTP/2存储的是二进制数据,并且Wireshark不知道我们的Protobuf格式,因此在操作前,需要对Wireshark做一些设置工作。可参考:wireshark支持gRPC协议 https://blog.csdn.net/luo15242208310/article/details/122909827
我们使用一元消息模式,输入130个a,服务端将返回用户的信息,包含电话号码180.

我们点开发送的请求,可以看到对应的编码如下,帧的ID是5,130个a的编码和之前分析的一样。头信息里也有对应的方法信息。


我们再来看一下响应消息。可以看到,响应的帧ID也是5。对于int32类型的phoneNumber字段,其编码也和之前分析的一样。



4.通信模式
在Demo里有这四种模式的演示。
4.1一元RPC模式
在一元 RPC 模式中,gRPC 服务器端和 gRPC 客户端的通信始终只涉及一个请求和一个响应。如下图所示,请求消息包含头信息,随后是以长度作为前缀的消息,该消息可以跨一个或多个数据帧。消息最后会添加一个 EOS 标记,方便客户端半关(half-close)连接,并标记请求消息的结束。在这里,“半关”指的是客户端在自己的一侧关闭连接,这样一来,客户端无法再向服务器端发送消息,但仍能够监听来自服务器端的消息。只有在接收到完整的消息之后,服务器端才生成响应。响应消息包含一个头信息帧,随后是以长度作为前缀的消息。当服务器端发送带有状态详情的 trailer 头信息之后,通信就会关闭。

4.2服务端流模式
从客户端的角度来说,一元 RPC 模式和服务器端流 RPC 模式具有相同的请求信息流。这两种情况都是发送一条请求消息,主要差异在于服务器端。在服务器端流 RPC 模式中,服务器端不再向客户端发送一条响应消息,而会发送多条响应消息。服务器端会持续等待,直到接收到完整的请求消息,随后它会发送响应头消息和多条以长度作为前缀的消息,如下图 所示。在服务器端发送带有状态详情的 trailer 头信息之后,通信就会关闭。

4.3客户端流模式
在客户端流 RPC 模式中,客户端向服务器端发送多条消息,服务器端在响应时发送一条消息。客户端首先通过发送头信息帧来与服务器端建立连接,然后以数据帧的形式,向服务器端发送多条以长度作为前缀的消息,如图所示。最后,通过在末尾的数据帧中发送 EOS 标记,客户端将连接设置为半关的状态。与此同时,服务器端读取所接收到的来自客户端的消息。在接收到所有的消息之后,客户端发送一条响应消息和 trailer 头信息,并关闭连接。
4.4双向流模式
在双向流 RPC 模式中,客户端通过发送头信息帧与服务器端建立连接。然后,它们会互发以长度作为前缀的消息,无须等待对方结束。如图 所示,客户端和服务器端会同时发送消息。两者都可以在自己的一侧关闭连接,这意味着它们不能再发送消息了。

重点看一下双向流模式。在服务端, 我们可以模拟接收到请求后,进行了耗时的操作,如耗时2秒后,才进行响应。
在服务端处理请求期间,客户端多次发送请求,可以发现不用等待服务端响应,就能发送新请求并被正确处理。
5.总结
gRPC 是一个高性能、开源和通用的 RPC 框架,面向移动和 HTTP/2 设计。
优点
1.性能好/效率高
· 基于 HTTP/2 标准设计,二进制编码传输速度快
· Protobuf 压缩性好,序列化和反序列化快,传输速度快
2.有代码生成机制
3.支持向后兼容和向前兼容
当客户端和服务器同时使用一个协议时,客户端在协议中增加一个字节,并不会影响客户端的使用。
4.支持多种编程语言
5.流式处理(基于http2.0):支持客户端流式,服务端流式,双向流式
缺点
1.二进制格式导致可读性差
为了提高性能,protobuf 采用了二进制格式进行编码。这直接导致了可读性差,影响开发测试时候的效率。当然,在一般情况下,protobuf 非常可靠,并不会出现太大的问题。
2.缺乏自描述
一般来说,XML 是自描述的,而 protobuf 格式则不是。它是一段二进制格式的协议内容,并且不配合写好的结构体是看不出来什么作用的。
3.通用性差
protobuf 虽然支持了大量语言的序列化和反序列化,但仍然并不是一个跨平台和语言的传输标准。在多平台消息传递中,对其他项目的兼容性并不是很好,需要做相应的适配改造工作。相比 json 和 XML,通用性还是没那么好。
引用链接:
《gRPC与云原生应用开发:以Go和Java为例》
HTTP2详解:https://juejin.cn/post/6844903667569541133
HTTP/2 头部压缩技术介绍:https://juejin.cn/post/6844903972642242574
Language Guide (proto3) | proto3 语言指南(十四)选项:https://www.cnblogs.com/itheo/p/14273574.html
Protobuf生成Java代码(命令行):https://www.jianshu.com/p/420c18851aaa
说说我理解的grpc的编码协议:https://juejin.cn/post/6993244854939549727- [ ] – [ ]
