面试官问:为啥不建议使用 Select *?请你大声地回答他!!

作者:小目标青年
来源:https://blog.csdn.net/qq_35387940/article/details/125921218
前言
不建议使用 select *
这几个字眼,做开发的都不陌生吧。
阿里的开发手册上面也是有提到:

这个完整版可以关注公众号Java核心技术,然后在公众号后台回复手册获取。
昨晚收到一个小兄弟的反馈:
随后也问了下学习群里的兄弟们,
不敢吱声的:

好像派:

离谱的:

那么,我作为一个出手侠, 我必然要出手了。
出手侠:
习惯用语,等到xxxxx的时候,我就会出手。
正文

这个完整版可以关注公众号Java核心技术,然后在公众号后台回复手册获取。其实阿里巴巴手册上说明的三点了:
1) 增加查询分析器解析成本
什么是分析器成本,什么东西,我随手画个简图,大家知道一下:
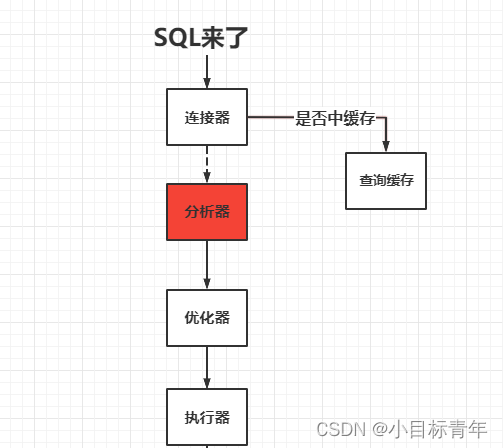
就是这个分析器,这里会去解析你的sql的语法,词法。
举例,如果是select * from user , 看到 * ,就会去看看是哪个表 user,然后 Query Table Metadata For Columns,把所有列值给你支楞出来,填充成类似 select id ,name ,age,phone form user 这样子。(当然还有其他分析了,例如如语法的判断, 字段的判断, 表名等等)
说实话。这个分析器的成本….你要是说增加了解析成本,我确实能理解。
但是我感觉成本也不是很大…. 除非是个大表,大到查询完所有列值?
so,我能接受,但是接受得不多。
2) 增减字段,容易与resultMap 配置不一致
这一点我不想说。说实在的,有时候写select *(需要查表所有列值的时候), 我实体加了字段,我改了resultMap ,我sql还不用动。
这一点属于是平时使用规范上的规避点了,不多言。
3)无用字段增加网络消耗、磁盘IO开销
这一点有讲究。
可以看到我第一点里面画的简图, 如果说
不考虑缓存 存在的时候:
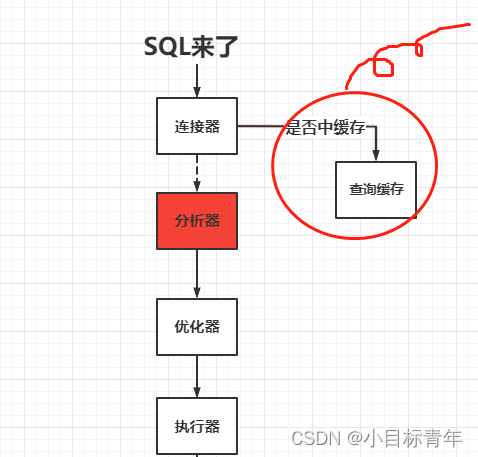
最终会走到执行器,然后执行器后面其实是引擎层
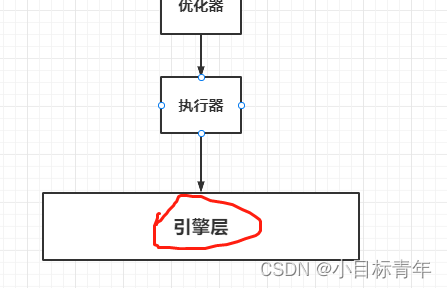
引擎层这里我就不展开了,引擎层里面其实包括了各种日志(undo、redo、binlog等)的记录,还有就是在内存里找数据。
简单点归纳,其实这种查询操作就是刷盘操作,从磁盘刷入内存,涉及到的 磁盘IO开销。
那么在刷盘操作的时候,是不是真的selec * 就真的会 增加 磁盘IO开销呢?
答案,肯定是的。但是 增大的影响程度,我必须说一下:
如果你说 ,表里面就三字段 , id ,name ,age ,本来查 id ,name ;因为 select * ,变成查多了一个 age , 增大磁盘IO开销 ?
我觉得是增大了,但是几乎不用理。因为这些都是正常的数据类型,开销增大不了多少。
所以,真正隐藏的雷是什么?
有大字段
例如
tinytext、text、mediumtext、longtext
tinybob、blob、mediumblob、longblob
这些家伙,在mysql上,就是当做一个独立的对象处理。
这时候就真的要谨慎了。
如果你是个比较多字段的表,例如什么意见反馈表,留言不确定长度,用了text ,还有回复留言字段也用了text ;
又例如博客文本表,为了存content,用了这些大字段。
本来想查询一下 意见的反馈人名 ,或者是 查询博客的标题,结果因为懒或者不注意,写了select *., 查询的时候带出来这些 大字段。
那么显然,这时候读取的内容数据就是真的比原先初衷要大很多(没准业主小丹投诉保安,意见反馈的留言给你写了篇小论文), 这时候因为读取的内容多,磁盘IO开销多,然后返回数据包给客户端量也多, 这样 就真的是有影响了。
4) 补充,其实也是我首当其冲想说的一点
无法使用索引覆盖
ps:今天学习成语了吗?不要乱用成语。
select * 基本告别索引覆盖了
什么是索引覆盖?
举例 :
给name字段 建索引, 查询的时候,只用到了 索引的字段,这就是索引覆盖 。
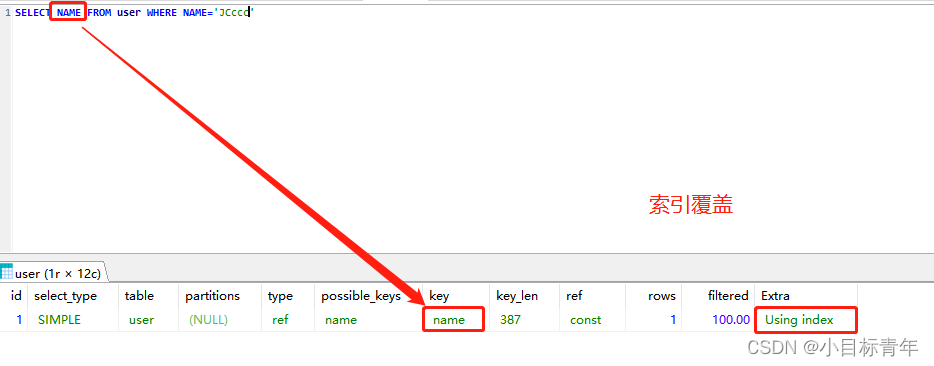
也就是直接通过查询索引,拿出来的数据就已经满足了查询返回的字段数据。无需额外其他查询操作了,也就是索引覆盖了。这样肯定快。
如果初衷是查 name, 结果写成了 select * , 变成查多了其他字段, 那其他字段不是索引,肯定无法触发索引覆盖使用场景了,也就是需要额外的回表查询操作了,那这样就慢了。
回归正题,因为写成select * ,变成查多了其他字段, 其他字段不是索引,导致回表,慢。
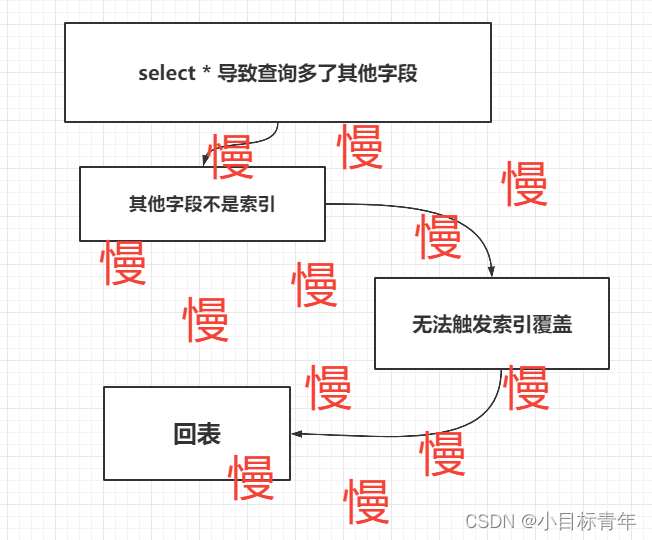
问题出在哪里? 出在其他字段不是索引?
那么给其他字段都建索引呗,完事了兄弟们。
你们千万不要这么乱搞,索引的维护成本一定是不能忽视的。
涉及到修改新增删除数据时索引的维护成本,索引页的分裂合并等等。索引也是需要存起来的,也是需要占用磁盘空间的。而且如果N个字段都是索引, 随便改动一行数据,需要维护N个索引。
什么概念,就像咱们平时写word文档,搞了个目录,然后底下的2级标题,3级标题,正文啥的,什么分页啥的,乱七八糟操作的编辑,都需要去刷新一下目录。
那么这个索引覆盖影响真的非常大吗?
拿出200W数据的表,删除全部索引,给 platform_sn 单独加索引 :

然后先试试索引覆盖的查询,看看用时,0.02秒 :
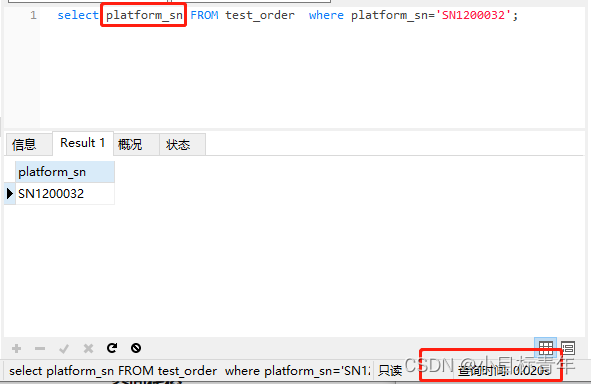
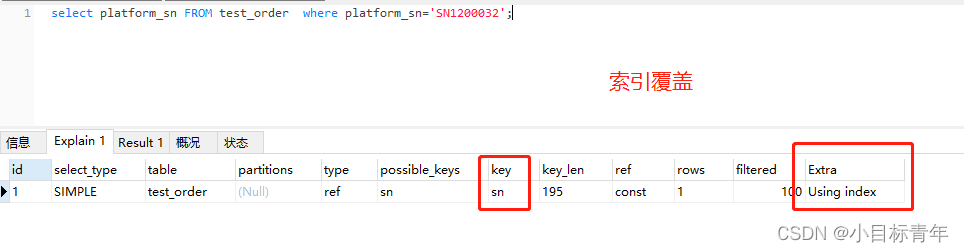
接着换成select * :
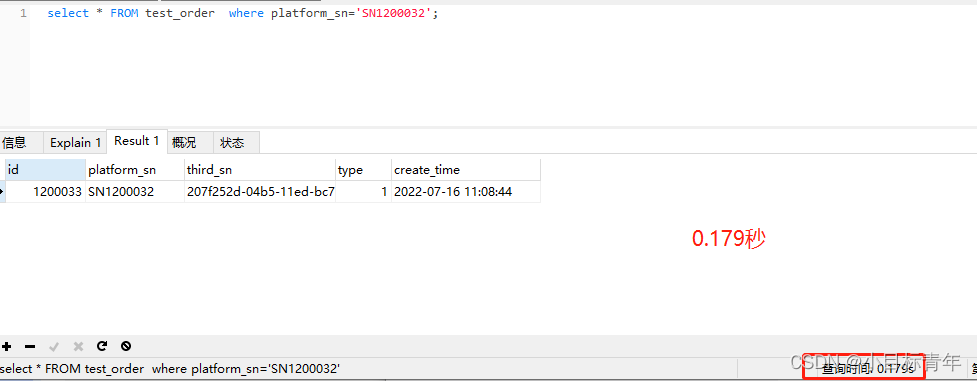
当然这是 200W 数据的场景下, 不过可以看出,时间差距还是很明显。
0.02 到 0.179 ….
如果我们再加几个大字段?Text … 那估计就真的离谱了 。
客观总结:
- 如果表里有大字段,TEXT 、BLOB系列类型字段, 使用
SELECT *需要注意 - 如果本来只查询某1,2个比较常用的字段的,可以给这些字段建单个索引或者组合索引 ,这时候查询就避免 使用
SELECT *,尽量能触发索引覆盖是最好的了 - 如果表字段不多,也没啥特殊字段类型, 而且肯定是查多列的,无法触发索引覆盖的情况下,
我觉得 使用 SELECT * 也无妨,或者写个<select cloum> 里面列出所有字段,这样copy代码也方便(因为会存在一种情况就是,数据库里面有这个字段,但是不能查出来,这种情况select * 就是不如写成select <select cloum>这种方式方便了,只需要在<select cloum> 提除某个字段就 可以)。
近期热文推荐:
1.1,000+ 道 Java面试题及答案整理(2022最新版)
2.劲爆!Java 协程要来了。。。
3.Spring Boot 2.x 教程,太全了!
4.别再写满屏的爆爆爆炸类了,试试装饰器模式,这才是优雅的方式!!
5.《Java开发手册(嵩山版)》最新发布,速速下载!
觉得不错,别忘了随手点赞+转发哦!